

引言
rapidminer使用了一种拖拽式的方法来帮助开发者建立数据分析、数据挖掘以及机器学习的一些模型,而不需要编写任何代码。它可将各种模块拖拽至界面上,连接配置后生成一个整体的流程,最后得到一个结果并输出。
安装
- DownLoad
- 安装完成后注册邮箱方可正常使用
界面介绍
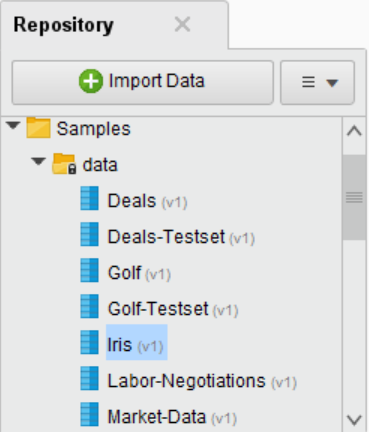
- Repository:如果之前存储过一些数据分析的流程或数据可以在该模块的Local Repository目录下找到,Samples提供了一些可使用的案例,比如说最经典的鸢尾花数据集:
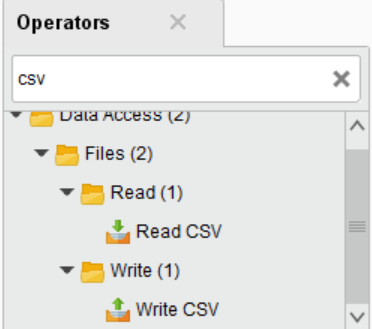
- Operators:用于模块的寻找,比如说用来衔接的Read CSV模块,可通过这个模块来引入外部数据。
- Recommended Operators:通过统计用户的使用数据,推荐在当前界面情况下大多数开发者使用过的模块

插件系统
通过点击工具栏的Extensions子目录中的Marketplace可进入商店,Top Downloads为使用最多的插件
基本操作
将iris模块托拽到操作界面,连接out和res
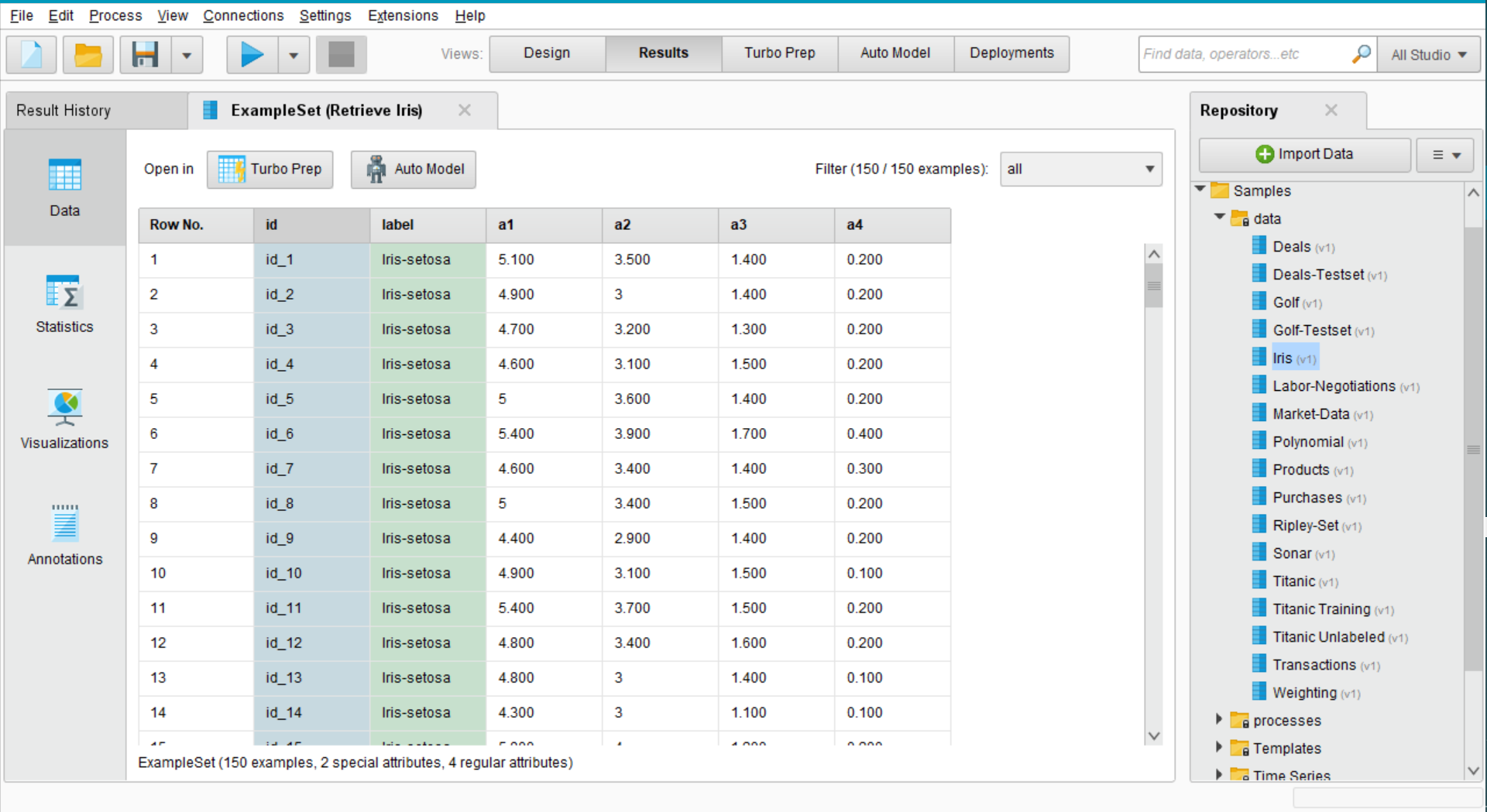
点击运行显示据集,注意到iris数据集已经事先标注好了所要用到的id和label属性
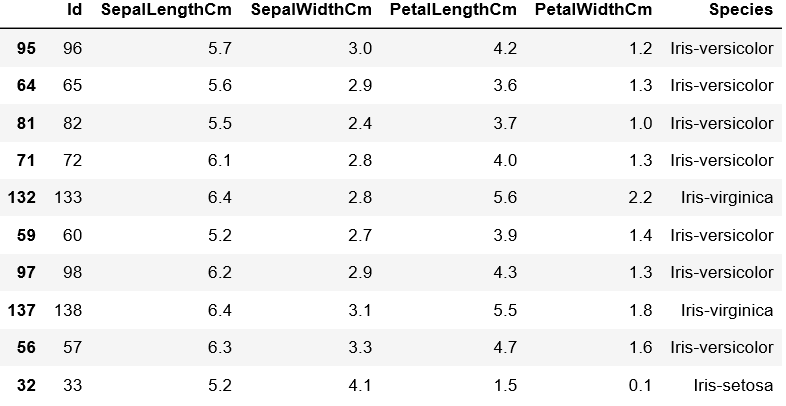
可参照下图原始数据集对比表头信息:
- 分类:
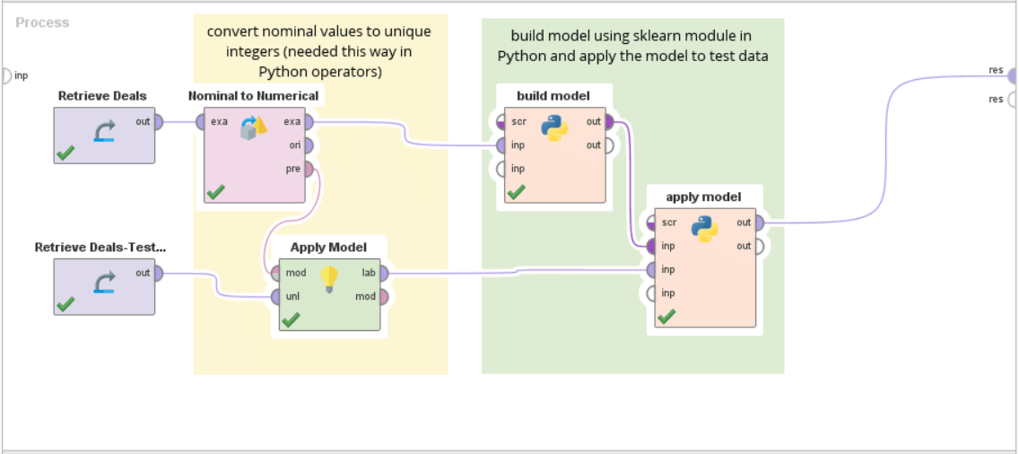
将线叉掉,加入决策树模块,连接如图所示:
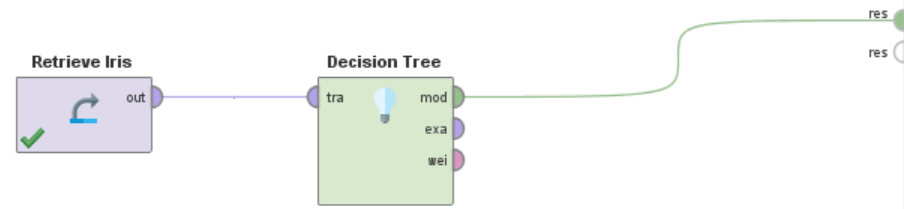
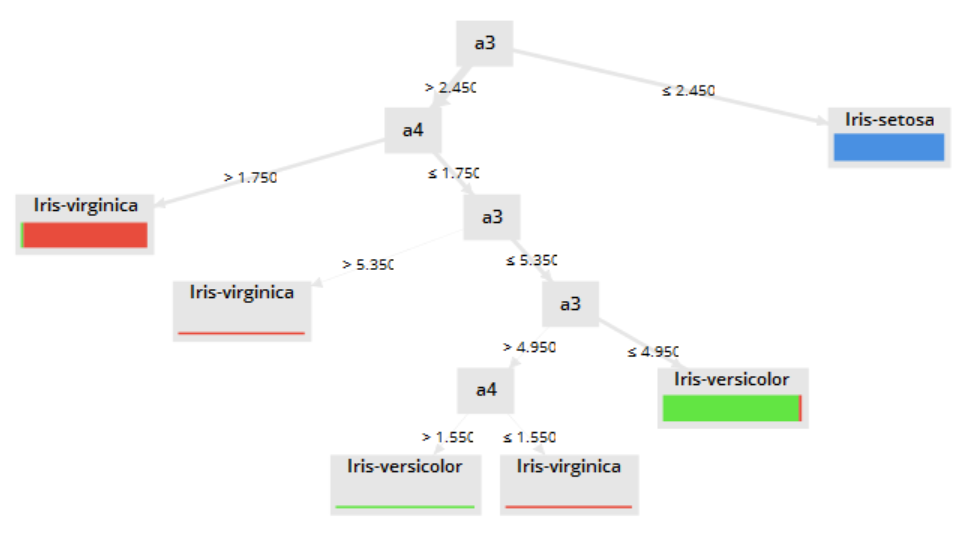
运行结果为一颗决策树:
- 预测:
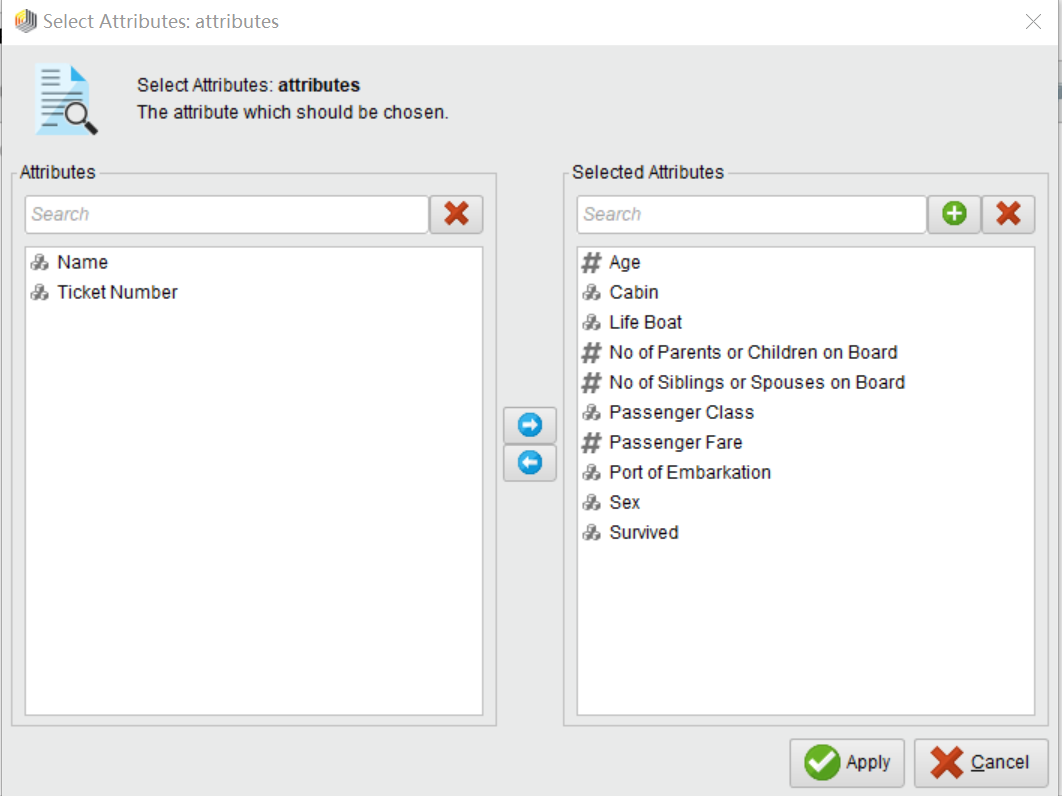
这里用到Sample下的Titanic数据集(描述了泰坦尼克号上的1309名乘客的个人信息以及船舱的位置等信息,最重要的信息是最后的Survived信息,该数据集通常用于预测乘客有没有成功逃生),由于该数据集并没有为我们标注属性,所以我们要标注关注的属性以及目标属性。通过Select Attributes模块标注我们想要的属性
设置右边Parameters模块的attribute filter type属性值为subset
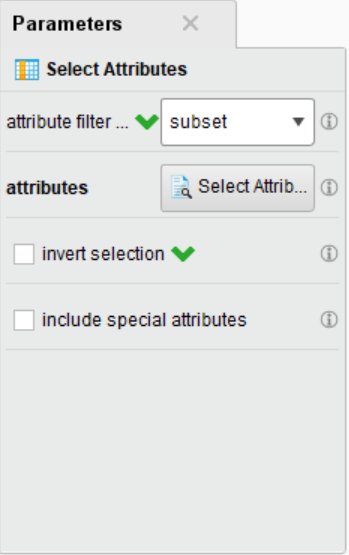
点击下边的Select Attributes按钮,进入界面,将可能与预测有关的属性加到右边
加入Set Role来指定我们的目标属性y
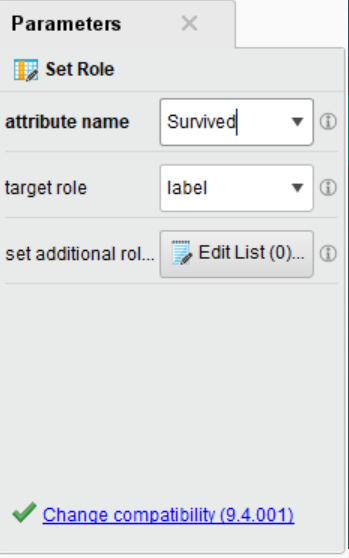
指定目标属性为Survived,并将target type设置成label
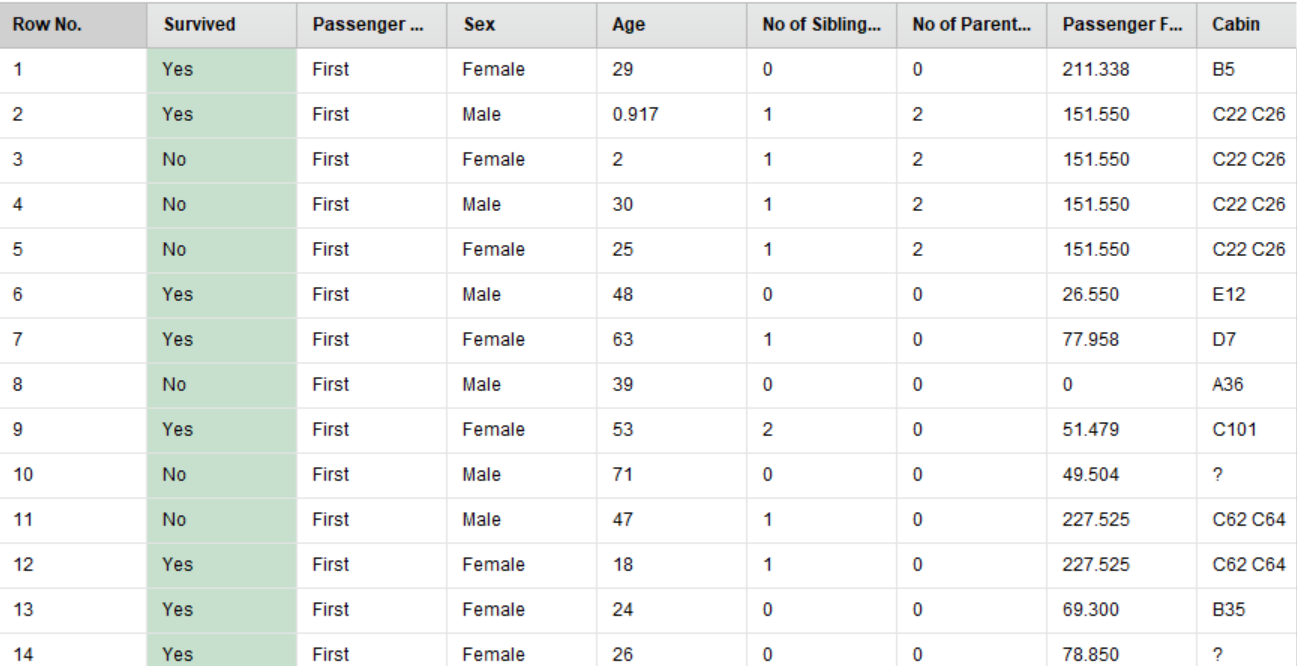
运行后Survived属性为绿色,说明是我们所要预测的属性
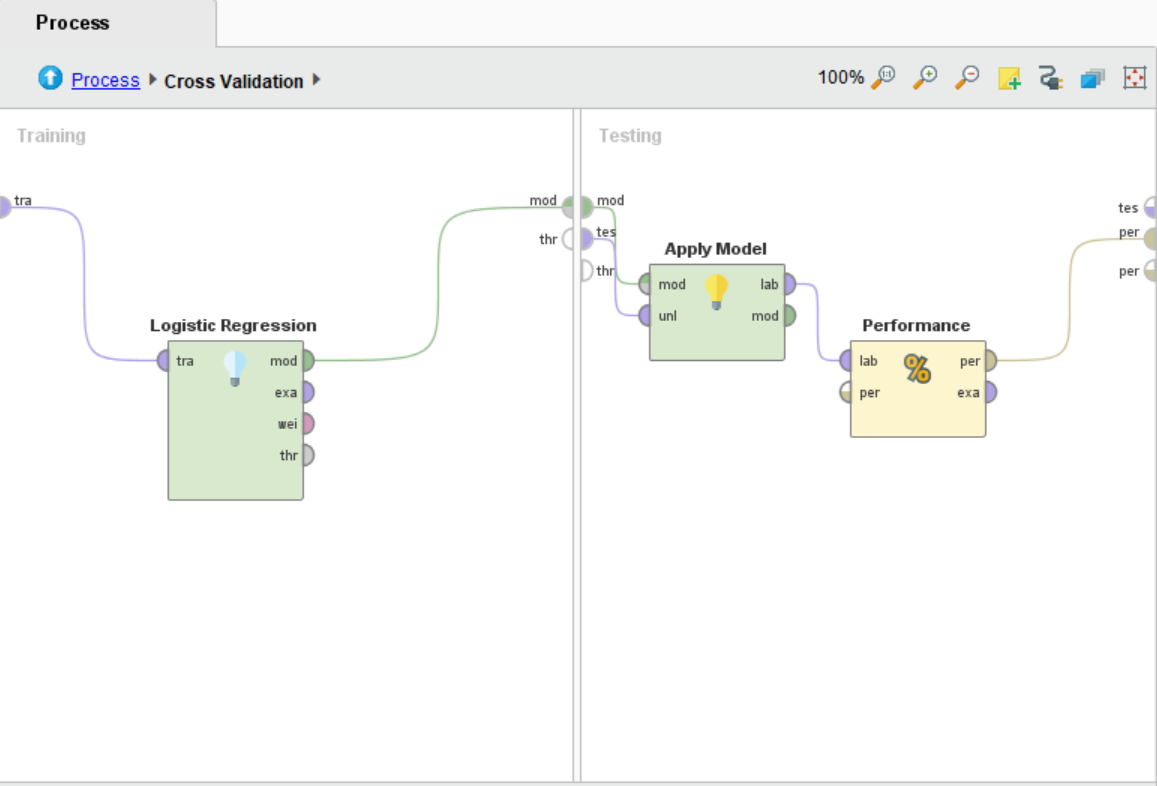
引入Cross Validation(交叉检验)模块
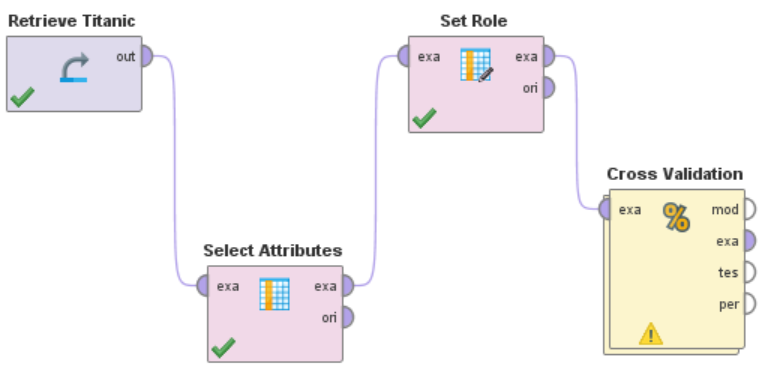
双击该模块进入内层界面,在Training框引入决策树模块,在Testing框引入Apply Model和Performance模块并进行相关连接
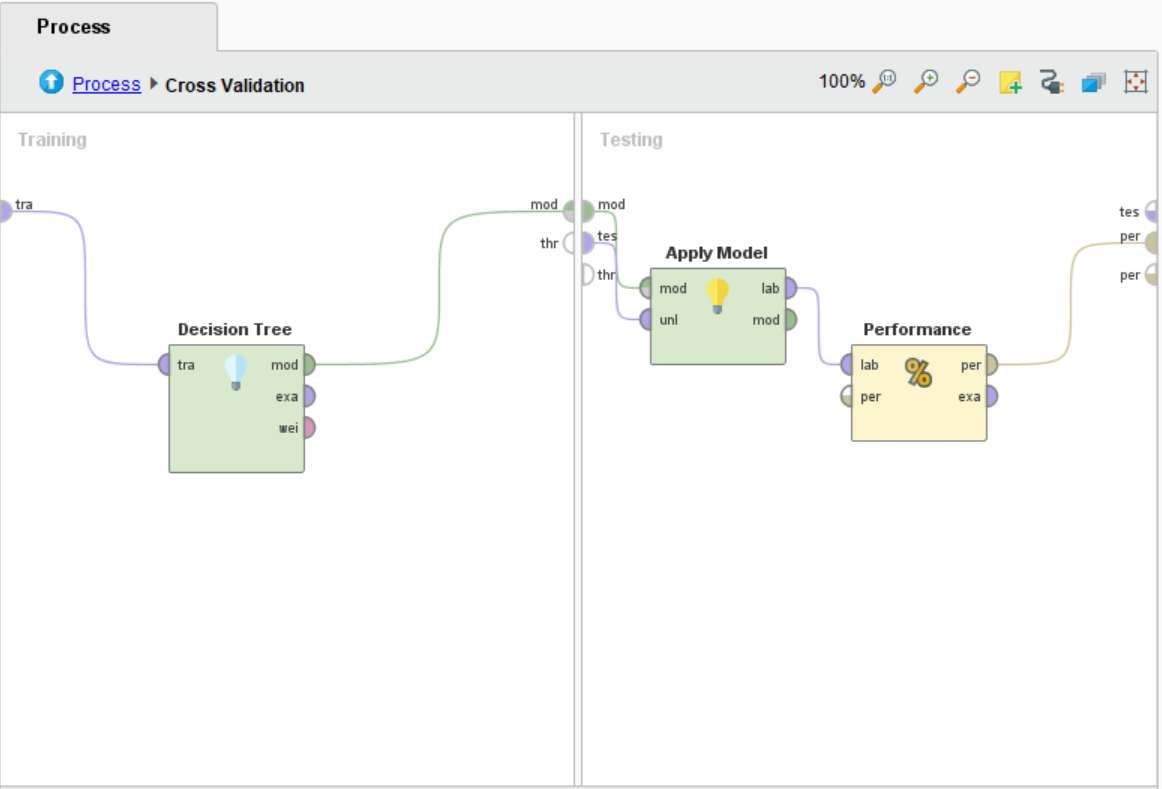
Performance模块可选择所要预测的数值类型,默认为accuracy
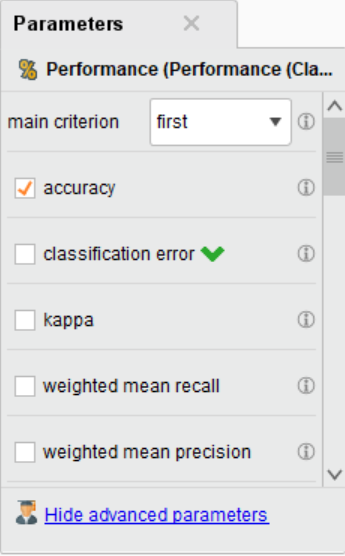
点击Process回到外层界面进行连接,交叉验证模块的number of folds为10代表用10%的数据做测试集,用90%的数据做训练集,然后迭代循环10次
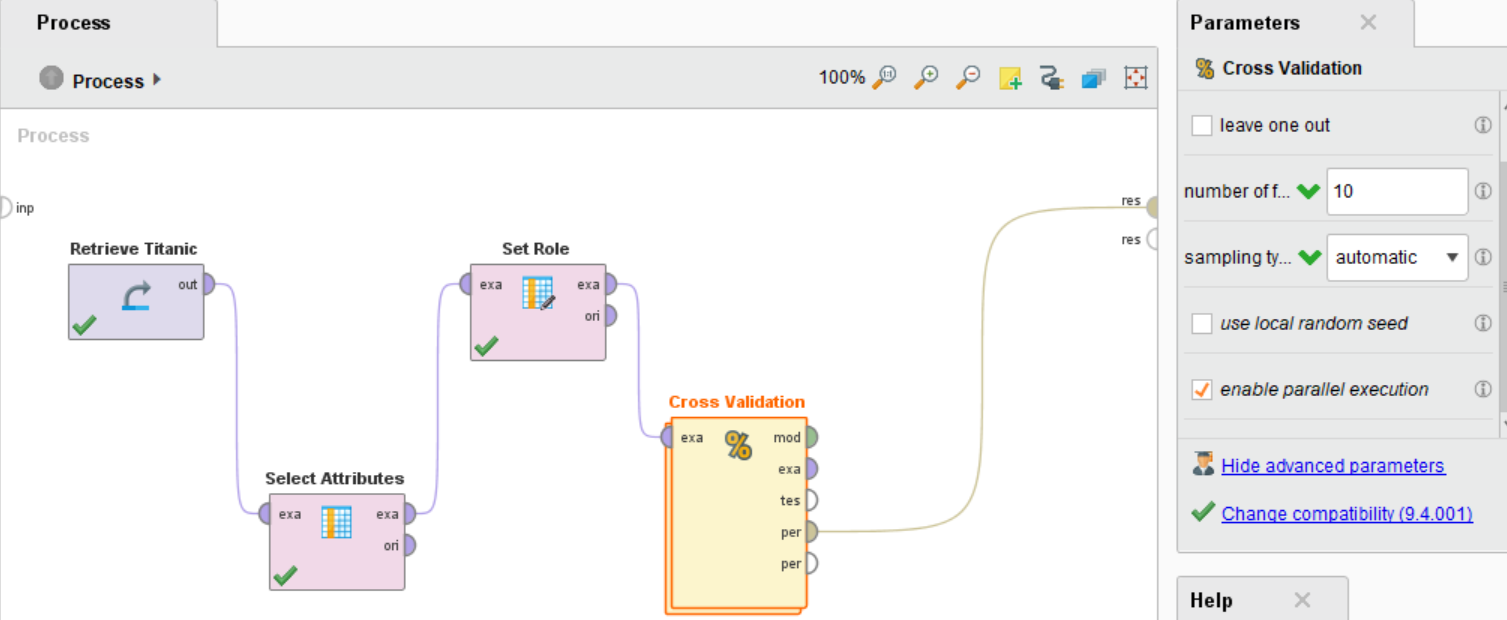
运行后,预测准确率为
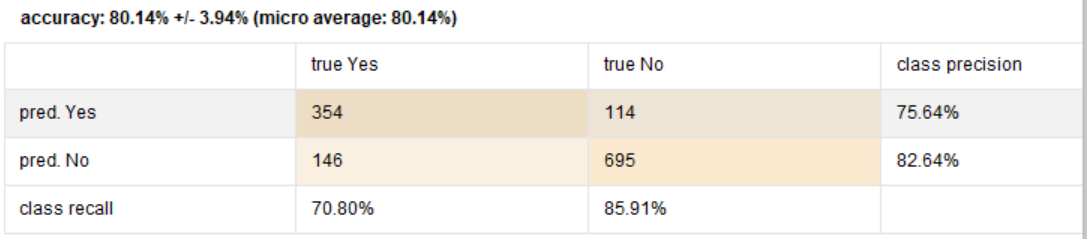
如果想改用逻辑回归,可将交叉验证模块里面的决策树模块换成Logistic Regression模块
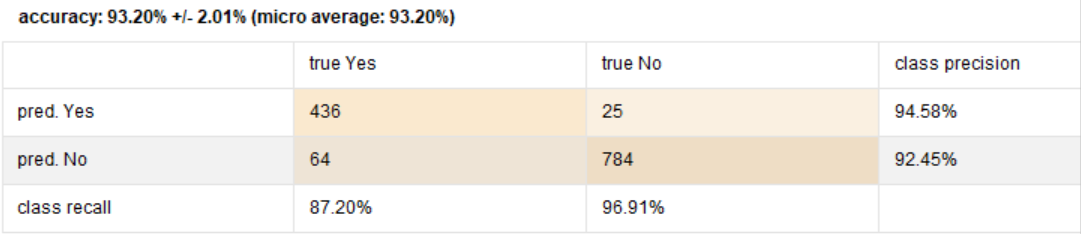
改变之后运行得到的准确率超过了运用决策树的预测模型,说明逻辑回归模型运用在这个数据集相对于使用决策树模型要更高效一些
End
使用rapidminer与使用Python编写方式相比,我们很多时候不需要了解代码是怎么实现的,但是对于参数设置的灵活性没有代码编写的方式灵活
