为了向您展示Scrapy带来了什么,我们将使用最简单的运行爬虫的方法向您介绍Scrapy Spider的示例。 将下面代码放在文本文件中,将其命名为quotes_spider.py之类的名称,然后使用runspider命令运行程序:scrapy runspider quotes_spider.py -o quotes.json
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
start_urls = [
'http://quotes.toscrape.com/tag/humor/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'author': quote.xpath('span/small/text()').get(),
'text': quote.css('span.text::text').get(),
}
next_page = response.css('li.next a::attr("href")').get()
if next_page is not None:
yield response.follow(next_page, self.parse)
完成此操作后,您将在quotes.json文件中具有JSON格式的引号列表,其中包含文本和作者,如下所示(此处重新格式化以提高可读性):
[{
"author": "Jane Austen",
"text": "\u201cThe person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.\u201d"
},
{
"author": "Groucho Marx",
"text": "\u201cOutside of a dog, a book is man's best friend. Inside of a dog it's too dark to read.\u201d"
},
{
"author": "Steve Martin",
"text": "\u201cA day without sunshine is like, you know, night.\u201d"
},
...]
查看start_urls:quotes.toscrape.com/tag/humor/的…


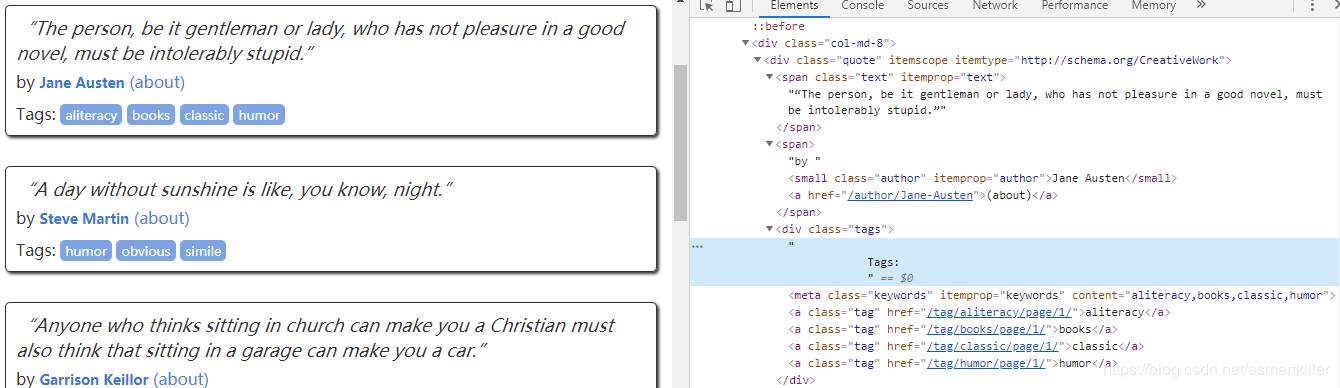
'author': quote.xpath('span/small/text()').get(),
'text': quote.css('span.text::text').get(),
下面的HTML显示了Top Ten Tags的结构: