

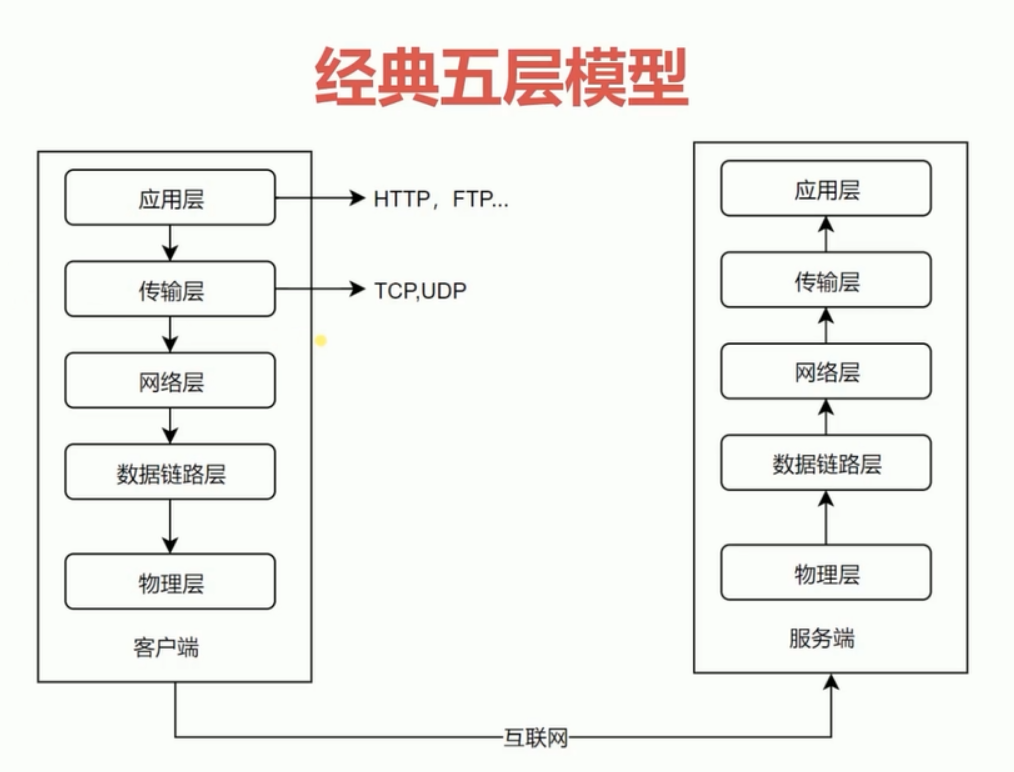
低三层
物理层:定义物理设备如何传输数据(电脑硬件,网卡端口,网线,光缆)
数据链路层:在通信的实体间建立数据链路的连接(通过物理的设备创建电路的连接,传输的数据都是二进制数据)
网络层:数据在节点之间创建逻辑链路(如果我们要去访问百度的服务器,我们该如何去寻找这台服务器的地址)
传输层(TCP,UDP协议)
1、为我们提供了端到端的服务(End-to-End): 比如我们已经建立起了我们自己的电脑到百度服务器的连接之后,他们之间传输数据的方式都是在这一层进行定义的,传输的数据有可能小有可能大,数据量大时需要分片传输,传输到另一端之后需要进行组装,而至于如何进行组装,如何进行传输,这些协议的定义都是在传输层进行定义的。
2、传输层向高层屏蔽了下层数据通信的细节:Http协议是实现在TCP IP协议的基础之上的,Http协议要传输数据,我们只需要在浏览器端输入url,它就会发送相关的数据到服务器端,服务器端对这些数据进行解析,返回给浏览器,然后把页面显示出来,输入url的过程涉及到一些数据的拼装,我们不需要知道它是如何跟服务器创建一个连接的,这是传输层已经封装好的,ajax请求也是Http请求,我们使用ajax中的post方式进行数据请求时,数据量比较大时一次性是传输不完的,它如何可靠的向服务器发送数据,以及服务器如何可靠的返回数据,这些在传输层已经帮我们做好了,不需要太多的关心,我们重点关注的是应用层
应用层(Http协议)
1、为应用软件提供了很多服务: 在我们进行网页开发的时候,我们使用Http协议来发送请求是非常方便的,我们使用new XMLHttpRequest(),就可以把数据通过post或者get的方式发送到服务端,这是应用层中实现的Http协议,我们只需要使用它就可以了
2、它构建于Tcp协议之上: 它的传输的方式最终都是要落实在Tcp ip协议上
3、它屏蔽了网络传输的细节
Http发展历史(简介)
- Http 0.9:
- 只有一个命令GET;
- 没有HEADER等描述数据的信息;
- 服务器发送完毕就关闭TCP连接。
- Http 1.0:
- 增加了很多命令;
- 增加status code和header;
- 支持多字符集、多部分发送、权限、缓存等。
- Http 1.1:
- 持久连接;
- pipeline;
- 增加host和其他一些命令。
- Http 2:
- 所有数据以二进制传输;
- 同一个连接里面发送多个请求不再需要按照顺序来;
- 头信息压缩以及推送等提高效率的功能。
Http三次握手
在我们的客户端与服务器端之间的Http请求的发送与返回的过程中,其实是需要创建一个叫做TCP connection,因为Http是不存在连接这个慨念的,它只存在请求和响应这样的概念,而请求和响应都是数据包,它们之间需要有一个传输的通道,这个通道在哪里呢?就在TCP中创建了一个从客户端发起,服务端接收的连接,这个连接可以一直保持,Http请求是在这个连接的基础上发送的,在TCP连接上面是可以发送多个Http请求的
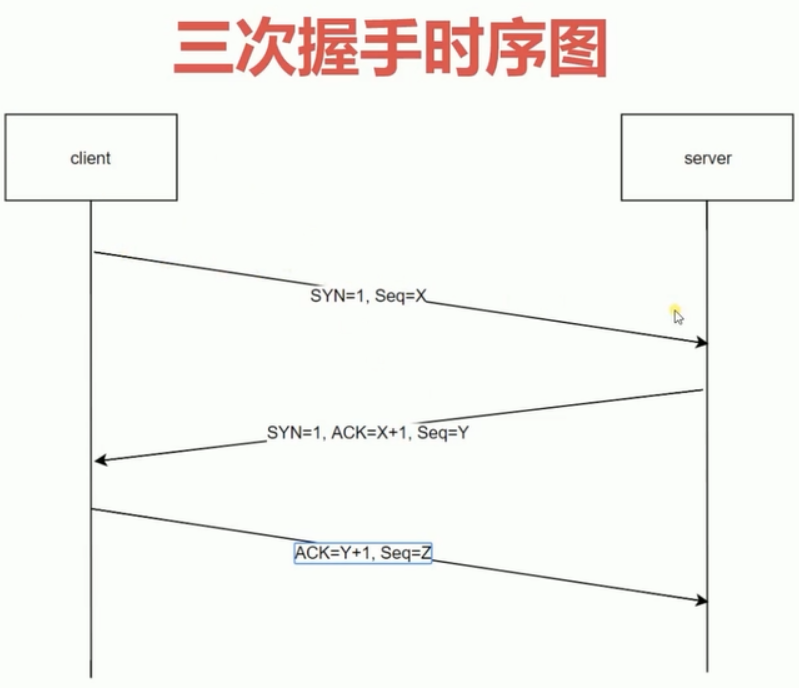
- 首先客户端发起一个创建连接的请求,其中包含了
SYN(标志位)= 1, Seq = 1, 发送到服务端; - 服务端接收到这个请求之后就知道有用户需要创建连接了,就会开启一个TCP的一个端口,并返回给客户端,其中包含
SYN=1,ACK=1+1,Seq=Y - 客户端接收到服务端返回的数据,并发送真实请求给服务端
三次握手主要解决的问题: 规避了因为网络问题导致的服务器开销
URI
- 统一资源标识符
- 用来唯一标识互联网上的信息资源
- 包括URL和URN
URL
http协议中使用的基本都是URL 统一资源定位器
URN
- 永久统一资源定位符
- 在资源移动之后还能被找到
- 目前还没有非常成熟的使用方案
HTTP报文格式

HTTP方法
用来定义对资源的操作,常用的GET,POST等,从定义上讲有各自的语义
HTTP CODE
定义服务器对请求的处理结果,各自区间的CODE有各自的语义,好的HTTO服务可以通过CODE判断结果
HTTP客户端
- 浏览器是我们平时使用最多的HTTP客户端
- git bash中的curl命令也可以很方便发送HTTP请求,并且能够看到请求报文和响应报文信息(
curl -v www.baidu.com)
CORS跨域请求的限制与解决
当跨域问题出现的时候,控制台会报错,此时服务端其实已经返回内容了,只是在浏览器接收到返回的时候发现服务端并没有设置允许跨域的头信息,因此浏览器将这个请求的返回内容拦截掉了,并在控制台中报错。因此我们可以知道,这是浏览器对于跨域请求的一个限制。
- 在服务端设置头信息:
'Access-Control-Allow-Origin': *(设置为*表示允许任何域名跨域请求这个服务,也可以设置为特定的某一个域名能请求:'http://127.0.0.1:3000') - jsonp:浏览器允许 link img script中的src或href进行跨域请求,jsonp的原理就是在script标签中,加载链接,链接访问了服务器某个请求,并返回了内容,服务器返回的内容是可控的,可以在服务器返回内容中的script标签中写一段可执行的JS代码,然后调用JSONP发起请求的一些内容
CORS预请求
除了下面列出来的,其他的都必须要预请求来验证,大概意思就是说会先请求一次,第二次请求才会真的返回数据
- 默认允许的方法:
GET HEAD POST - 默认允许的 Content-Type
1. text/plain
2. multipart/form-data
3. application/x-www-form-urlencoded
- 请求头限制:这个可以查看文档,自定义的请求头是必须要预请求来验证的
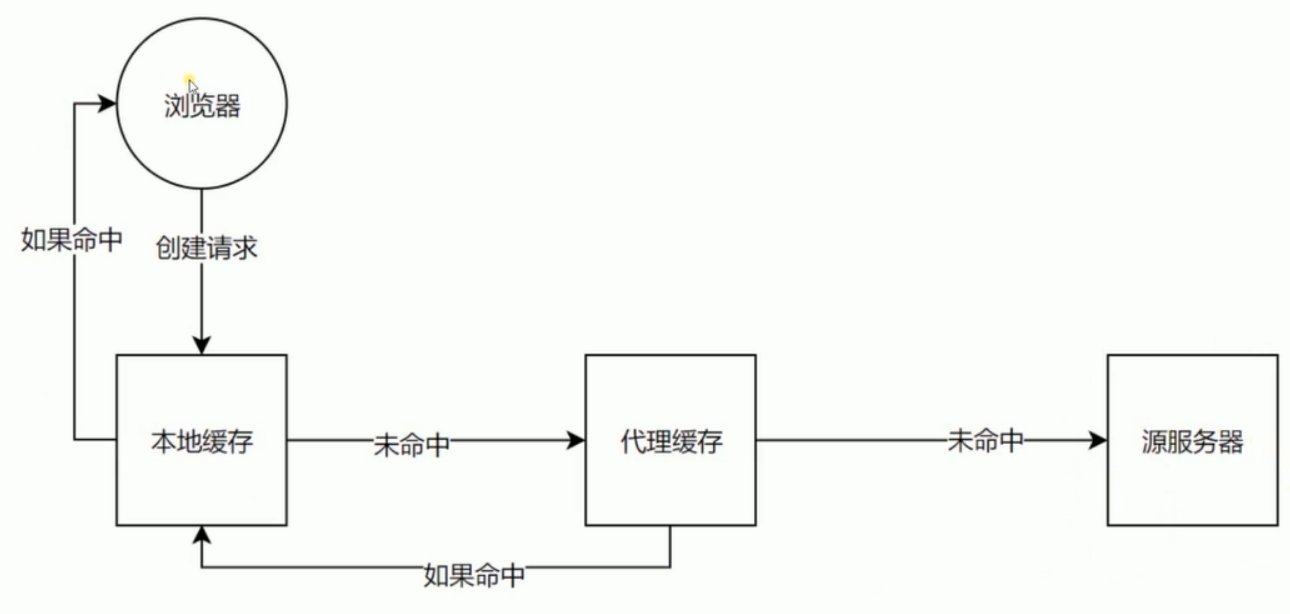
缓存 Cache-Control
- 可缓存性(指定哪些地方能够进行缓存)
- public http请求经过的任何地方都可以进行缓存(代理服务器和客户端浏览器都可以进行缓存)
- private 只有发起请求的浏览器才能进行缓存
- no-cache 可以进行缓存,但需要在服务器进行验证才能够被允许使用缓存
- 到期(缓存何时到期)
- max-age = (浏览器会去读取它,得知缓存何时到期)
- s-maxage = (只在代理服务器生效,在代理服务器中设置了s-maxage时就不会去读取max-age)
- max-stale = (发起请求放主动带的头信息,在max-age过期之后,只要在max-stale的时间范围内,依然可以使用这个过期的缓存,浏览器中是用不到的)
- 重新验证(浏览器访问页面也不太会用到)
- must-revalidate(如果max-age的缓存已经过期,那我们必须从原服务端发起请求重新获取数据,再来验证这个数据是否真的已经过期,而不能直接使用本地的缓存)
- proxy-revalidate(用在缓存服务器的,缓存服务器如果过期了,必须去原服务器重新请求一遍,而不能直接使用本地缓存)
- 其他
- no-store(不允许进行缓存)
- no-transform
缓存验证
- 验证头
- Last-Modified(上次修改时间) 配合If-Modified-Since或者If-Unmodified-Since,对比上次修改时间以验证资源是否需要更新
- Etag(数据签名) 配合If-Match或者If-Non-Match使用,对比资源的签名判断是否使用缓存
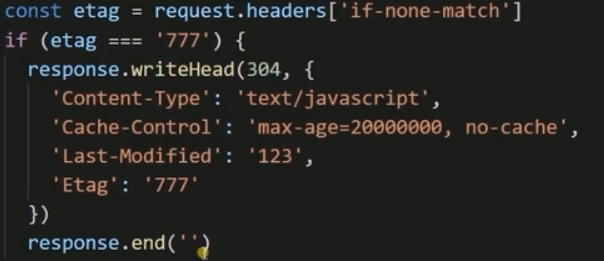
Cookie
- 通过Set-Cookie设置
- 下次请求会自动带上
- 键值对,可以设置多个
Cookie属性
- max-age和expires设置过期时间
- Secure只在https的时候发送
- HttpOnly无法通过document.cookie访问(安全性)

HTTP长连接
http链接是在TCP连接上面发送的,一个TCP连接可以发送多个HTTP请求
- 在HTTP1.1中,在TCP连接上发送HTTP请求是有先后顺序的,并发请求最多一次6个,为了提高性能,还是要并发TCP连接;
- 在HTTP2中,在一个TCP连接可以并发的发送HTTP请求,所以只需要一个TCP连接就够了;
数据协商
- 请求 Accept
- Accept 声明客户端需要什么样的数据类型
- Accept-Encoding 数据以什么编码方式进行传输,限制服务端的数据压缩
- Accept-Language 判断是中文还是其他语言
- User-Agent判断是pc端还是移动端或者其他端
- 返回 Content
- Content-Type 对应Accept,Accept中可以接受好几种数据格式,Content-Type选择一种作为返回的数据格式进行返回
- Content-Encoding 对应Accept-Encoding服务端具体使用的哪种压缩方式
- Content-Language 是否根据请求返回了相应的语言
