

到底应该怎么选口红色号?
引言
相信对很多男生来说,选口红色号应该是最最最难的事了,明明看着都是一样的颜色....但是问题就是用来解决的!仔细观察了一下京东评论页面,发现每一条评论下都标有评论者购买的色号,因此将这个信息做为抓取内容,统计并可视化哪种色号被购买的最多。
本文以香奈儿(Chanel )炫亮魅力唇膏丝绒系列为爬取对象。
相关模块
selenium:爬取动态网页并自动翻页
bs4:解析HTML文件
pandas:读取和存储csv文件
jieba:中文分词
collections:统计词频
pyecharts:可视化数据
可视化
各色号的购买人数可视化结果如下。
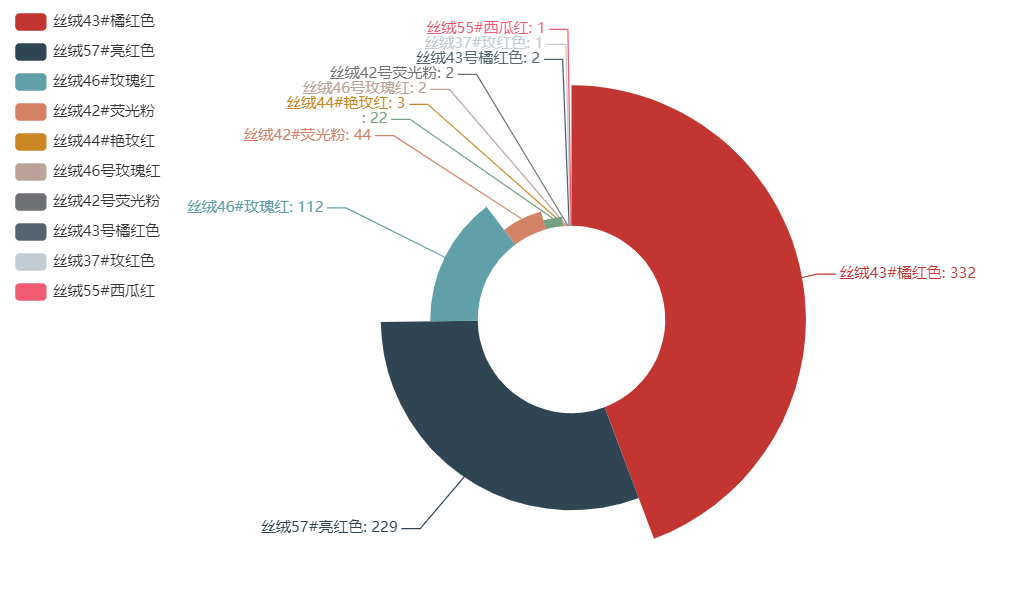
再来可视化一下评论内容。

数据爬取
首先查看了一下网页源代码,发现没有评论内容,因此判断该网页是一个动态加载的网页,常用的requests和scrapy爬虫都无法爬取其中内容。所以我选择了之前使用过的selenium库作为爬取工具。
接着分析一下网页结构。位置很明显,而且大多数京东评论网页的结构都是这样的。
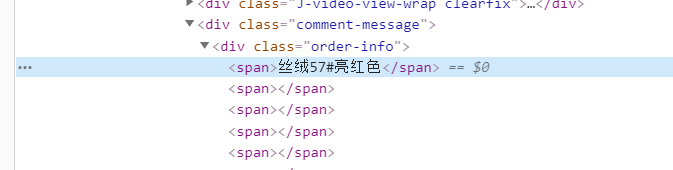
然后就可以开始抓取这部分信息了。简单的bs4库解析HTML文件,抓取到信息后存储在列表中。

下一步就是自动翻页,毕竟不能只爬十条评论信息。selenium是一个模拟浏览器的库,因此实现自动翻页也是很方便的。

在实现抓取内容和自动翻页两个功能后,加入循环,确定一下自己要爬取多少页内容就可以了。
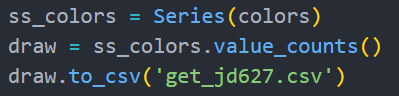
最后将爬取的结果转为Series类型的数据并写入csv文件,方便之后可视化。
既然到了已经在爬取评论信息了,所以也一并爬取一下评论内容,😏具体流程和上面的一样,但是最后写入了txt文件,方便之后的分词处理和可视化为词云。
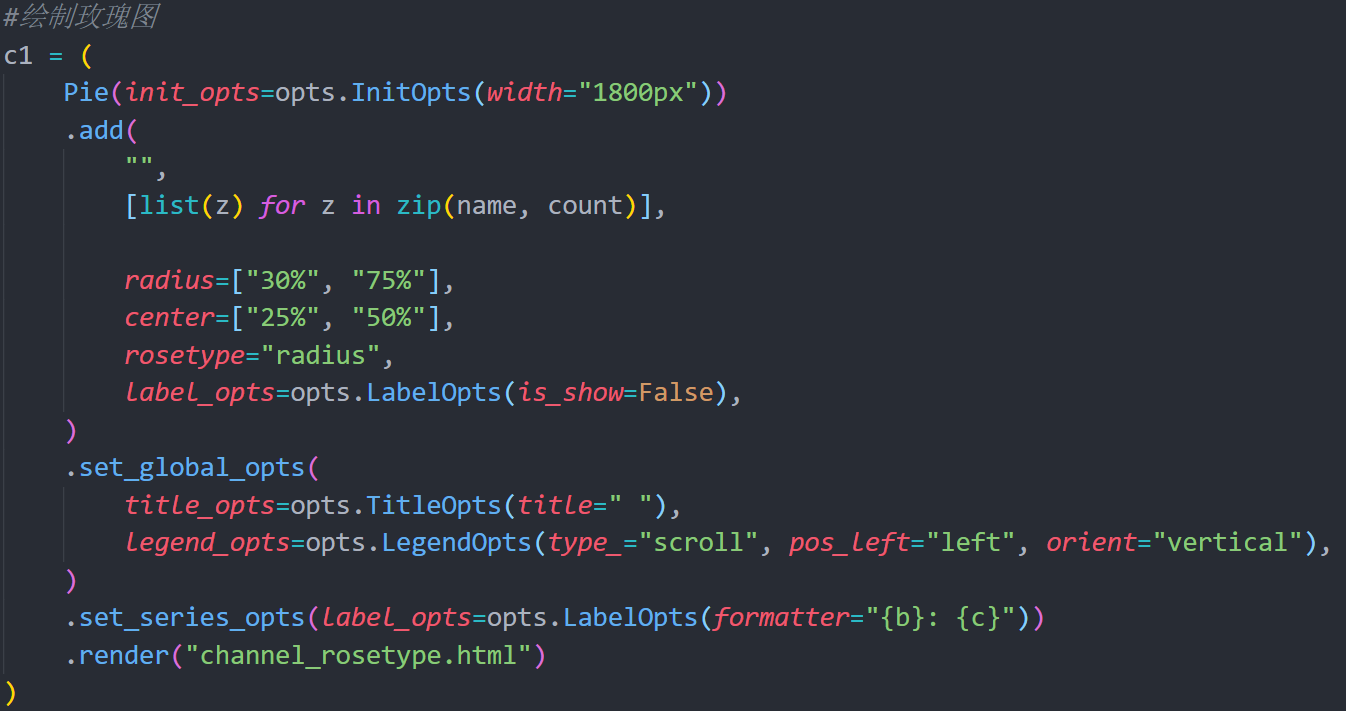
得到数据后,就可以开始可视化了,可视化我选择了选择非常火的pyecharts库,确实是功能强大,可操作性很强。由于这组数据数量上相差比较悬殊,因此只画了玫瑰图看看。放上可视化代码,强烈建议实战之前看一下官网文档,Demo写得很详细。
可视化完色号信息后,再绘制一下评论区内容的词云图。
首先是去掉文本内容中的标点符号,使用re库中的sub函数很容易的实现这一功能。

然后使用jieba库分词,再统计词频。注意:pyecharts绘制词云时,输入的应该是(词,词频)的元组形式。
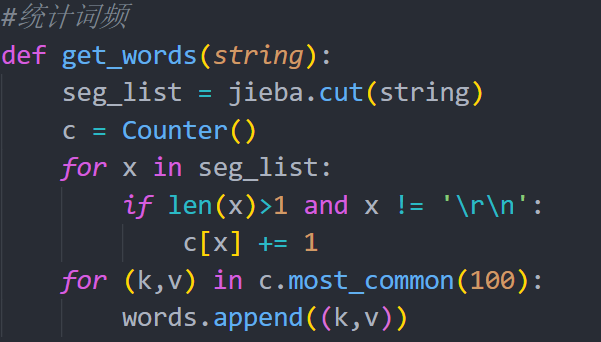
最后用得到的元组列表绘制词云。

最后
如果觉得本文还可以,还请各位点个赞。
