

Java
动态代理
动态代理是一种方便运行时动态构建代理、动态处理代理方法调用的机制,
应用场景:很多场景都是利用类似机制做到的,比如用来包装 RPC 调用、面向切面的编程(AOP)。
实现动态代理的方式:方式很多,比如 JDK 自身提供的动态代理,主要利用了反射机制。 举例,常可采用的JDK提供的动态代理接口InvocationHandler来实现动态代理类。其中invoke方法是该接口定义必须实现的,它完成对真实方法的调用。 InvocationHandler的工作是响应代理的任何调用,可被看作代理收到方法调用后,请求做实际工作的对象。 通过InvocationHandler接口,所有方法都由该Handler来进行处理,即所有被代理的方法都由InvocationHandler接管实际的处理任务。此外,我们常可以在invoke方法实现中增加自定义的逻辑实现,实现对被代理类的业务逻辑无侵入。
引用类型
在Java中,除了原始数据类型,之外的就是引用类型,指向不同的变量。 不同的引用类型,主要体现的是对象不同的可达性(reachable)状态和面对垃圾收集的影响。
一个对象在堆中存在,不被垃圾回收,使用时可以直接从堆中获取,比起重新初始化一个对象效率高很多。
| 引用类型 | 是否必需 | 被回收时机 | 应用场景 | 代码 |
|---|---|---|---|---|
| 强引用 | 必需 | 不会 | 日常新建对象 | Object obj = new Object() |
| 软引用 | 非必需 | 出现OOM之前(内存不足时) | 内存敏感的缓存,如图片缓存 | SoftReference<Object> sr = new SoftReference<>(obj); |
| 弱引用 | 非必需 | JVM垃圾回收时 | 内存敏感的缓存 | WeakReference<Object> sr = new WeakReference<>(obj); |
| 虚引用 | 非必需 | 任何时候 | 跟踪对象被垃圾回收的活动 | ReferenceQueue<String> queue = new ReferenceQueue<String>(); PhantomReference<String> pr = new PhantomReference<String>(new String("hello"), queue); |
为什么设计引用类型?
- 是可以让程序员通过代码的方式决定某些对象的生命周期;
- 是有利于JVM进行垃圾回收。
软引用、弱引用:尽可能地利用内存,又避免出现OOM
除了幻象引用(因为 get 永远返回 null),如果对象还没有被销毁,都可以通过 get 方法获取原有对象。
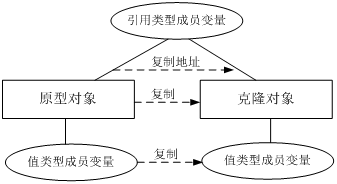
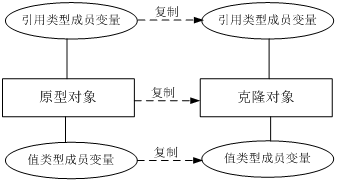
深拷贝,浅拷贝
浅克隆和深克隆的主要区别在于是否支持对象的引用类型的成员变量的复制。
为什么需要克隆对象?直接new一个对象不行吗?
答案是:克隆的对象可能包含一些已经修改过的属性,而new出来的对象的属性都还是初始化时候的值,所以当需要一个新的对象来保存当前对象的“状态”就靠clone方法了。那么我把这个对象的临时属性一个一个的赋值给我新new的对象不也行嘛?可以是可以,但是一来麻烦不说,二来,大家通过上面的源码都发现了clone是一个native方法,就是快啊,在底层实现的。
浅拷贝
深拷贝
equals() 与 == 的区别
equals()比较值 == 比较地址
Python
垃圾回收机制
python采用的是引用计数机制为主,分代回收(隔代回收) 和标记-清除两种机制为辅的策略。
引用计数是一种非常高效的内存管理手段,正是因为有引用,对象才会在内存中存在。当一个pyhton对象被引用时其引用计数增加1,当其不再被引用时引用计数减1,当引用计数等于0的时候,对象就被删除了。
从理论上说,对象的创建数目==释放数目。但是如果存在循环引用的话,肯定是创建>释放数量,当创建数与释放数量的差值达到规定的阈值的时候,当当当当~分代回收机制就登场啦。
Python根据对象的存活时间将内存划分为年轻代、中年代和老年代,分别用0,1,2表示。
分代回收是建立在标记清除技术基础之上。分代回收同样作为Python的辅助垃圾收集技术处理那些容器对象,因为对于字符串、数值对象是不可能造成循环引用问题。
在标记清除算法中有两个链表,root链表和unreachable链表。unreachable链表中的对象会被回收。
字符编码
在Python3中,字符串是以Unicode编码的。
人类使用文本,计算机使用字节序列 Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。在将字节转为字符的时候,如果编码方式不对,就会出现乱码。
ASCII、Unicode和UTF-8区别
编码方式是一种规则,与编程语言无关,在Python、Java和SQL中都是一样的。
| 编码 | 字节 | 字符 | 目的 | 使用场景 |
|---|---|---|---|---|
| ASCII | 1 | 英文字母、数字、符号 | 在计算机中表示字符 | |
| Unicode | 2+ | 所有字符 | 统一标准,解决乱码 | 计算机内存 |
| UTF-8 | 1-4 | 所有字符 | 减少编码长度,方便传输、存储 | 存储、传输 |
Unicode 字符编码标准是固定长度的字符编码方案,它包含了世界上几乎所有现用语言的字符。
UTF-8又称为可变长编码,是Unicode 的实现方式
为什么常用中文在UTF-8里需要占用3个字节,在Unicode中占用2个字节?
也就是说,UTF-8的目的是减少编码长度,那只会比Unicode短,为什么还会比它长呢?
这是由于UTF-8的编码规则决定的,由于utf-8规则天然占用字节前几位,若与Unicode同样用2字节16位表示一个中文字符,则utf-8除去规则占用,只剩余16-5=11位,无法表示Unicode下的两个字节(16位)所表示的字符。所以UTF-8使用了3个字节。
另外,UTF-8中占用3个字节的汉字,只是基本汉字,不包括所有的汉字。
UTF-8 字符的最大长度可以为 4 个字节。非补充字符的最大长度为 3 个字节,而补充字符的长度为 4 个字节。
UTF-8 的编码规则
- 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的,即UTF-8编码能够兼容ASCII。
- 对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。
| Unicode编码 | UTF-8编码 | 解释 |
|---|---|---|
| (十六进制) | (二进制) | Unicode部分为16进制编码, UTF-8编码为2进制 |
| 0000 0000-0000 007F | 0xxxxxxx | UTF-8规定,若1字符=1字节,首位须为‘0’ |
| 0000 0080-0000 07FF | 110xxxxx 10xxxxxx | UTF-8规定,若1字符=2字节,高位字节前3位为‘110’,低位前2位为‘10’ |
| 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx | UTF-8规定,若1字符=3字节,高位字节前3位为‘110’,后面低位前2位一律为‘10’。(占4,5字节字符规则以此类推) |
引用
迭代器
是什么
迭代器是访问可迭代对象的工具,典型的迭代器应用是从集合中获取元素
用途
用来依次访问可迭代对象的数据
实现方法
__next__ 返回下一个元素,如果没有元素了,抛出StopIteration异常
__iter__ 返回self,以便在使用可迭代对象的地方使用迭代器
我们应该避免直接调用特殊方法
迭代器函数(iter和next)
next(iterator) 从迭代器iterator中获取下一个元素,如果无法获取下一条记录,则触发stoptrerator异常。同__next__()
iter(iterable) 从可迭代对象中返回一个迭代器,iterable必须是能提供一个迭代器的对象。同__iter__()
可迭代对象与迭代器的关系
Python从可迭代的对象中获取迭代器
迭代器iterator
可迭代对象 iterable
生成器
所有生成器都是迭代器,因为生成器完全实现了迭代器接口。
生成器--》懒加载,比生成器立即返回整个列表节省内存
生成器表达式是制造生成器的工厂 (x for x in "abc")
缺点
- 面对复杂逻辑,可读性差
- 匿名,不可重用
Linux
管道
- 管道是半双工的,数据只能向一个方向流动,一端输入,另一端输出。需要双方通信时,需要建立起两个管道。
- 管道分为普通管道和命名管道(FIFO)。普通管道位于内存,只能用于父子进程或者兄弟进程之间(具有亲缘关系的进程)。命名管道位于文件系统,没有亲缘关系的进程间只要知道管道名也可以通讯。
- 管道是一个一页大小(4K字节)的缓冲区,即该缓冲区容量有限。
- 管道对于管道两端的进程而言,就是一个文件,但它不是普通的文件,它不属于某种文件系统,而是自立门户,单独构成一种文件系统,并且只存在于内存中。
- 数据的读出和写入:一个进程向管道中写的内容被管道另一端的进程读出。写入的内容每次都添加在管道缓冲区的末尾,并且每次都是从缓冲区的头部读出数据。
- 管道满时,写阻塞;管道空时,读阻塞。
创建
管道通过调用pipe(int fd[2])创建,经参数fd返回两个文件描述符:fd[0]为读而打开,fd[1]为写而打开。
使用
管道符合生产者—消费者模型。
用管道通信的两个进程,各持有一个文件描述符,不参与通信的进程应自觉关闭掉与管道相关的文件描述符。这么做不仅仅是为了让数据的流向更加清晰,也不仅仅是为了节省文件描述符,更重要的是,关闭未使用的管道文件描述符对管道的正确使用影响重大。
管道有如下的性质:
- 只有当所有的写入端描述符都已关闭,且管道中的数据都被读出,对读取端的描述符调用 read 函数才会返回 0,表示文件结束;
- 如果所有的读取端描述符都已关闭,此时进程往管道里面写入数据,写操作会失败;
- 当所有的读取端和写入端都关闭后,管道才能被销毁
匿名管道与命名管道的区别
- 匿名管道由pipe函数创建并打开
- 命名管道由mkfifo函数创建,打开用open
- 匿名管道只能用于有亲缘关系的进程间通信,而命名管道是任何关系的进程都能进行通信
- fifo(命名管道)与pipe(匿名管道)之间的区别在于它们的创建与打开方式不同,一旦这些工作完成后,它们的共同作用仍旧是进行进程间通信。
数据库
索引类型
- 主键索引
- 普通索引
为什么要设计普通索引?应用场景有哪些?
引申
为什么设计覆盖索引?减少回表
为什么设计联合索引?
操作系统
多进程 多线程 区别
多进程通信方式
引申
多线程通信方式
信号量,条件变量 区别
LRU,FIFO比较
优势劣势
用户态 核心态
网络
五层模型与协议
ping命令是做什么的?用到了什么协议?
检查主机之间是否连通;使用了ICMP(Internet Control Management Protocol,网际控制报文协议)和ARP协议;ICMP协议的存在就是为了更高效的转发IP数据报和提高交付成功的机会,ARP协议能根据IP地址查出计算机MAC地址。ARP是有缓存的,为了保证ARP的准确性,计算机会更新ARP缓存。
ICMP 报文是封装在 IP 包里面,它工作在网络层,是 IP 协议的助手。 ICMP报文包括差错报文类型和查询报文类型,ping命令使用的是查询报文类型,ping的一方使用回声请求(类型为8,编码为0),接受的一方回声应答请求(类型为0,编码为0)。
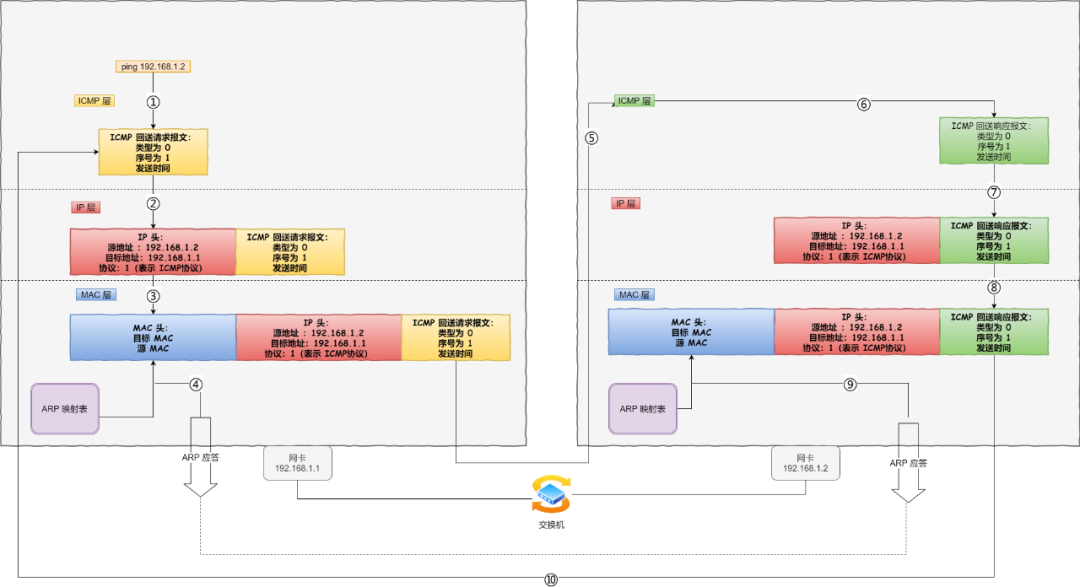
四次挥手过程
为什么是2MSL?
2MSL是客户端发送ACK到服务器和服务器端未收到ACK重发FIN到客户端的最长时间,为了确保服务器端收到客户端发送的ACK。
服务器端发送FIN至客户端之后,为什么要等客户端发来的ACK?直接断开连接不行吗?
要确保客户端能收到FIN呀(面试时没想到,脑子浆糊了)
算法题
问题
给出种子下载下来的剧集号,问最多能连续看多少集?例如:episodes = 10, 1, 3, 4, 7, 6, 20, 5, 13, 23, 14;那么最多能连续看3, 4, 5, 6, 7共5集
答案
最长连续序列问题 blog.csdn.net/whdAlive/ar…
