

前言
排序算法可以说是被考的最多的算法系列了,也是面试中最常被问到的算法之一。结合着之前自己学习数据结构课程的笔记,以及看过浙大的数据结构课程 ,下面给出一些排序算法的伪码或者是自己写的JavaScript版本。
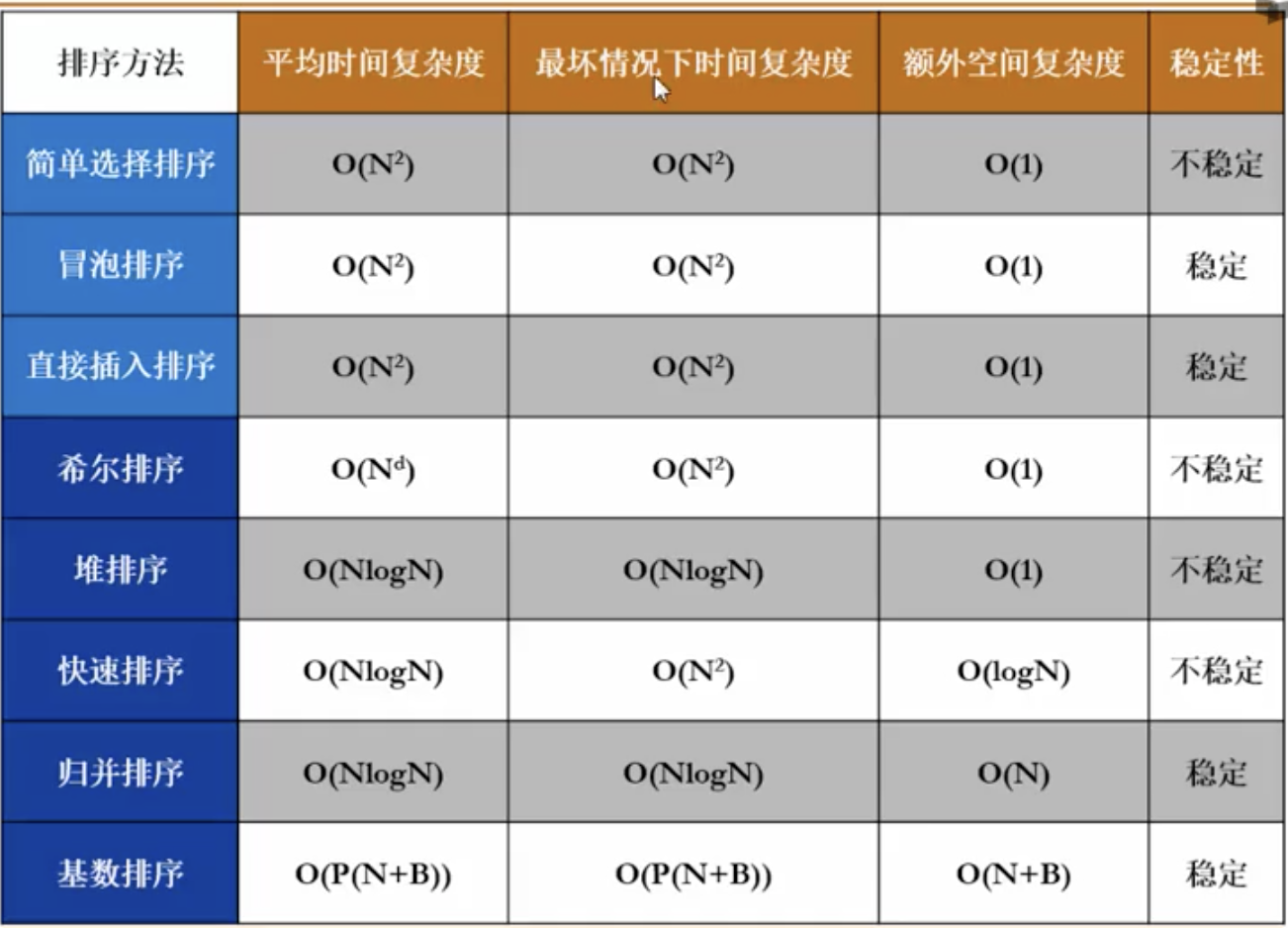
排序算法的比较
一、选择排序
选择排序可以说是最好理解的排序了,就是每次从未排数组里找到一个最小的数与数组第一个数做交换即可
时空复杂度分析
- 额外空间复杂度:
。因为只需要一个临时变量存最小的数
- 时间复杂度:
- 比较复杂度:
。第一次需要(n-1)次比较…第N次需要0次比较,一共**
**次
- 交换复杂度:
- 最坏情况:每次都需要交换,一共交换
次
- 最好情况:已排好序,每次无需交换,
次
- 平均情况:
次
- 最坏情况:每次都需要交换,一共交换
- 比较复杂度:
// JavaScript版本
const selectionSort = (arr) => {
for (let i = 0; i < arr.length; i++) {
let minPos = i;
for (let j = 1 + i; j < arr.length; j++) {
minPos = arr[minPos] <= arr[j] ? minPos : j;
}
swap(arr, i, minPos);
}
}
const swap = (arr, a, b) => {
let temp = arr[a];
arr[a] = arr[b];
arr[b] = temp;
}
二、插入排序
插入排序则类似于我们玩扑克牌游戏时,抽到一张牌,从后往前比较,找到合适位置进行插入
时空复杂度分析
- 额外空间复杂度:
- 时间复杂度:
- 比较复杂度:
- 最坏情况:每次都要比较到第一个元素,第一次比较1次,第N-1次比较N-1次,一共
次
- 最好情况:完全排好序,每次只需与前一个元素比较,一共比较
- 平均情况:每次平均比较到中间位置,一共
次
- 最坏情况:每次都要比较到第一个元素,第一次比较1次,第N-1次比较N-1次,一共
- 交换复杂度:
- 最坏情况:每次比较完都需要交换,一共
- 最好情况:完全排好序,交换
- 平均情况:每次比较到中间进行交换,一共
- 最坏情况:每次比较完都需要交换,一共
- 比较复杂度:
const insertionSort = (arr) => {
for (let i = 1; i < arr.length; i++) {
let j = i - 1;
if(arr[i] >= arr[j]) {
continue;
}
while (arr[i] < arr[j]) {
j--;
if (j < 0) break;
}
let temp = arr[i];
let tempPos = i;
while(tempPos!==j+1) {
arr[tempPos] = arr[tempPos-1];
tempPos--;
}
arr[j+1] = temp;
}
}
扩展:插入排序和选择排序的比较
让我们再来看看插排和选排的时间复杂度,相信大多数人考虑到的都是比较复杂度作为其总体复杂度。我开始就只考虑这个,但是交换复杂度确实也是存在的,分析起来,还有那么点意思。
选择排序
- 时间复杂度:
- 比较复杂度:
- 交换复杂度:
- 最坏情况:每次都需要交换,一共交换
- 最好情况:已排好序,每次无需交换,
- 平均情况:
- 最坏情况:每次都需要交换,一共交换
- 比较复杂度:
插入排序
- 时间复杂度:
- 比较复杂度:
- 最坏情况:每次都要比较到第一个元素,第一次比较1次,第N-1次比较N-1次,一共
- 最好情况:完全排好序,每次只需与前一个元素比较,一共比较
- 平均情况:每次平均比较到中间位置,一共
- 最坏情况:每次都要比较到第一个元素,第一次比较1次,第N-1次比较N-1次,一共
- 交换复杂度:
- 最坏情况:每次比较完都需要交换,一共
- 最好情况:完全排好序,交换
- 平均情况:每次比较到中间进行交换,一共
- 最坏情况:每次比较完都需要交换,一共
- 比较复杂度:
复杂度的几种情况
虽然上面提到了平均情况,但是我们在考虑一个算法时,往往需要考虑其边界,也就是考虑其最坏情况,这样有助于我们对其性能的分析,因此下面以最坏情况进行一个分析
仔细看的话,会发现对于比较复杂度,选排是固定的,为****次,而插排最坏达到
次;而对于交换复杂度,选排最坏
次,插排最坏
次。其实单单从N的量级上来看,选排似乎更优,但真的是这样吗?
算法导论上提到一个排序算法的性能依赖于以下因素
- 待排项数
- 这些项已排序程度
- 项值的限制
- 计算机体系结构
- 使用的存储设备种类(主存,磁盘或磁带)
我们假设对比基于同一计算机体系结构,存储设备也一样,项值无限制。只要制约因素为待排项数和已排序程度
对于已排序程度来说,如果排序程度较大,比较复杂度中插排很难达到最坏情况,此时其实比较次数是很少的;如果N很大时,差异也将显著增大,而插排的交换复杂度是和比较复杂度呈正相关的,此时插排的交换复杂度也会降低。这样来说插排还是由于选排的,因为选排时间复杂度固定,而插排会随着排序程度发生变化
查了一些资料,里面都提到上面这种说法,但是却没有对交换开销和比较开销做一个深层次的剖析,直到我在知乎上看到这位答主的一个深层次解析
其实我们没怎么考虑交换,是因为交换开销确实没有比较开销大,交换一般直接交换内存地址而不是直接交换真实的数据,而比较则需要CPU的一些运算。上面答主便给出了自定义赋值函数,如果直接交换数据,增大开销之后,当数据量过大,插入排序反而不如选择排序,因为其交换次数平均情况下和选择排序仍然不是一个量级
其实我在quora上还看到一个有趣的回答,什么时候该避免使用插入排序呢?
插入排序交换次数多,交换需要写内存,所以使用Flash Memory时,应该减少写操作,因为Flash Memory的擦除次数有限,也就是重新写入次数有限。所以应该避免在Flash Memory上使用插入排序
参考
三、冒泡排序
冒泡排序也比较好理解,这里为了形象比喻,数组的从前往后相当于大海的由浅至深
从后往前比较,如果该数比前一个数小,就交换,否则不换,下一个数又和再下一个数继续比较,小数(小泡泡)往前(往上冒),一轮下来,最小的泡泡已经冒到最顶上了
下面使用的是改进的冒泡,也就是说如果一轮比较下来,没有发生一次交换,说明所有泡泡都在自己正确的位置上,也就是排序已完成,无需再进行下一轮冒泡了
const bubbleSort = (arr) => {
let flag = false; // 一趟排序下来是否存在至少一次交换
for(let i=0; i<arr.length; i++) {
for(let j=0; j<arr.length-1-i; j++) {
if(arr[j]>arr[j+1]) {
swap(arr, j, j+1);
flag = true;
}
}
if(!flag) break;
}
}
const swap = (arr, a, b) => {
let temp = arr[a];
arr[a] = arr[b];
arr[b] = temp;
}
四、归并排序
递归排序使用的是分治思想
首先是分的过程,将其分成左右两个部分,分别递归(这叫做归)
最后是治的过程,将左右两个部分合并(这叫做并)
归并需要额外的空间复杂度,因为我们需要临时存放归并好的部分,存放完成之后还要将其覆盖原数组的相同位置,因此需要额外的空间
对于时间复杂度而言,归并的复杂度等于递归左边的复杂度加上递归右边的复杂度,最后加上合并的复杂度,由于合并时N个元素都需要进行比较,所以也可以用递推方程组求解
这种递推公式可以用数学递推求解得到****
归并时需要知道待归并左部分起始位置和右半部分结束位置
const mergeSort = (arr, tempArr, leftBegin, rightEnd) => {
if (leftBegin >= rightEnd) {
return;
}
let center = Math.floor((leftBegin + rightEnd) / 2);
mergeSort(arr, tempArr, leftBegin, center);
mergeSort(arr, tempArr, center + 1, rightEnd);
combine(arr, tempArr, leftBegin, rightEnd);
}
const combine = (arr, tempArr, leftBegin, rightEnd) => {
let center = Math.floor((leftBegin + rightEnd) / 2);
let i = leftBegin;
let j = center + 1;
let pos = leftBegin;
while (i !== center + 1 && j !== rightEnd + 1) {
arr[i] <= arr[j] ? tempArr[pos++] = arr[i++] : tempArr[pos++] = arr[j++];
}
// 归并右边剩下的
while (j !== rightEnd + 1) {
tempArr[pos++] = arr[j++];
}
// 归并左边剩下的
while (i !== center + 1) {
tempArr[pos++] = arr[i++];
}
// 转移到原数组
while(leftBegin!==rightEnd+1) {
arr[leftBegin] = tempArr[leftBegin];
leftBegin++;
}
}
五、快速排序
快速排序分为3个过程
- 寻找主元(我这里直接使用中间数法,即取待排数组的前中后元素的中位数)
- 将主元交换到正确的位置上
- 递归排序主元的左半部分和右半部分
快速排序快在哪儿
我们算法导论课的老师曾说过
快速排序快就快在"不捣腾内存"
我最初理解的捣腾内存,是只包括交换操作的,直到对选择排序和插入排序进行系统分析,才认为这里的捣腾内存还应该包括比较操作
最开始理解快排的快,是因为其主元排好之后位置就不会再改变了,当时与插入排序作比较,因为插入排序插入了一个元素,可能其位置后面还会发生改变。这样的话,选择排序位置一旦选好也不变啊?其实关键点在于快排的主元选取逻辑
主元的选取
要知道,快排并不是所有情况下都快的,想要快,主元要选得好
在对于快速排序时间复杂度的分析上,我直接给出递推公式,不再详细分析其比较和交换复杂度,分析起来与选择排序和插入排序类似
如果我们每次选取的主元能够对待排序列进行一个二分,则有
这种递推公式可以用数学递推求解得到****
那么,假设最糟糕的情况,我们每次选取的主元都是当前序列最大值(或最小值),无法进行二分,则有
同样,使用数学递推可求解
其实这种情况,可以理解为和选择排序一样,只不过选择排序是我们有意选择一个最小数,而这种排序则是我们无意中选到了最大数(或最小数),但是我们却还做了很多无用的比较,快排要避免这种情况
主元的选取上,由于我看的浙大MOOC上提到的是Median of Three的方法,所以我最开始以为这就是默认的,这种方法其实很难造成最糟糕情况,也是我们常用的方法
还有两种方法
- 直接选取第一个元素,这是最差劲的方法,特别是待排序列有序程度高的情况下,这种方法最容易造成最糟糕复杂度情况,因为第一个元素很可能是最小(或者最大)的元素
- 随机数法,这种方法也比较常见,而且也不容易造成最糟糕情况
主元选择逻辑对算法额外的性能影响
- 随机数法生成随机数的开销
- Median of Three中增加了比较次数(前中后三个元素进行比较)
下面的代码我使用Median of Three,同时为了提高性能,在Median Three中不仅仅选出中位数,而且对前中后三个数基于大小交换了位置,最后,将中位数放到最后一个数的前一个(也就是倒数第二个),方便比较
JavaScript版本
const quickSort = (arr, left, right) => {
if(left >= right) {
return; // 边界考虑1
}
let pivot = medianThree(arr, left, right);
if(!pivot) return; // 边界考虑2
let i = left;
let j = right - 1;
for (; ;) {
while (arr[++i] < pivot) { continue };
while (arr[--j] > pivot) { continue };
if (i < j) {
swap(arr, i, j);
} else {
break;
}
}
swap(arr, i, right - 1);
quickSort(arr, left, i - 1);
quickSort(arr, i + 1, right);
}
const medianThree = (arr, left, right) => {
if(left+1 === right) {
if(arr[left] > arr[right]) {
swap(arr, left, right);
}
return;
}
let center = Math.round((left + right) / 2);
if (arr[left] > arr[center]) {
swap(arr, left, center);
}
if (arr[left] > arr[right]) {
swap(arr, left, right);
}
if (arr[center] > arr[right]) {
swap(arr, center, right);
}
swap(arr, center, right - 1);
return arr[right - 1];
}
const swap = (arr, a, b) => {
let temp = arr[a];
arr[a] = arr[b];
arr[b] = temp;
}
