

1. Spark是什么?
Spark是一个为了大数据处理而产生的快速通用的引擎
Apache Spark是一个为了让数据分析更快的开源的计算集群系统
运行快、编写快
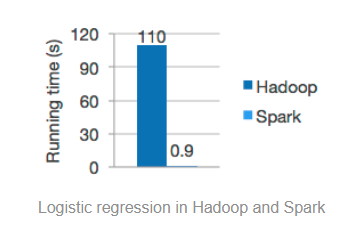
2. Spark为什么这么快?
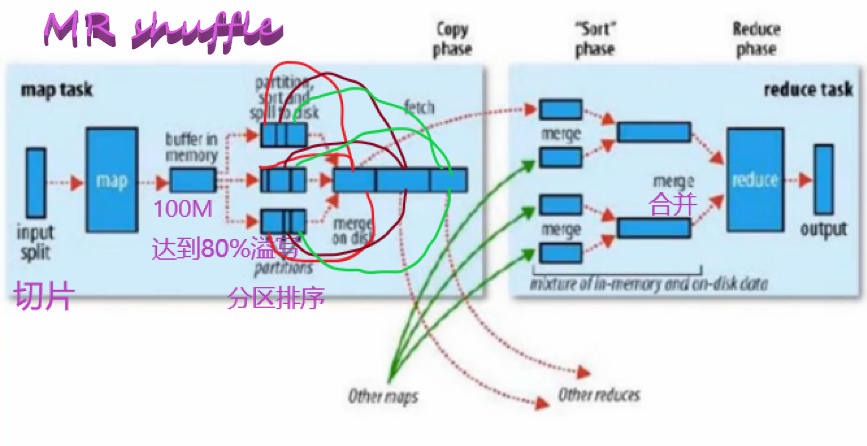
Map和Reduce之间有一个shuffle过程,涉及数据落地磁盘;Spark处理数据基于内存
DAG有向无环图,分成很多个task
3. Spark的特点
速度快
使用简单
集成
无处不运行
4. Spark的技术栈
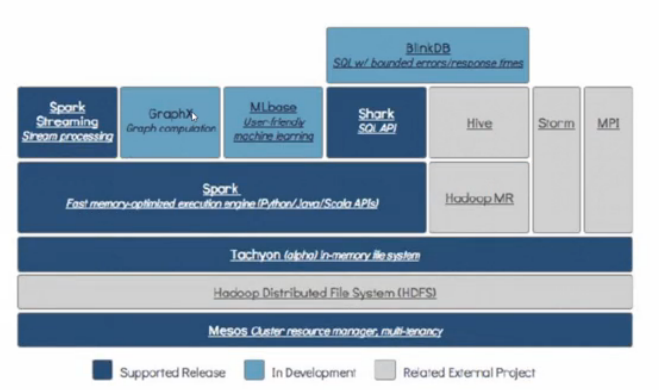
底层Mesos资源调度框架,类似于yarn
Hadoop Distributed System(HDFS)
存储的最小单元block,默认大小128M,三个副本,副本存储在不同机架
Tachyon-In-memory file system
基于内存的分布式文件系统
Hadoop MR
Hive
数据仓库,9083端口读取数据,通过MySQL存储
Storm
实时流处理
Spark Streaming Stream processing
Spark core
Shark SQL API
ML base
机器学习库
BlinkDB
*数据仓库,支持精确度查询
GraphX
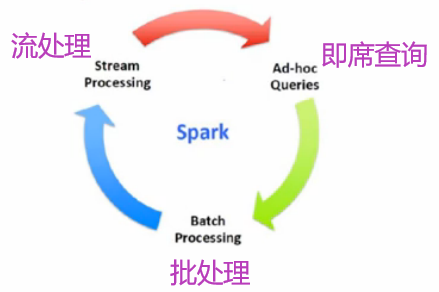
5.回顾Hadoop
6. Java版的wordcount
package com.ht.spark;
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.streaming.dstream.PairDStreamFunctions;
import scala.Tuple2;
public class JavaSparkWordCount {
public static void main(String[] args) {
/**
* conf
* 1.可以设置spark的运行模式
* 2.可以设置spark在webui中显示的application的名称
* 3.可以设置当前Spark application运行的资源(内存+core)
*
* Spark运行模式
* 1.local--在eclipse,IDEA中开发spark程序要用local模式*本地模式,多用于测试
* 2.stand alone--Spark自带的资源调度框架,支持分布式搭建,Spark任务可以依赖Stand alone调度资源
* 3.yarn -- Hadoop生态圈中资源调度框架,Spark也可以基于yarn调度资源
* 4.mesos --资源调度框架
*/
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("JavaSparkWorldCount");
/**
* SparkContext是通往集群的唯一通道
*/
JavaSparkContext sc = new JavaSparkContext(conf);
/**
* sc.textFile读取文件
*/
JavaRDD<String> lines = sc.textFile("./words");
/**
* flatMap是一对多,进来一条数据,出去多条数据
*/
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String,String>() {
private static final long serialVersionUID = 1L;
@Override
public Iterable<String> call(String line) throws Exception {
// TODO 自动生成的方法存根
return Arrays.asList(line.split(" "));
}
});
/**
* 在java中如果想要让某个RDD转换位K,V模式,使用xxxToPair
* K,V格式的RDD:JavaPairRDD<String,Integer>
*
*/
JavaPairRDD<String,Integer> pairWords = words.mapToPair(new PairFunction<String,String,Integer>(){
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
// TODO 自动生成的方法存根
return new Tuple2<String,Integer>(word,1);
}
/**
*
*/
});
/**
* reduceByKey
* 1.先将相同的key分组
* 2.对每一组的key对应的value去按照你的逻辑去处理
*/
JavaPairRDD<String, Integer> reduce = pairWords.reduceByKey(new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
// TODO 自动生成的方法存根
return v1 + v2;
}
});
JavaPairRDD<Integer, String> mapToPair = reduce.mapToPair(new PairFunction<Tuple2<String,Integer>,Integer,String>(){
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Integer, String> call(Tuple2<String, Integer> tuple) throws Exception {
// TODO 自动生成的方法存根
// return new Tuple2<Integer, String>(tuple._2,tuple._1);
return tuple.swap();
}
});
JavaPairRDD<Integer, String> sortByKey = mapToPair.sortByKey(false);
JavaPairRDD<String, Integer> result = sortByKey.mapToPair(new PairFunction<Tuple2<Integer,String>,String,Integer>(){
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(Tuple2<Integer, String> tuple) throws Exception {
// TODO 自动生成的方法存根
// return new Tuple2<Integer, String>(tuple._2,tuple._1);
return tuple.swap();
}
});
result.foreach(new VoidFunction<Tuple2<String,Integer>>() {
private static final long serialVersionUID = 639147013282066178L;
@Override
public void call(Tuple2<String,Integer> tuple) throws Exception {
// TODO 自动生成的方法存根
System.out.println(tuple);
}
});
sc.stop();
}
}
words
hello bjsxt
hello scala
hello java
hello python
hello huangting
hello china
hello hadoop
hello bjsxt
hello scala
hello java
hello python
hello huangting
hello china
hello hadoo
hello bjsxt
hello scala
hello java
hello python
hello huangting
hello china
hello hadoop
hello bjsxt
hello beijing
hello java
hello python
hello huangting
hello china
hello hadoop
hello bejing
hello i
运行结果

结果分析
1. 一行一行的读取文件
2. 每行的单词用" " 分隔
3. 输入一个单词,生成一个元组(单词,1)
4. 对所有生成的元组进行合并
5. 将元组转置成(n,单词),n是key,单词是value
6. 转置后根据key进行降序排序
7. 将排序完的元组转置回(单词,n)
8. 依次打印
