

hive是基于hadoop的数据仓库,类似于数据库的模式,以特有的类sql的模式hsql用来对数据进行查询,处理,存储等操作,是一种基于mapreduce的模式工具,在与hbase共同使用时,通过创建外部表可以处理hbase无法做到的复杂查询以及数据处理,使得mapreduce变得更简单。spark也是基于mepreduce的处理大型数据的计算引擎,spark可以将处理的结果存储在内存中,大大提高运行效率。spark包含多个功能,sql,机器学习,云计算。其中sparksql同样可以进行类似sql的复杂查询。
一.Hive安装
1.安装hive
先要确保mysql已经安装在服务器中
tar -zxvf apache-hive-2.3.3-bin.tar.gz
2.配置环境变量
vim /etc/profile

3.修改配置文件
- 修改hive-site.xml文件
将hive-default.xml.template文件复制一份并改名为hive-site.xml,在文件中有如下配置:
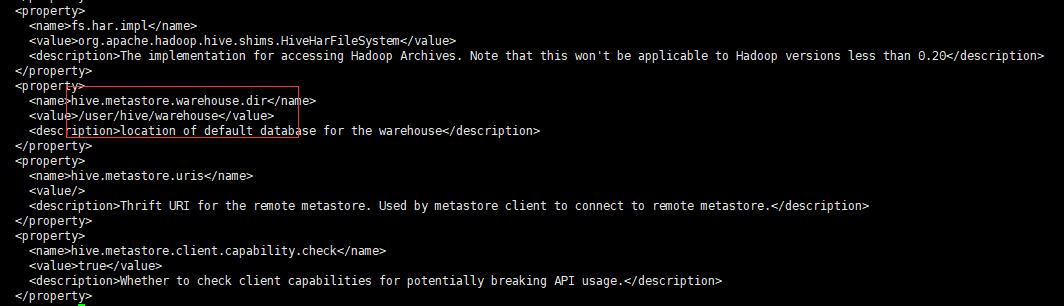
hdfs dfs -chmod 777 /user/hive/warehouse
执行hadoop命令"hadoop dfs -mkdir -p /tmp/hive"新建/tmp/hive目录
给/tmp/hive目录赋予读写权限"hdfs dfs -chmod 777 /tmp/hive"
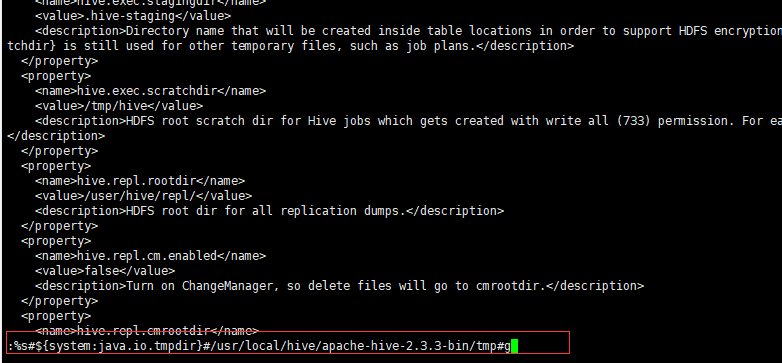
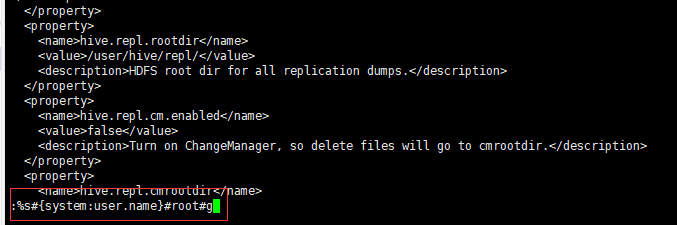
查看创建并授权的目录"hdfs dfs -ls /tmp" - 修改hive-site.xml的临时目录,将文件中的所有
{system:java.io.tmpdir}#/usr/local/hive/apache-hive-2.3.3-bin/tmp#g“替换所有的临时目录
- 把mysql的驱动包上传至hive的lib目录下
- 修改hive-site.xml数据库相关配置
- 修改javax.jdo.option.connectionURL,将name对应的value修改为mysql的地址

- 修改javax.jdo.option.ConnectionDriverName,将name对应的value修改为mysql驱动类路径

- 修改javax.jdo.option.ConnectionUserName,将对应的value修改为MySQL数据库登录名

- 修改javax.jdo.option.ConnectionPassword,将对应的value修改为MySQL数据库的登录密码
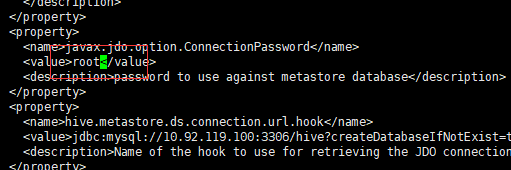
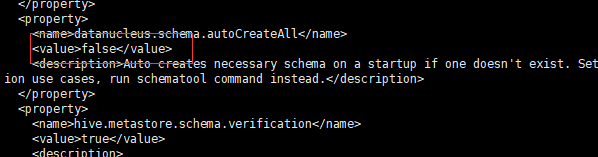
- 修改hive.metastore.schema.verification,将对应的value修改为false
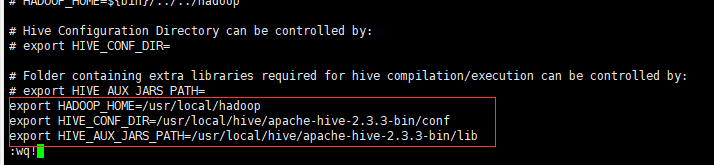
- 在conf目录下,拷贝hive-env.sh.template存为hive-env.sh,并修改修改hive-env.sh文件
4.启动和测试
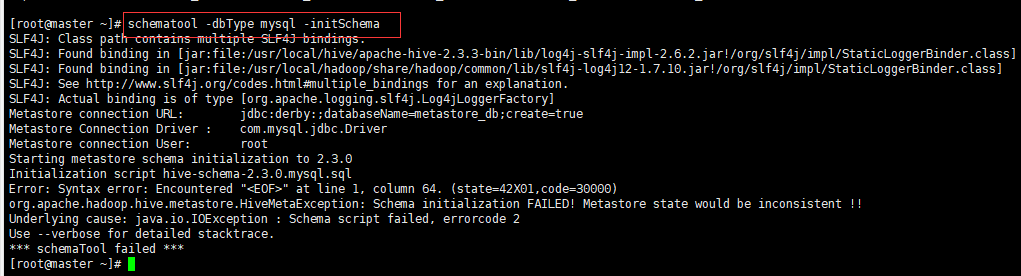
- 先对mysql数据库进行初始化
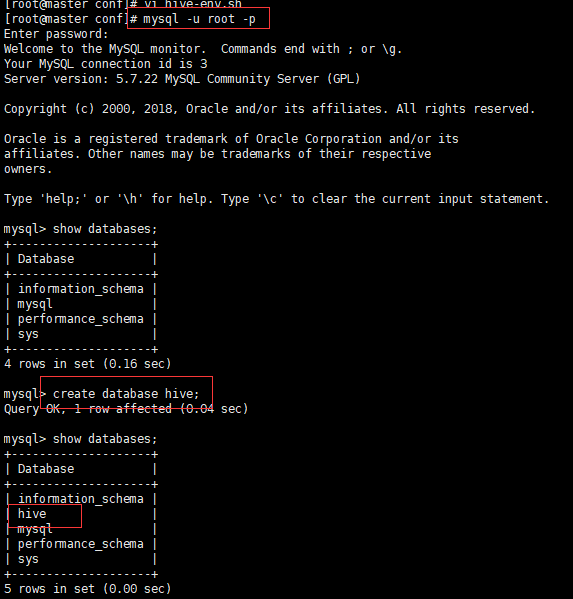
- 登陆mysql并创建hive数据库
- 启动hive 定位至hive安装目录,输入命令"./hive",启动hive
二.Spark集群搭建
- 配置spark需要scala环境,因此需要下载scala与spark两个压缩包,我使用的是2.11版本,大家去官网下载即可,在这里不赘述。
- 配置scala
首先解压scala压缩包
tar -xzf scala-2.11.7.tgz
然后配置环境变量,加入scala路径
vim /etc/rpofile
# scala
export SCALA_HOME=/usr/local/hadoop/scala
export PATH=$SCALA_HOME/bin:$PATH
再使环境变量生效
source /etc/profile
3. 配置spark
tar -xzf spark-2.3.0-bin-hadoop2.6.tgz
添加环境变量
# spark
export SPARK_HOME=/usr/local/spark-2.3.0
export PATH=$SPARK_HOME/bin:$PATH
使环境变量生效
source /etc/profile
4. 修改spark配置文件
cd /usr/local/spark-2.3.0/conf
修改slaves.templates文件名为slaves
cp slaves.templates slaves
vim slaves
hadoop1
hadoop2
hadoop3
hadoop4
再修改spark-env.sh.template 为spark-env.sh
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
export SCALA_HOME=/usr/local/hadoop/scala
export HADOOP_HOME=/usr/local/hadoop
export JAVA_HOME=/usr/local/jdk
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_IP=192.168.1.25
export SPARK_MASTER_HOST=192.168.1.25
export SPARK_MASTER_PORT=7077
export SPARK_LOCAL_IP=192.168.1.25
export SPARK_WORKER_MEMORY=10g
export SPARK_WORKER_CORES=3
export SPARK_EXECUTOR_CORES=3
export SPARK_HOME=/usr/local/spark-2.3.0
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath):$(/usr/local/hadoop/hbase/bin/hbase classpath):/usr/local/spark-2.3.0/jars/hbase/*
- 复制到其他服务器
scp -r /usr/local/spark-2.3.0 root@hadoop2: /usr/local/
scp -r /usr/local/spark-2.3.0 root@hadoop3: /usr/local/
scp -r /usr/local/spark-2.3.0 root@hadoop4: /usr/local/ - 启动spark集群
进入到主节点的sbin目录下 ./start-all.sh
