摘要
内大终于出成绩排名了,进了官网看了下,咦,每次都得去官网,要不把数据做出表导出来,再加个分析,说干就干
需要的库
- requests
- re
- lxml
- pandas
- matplotlib.pyplot
爬取网页数据
确定爬取url
base_url = 'https://www1.nm.zsks.cn/yz/getgsksServlet'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36 Edg/81.0.416.50"
}
确定请求方式
data={
'dwdm':'10126',
'yxsdm':'009',
'zydm':'085400',
'yjfxdm':'00',
'zsnd':'2020'
}
# 发送post请求
response = requests.post(url=self.base_url, headers=self.headers,data=data)
解析数据
xpath解析HTML
需要的内容在html页面标签table中,每个tr就是一组数据,每条信息豆子一个td中,取出所有td中的数据
html = etree.HTML(res)
# 取第一个tr标签后的所有td
data=html.xpath('//tr[1]/following::td')
xpath返回的是一个列表数据,列表中每条一个数据字典,通过遍历取出数据
for index in range(len(data)):
# data[index]返回的是一个字典
print(data[index].tag)
print(data[index].attrib)
print(data[index].text)
取出所有td中的数据并进行分组,每个tr中十个数据,将td数据按十个分组将每条数据进行处理。其中在各项分数的数据中,除总分外其他都含有字符串,为了之后的数据分析,只将数字提取出来,需要用到正则表达式进行处理
正则表达式截取字符串中所有的正数负数小数
pattern = re.compile(r'-?[0-9]+\.?[0-9]*')
re.findall(pattern,str)
把数据保存到一个全局字典方便使用
for i in range(int(len(list) / 10)):
if i != 0:
i = i * 10;
data_dict['序号'].append(list[i])
data_dict['考生编号'].append(list[i + 1])
data_dict['民族'].append(list[i + 2])
data_dict['政治'].append(int(re.findall(pattern, list[i + 3])[0]))
data_dict['外语'].append(int(re.findall(pattern, list[i + 4])[0]))
data_dict['业务课一'].append(int(re.findall(pattern, list[i + 5])[0]))
data_dict['业务课二'].append(int(re.findall(pattern, list[i + 6])[0]))
data_dict['总分'].append(int(list[i + 7]))
data_dict['报考方式'].append(list[i + 8])
data_dict['专项计划'].append(list[i + 9])
保存数据
将数据字典生成dataframe,并保存为excel
df = pd.DataFrame(data_dict)
df.to_excel('./imu.xlsx', index=None,encoding='gb18030')
进行数据分析并数据可视化
数据清洗
剔除总分以及各科未过国家线的数据
# 剔除未过国家线的
df = df.drop(index=(df.loc[(df['总分'] < 254)].index))
df = df.drop(index=(df.loc[(df['政治'] < 34)].index))
df = df.drop(index=(df.loc[(df['外语'] < 34)].index))
df = df.drop(index=(df.loc[(df['业务课一'] < 51)].index))
df = df.drop(index=(df.loc[(df['业务课二'] < 51)].index))
数据分组
将分数以每十分进行分割
df[name] = df[name].map(lambda x: int(x /10)*10)
按各项名称进行分组,并将分组后的数据重新生成dataframe,添加列名称为total
# 按name分类并重新制表
sum_df = df.groupby(name).size().reset_index(name='total')
生成图表并保存图表为图片
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
ax = sum_df.plot(x=name, y='total', kind='bar', figsize=(9, 6), fontsize=15)
ax.set_ylabel("人数")
ax.set_xlabel(name + "分数")
ax.legend().set_visible(False)
# 柱状图上显示数字
for p in ax.patches:
ax.annotate(str(p.get_height()), xy=(p.get_x() + p.get_width() / 3, p.get_height()))
# x轴数据旋转
for tick in ax.get_xticklabels():
tick.set_rotation(360)
# plt.show() 显示图像
plt.savefig(name + '.jpg')
看看结果
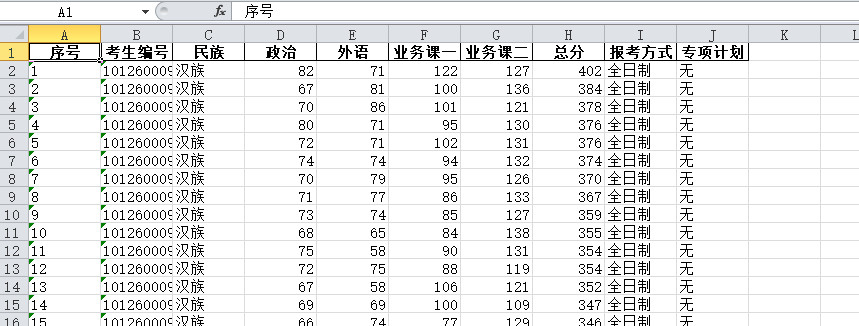
生成的excel表
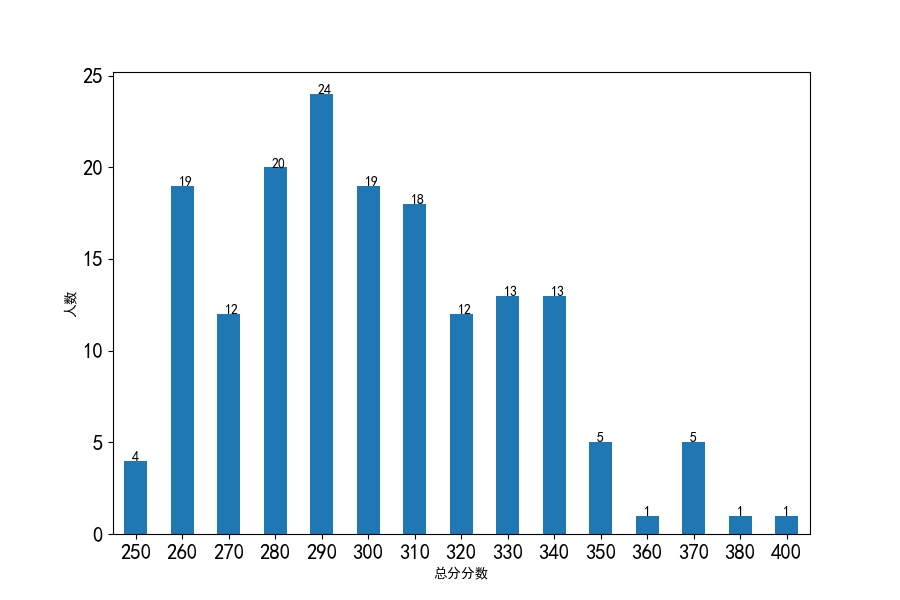
总分分数分布条形图
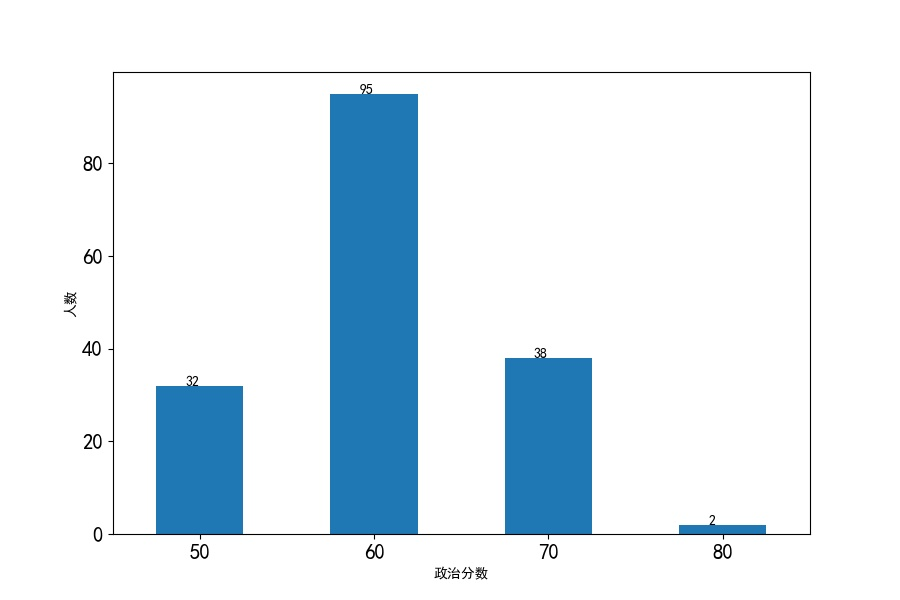
政治分数分布条形图
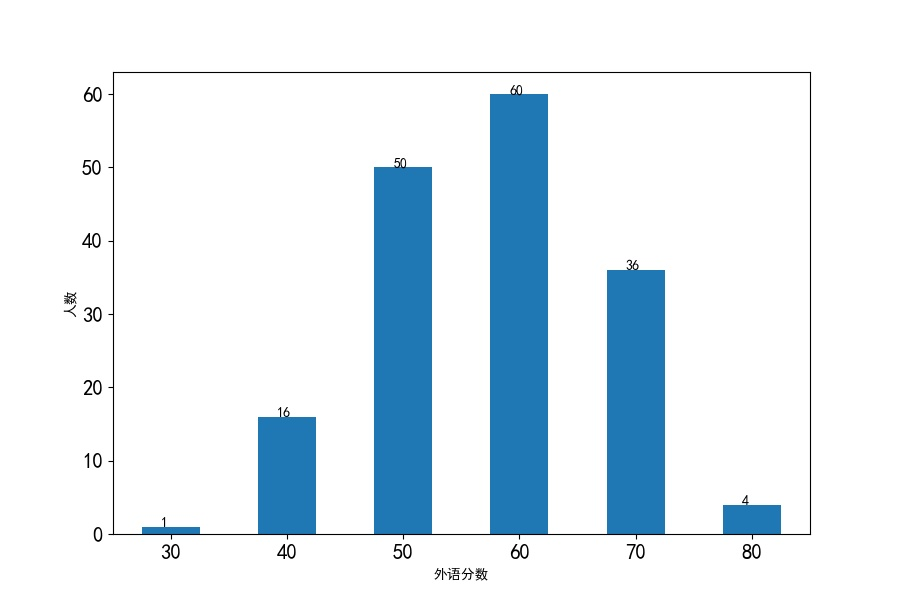
外语分数分布条形图
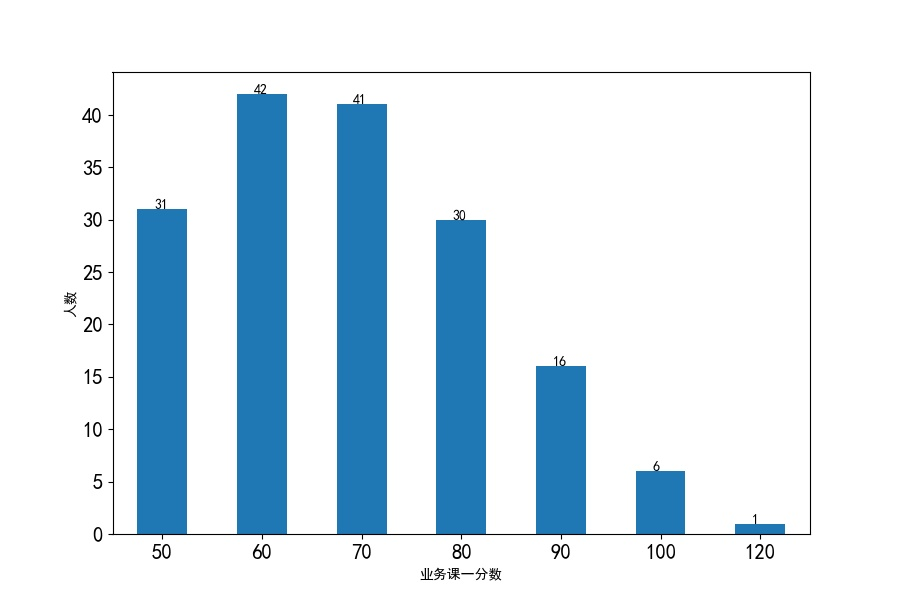
业务课一分数分布条形图
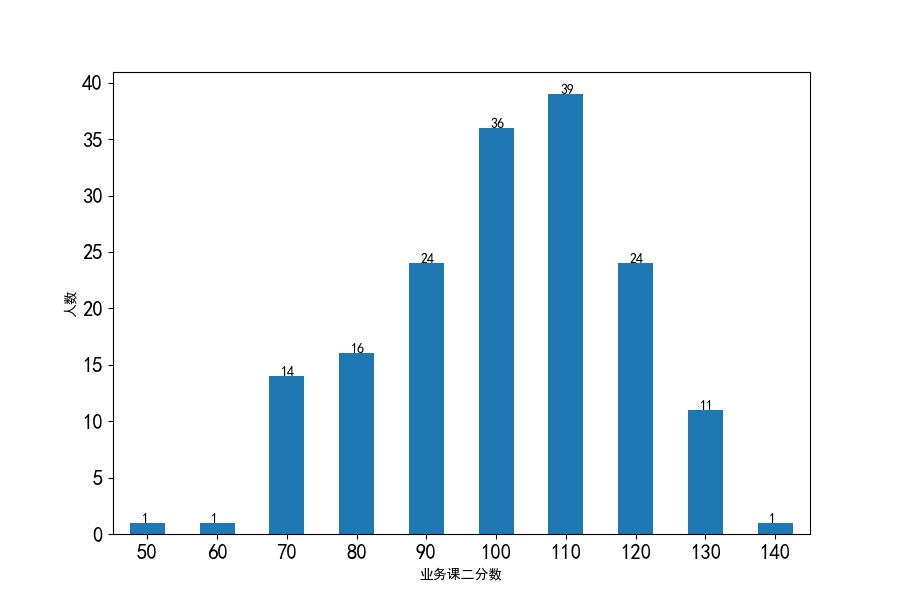
业务课二分数分布条形图