

JS引擎
JavaScript 引擎说起来最流行的当然是谷歌的 V8 引擎了, V8 引擎使用在 Chrome 以及 Node 中,下面有个简单的图能说明他们的关系
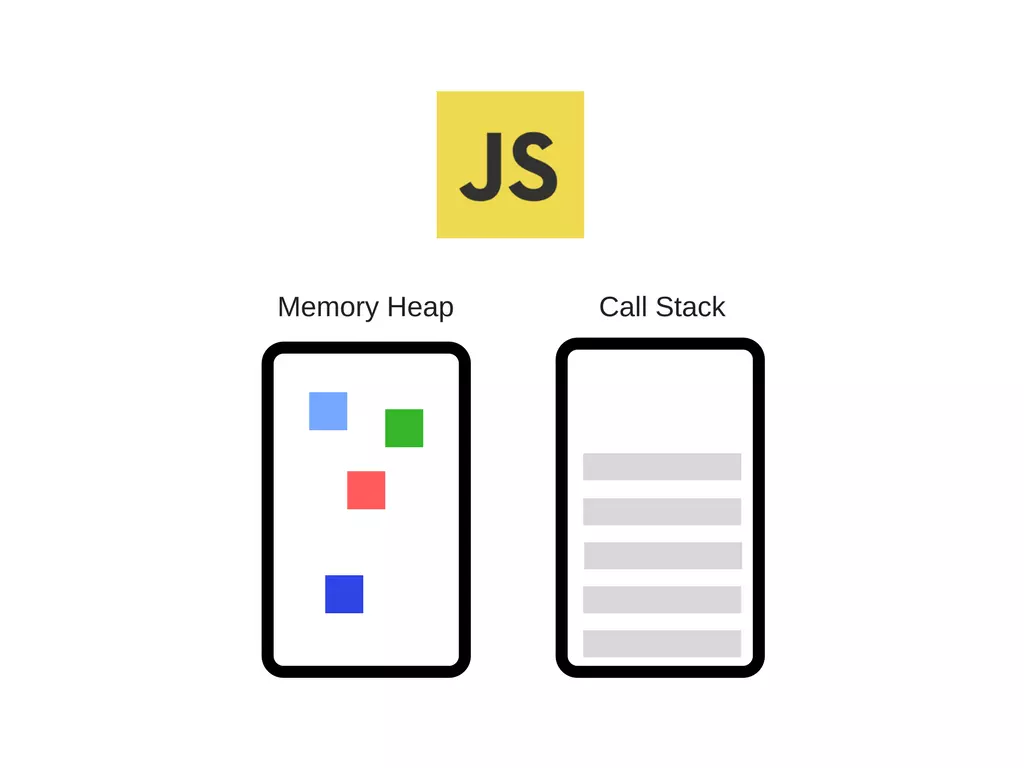
内存堆:这是内存分配发生的地方。当V8引擎遇到变量声明和函数声明的时候,就把它们存储在堆里面。
调用栈:这是你的代码执行时的地方。当引擎遇到像函数调用之类的可执行单元,就会把它们推入调用栈。
JS单线程,指的是在JS引擎中,解析执行JS代码的调用栈是唯一的,所有的JS代码都在这一个调用栈里按照调用顺序执行,不能同时执行多个函数。
运行时
我们可以把JS的运行时环境看作一个大的容器,里面有一些其他的小容器。当JS引擎解析代码时,就是把代码片段分发到不同的容器里。
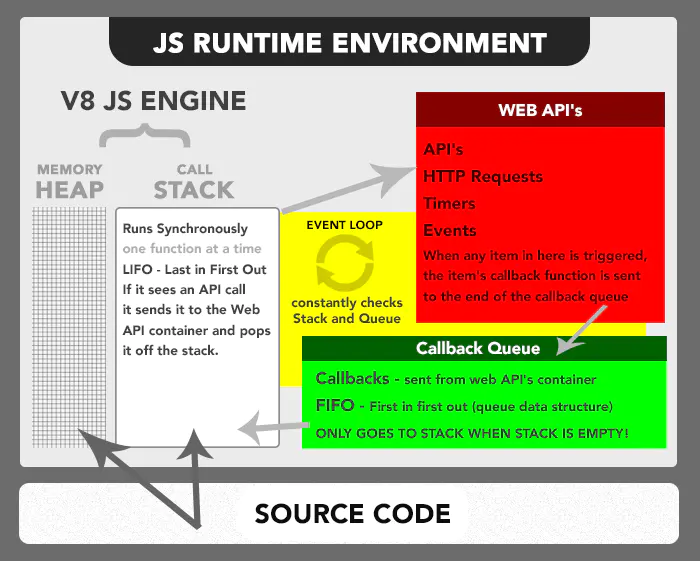
这整个一套环境称为JS的运行时环境。
Web API:还有很多引擎之外的 API,我们把这些称为浏览器提供的 Web API,比如说 事件监听函数、DOM、HTTP/AJAX请求、setTimeout等等。
事件循环:持续的检测调用栈和回调队列,如果检测到调用栈为空,它就会通知回调队列把队列中的第一个回调函数推入执行栈。
回调队列:按照先进先出的顺序存储所有的回调函数。在任意时间,只要Web API容器中的事件达到触发条件,就可以把回调函数添加到回调队列中去。
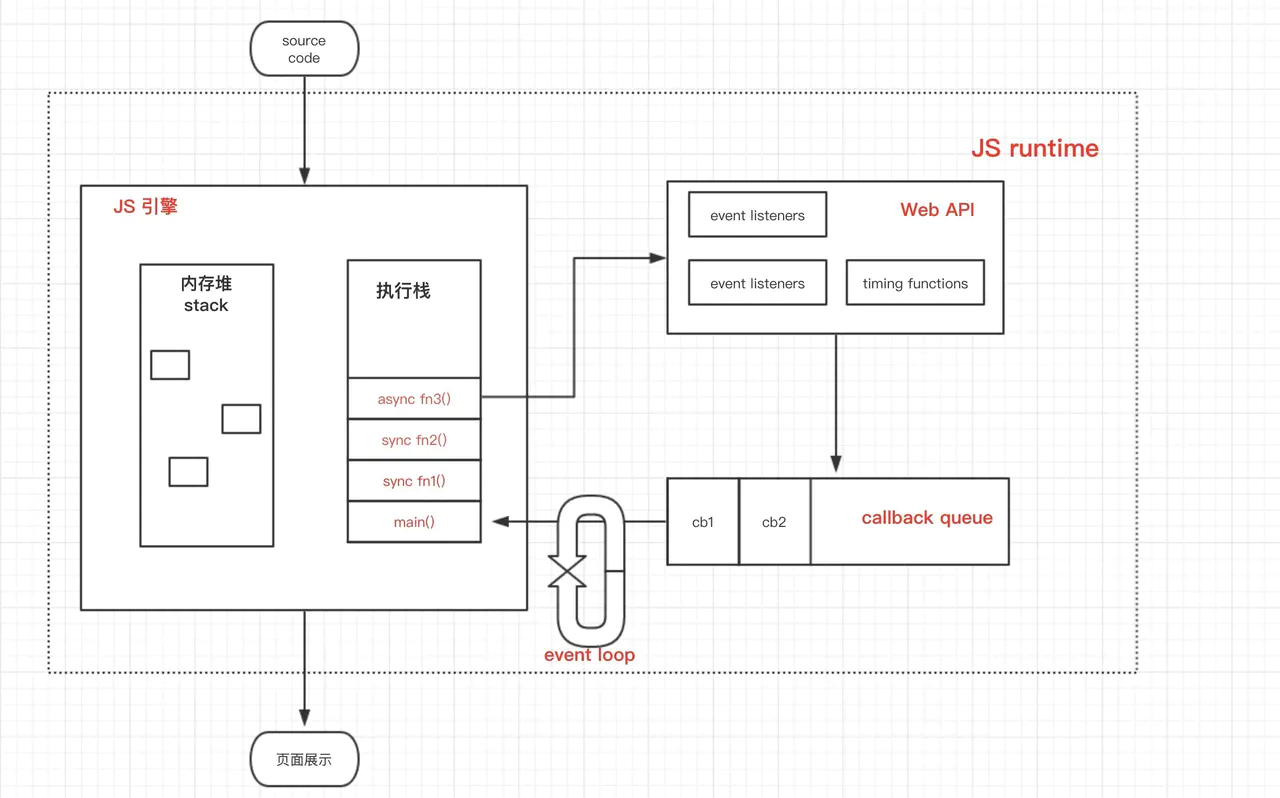
JS运行时环境的工作机制:
- JS引擎(唯一主线程)按顺序解析代码,遇到函数声明,直接跳过,遇到函数调用,入栈;
- 如果是同步函数调用,直接执行得到结果,同步函数弹出栈,继续下一个函数调用;
- 如果是异步函数调用,分发给Web API(多个辅助线程),异步函数弹出栈,继续下一个函数调用;
- Web API中,异步函数在相应辅助线程中处理完成后,即异步函数达到触发条件了,就把回调函数推入回调队列中。
- Event Loop不停地检查主线程的调用栈与回调队列,当调用栈空时,就把回调队列中的第一个任务推入栈中执行,不断循环。
示例:
setTimeout(function(){
console.log('Hey, Why am I last?')
}, 0)
function sayHi(){
console.log('Hello')
}
function sayBye(){
console.log('Goodbye')
}
sayHi()
sayBye()
执行过程是这样的:
- JS引擎会检查整段代码的语法错误,如果没有错误,就从头开始深度解析
- 首先遇到setTimeout函数调用,把它推入执行栈顶
- 解析函数体,发现setTimeout函数是Web API的一种,因此就把它分发到Web API模块然后推出栈
- 因为定时器设置了0ms延迟,因此Web API模块立即把它的匿名回调函数推入到回调函数函数队列。事件循环检测执行栈是否是空闲,但是当前栈并不空闲,因为...
- 当setTimeout函数一被分发到Web API模块,JS引擎发现了两个函数声明,把它们存储在堆内存里,然后遇到了sayHi函数的调用,就把它推入了栈顶
- sayHi函数调用了console.log函数,因此console.log就被推入了栈顶
- JS引擎开始解析console.log的函数体,它接收了一个消息去打印‘Hello’,然后被弹出栈
- JS引擎返回到函数sayHi的执行,遇到函数的结束符号}之后,把sayHi弹出栈
- sayHi函数一出栈,紧接着sayBye函数被调用,它就被推入栈顶,被解析,调用console.log,把console.log推入栈顶,打印一条消息,弹出栈。然后sayBye函数弹出栈
- 事件循环检测到执行栈终于空闲了,通知回调队列,然后回调队列把其中的匿名函数推入执行栈
- 匿名函数(就是setTimeout的回调函数)被解析,调用console.log,console.log推入栈顶
- console.log执行完毕、再出栈
- 匿名函数再被推出栈,程序结束
调用椎栈
可以把执行栈认为是一个存储函数调用的栈结构,遵循先进后出的原则。

当开始执行 JS 代码时,首先会执行一个 main 函数,然后执行我们的代码。 根据先进后出的原则,后执行的函数会先弹出栈,在图中我们也可以发现,foo 函数后执行,当执行完毕后就从栈中弹出了。
平时在开发中,大家也可以在报错中找到执行栈的痕迹
function foo() {
throw new Error('error')
}
function bar() {
foo()
}
bar()

大家可以在上图清晰的看到报错在 foo 函数,foo 函数又是在 bar 函数中调用的。 当我们使用递归的时候,因为栈可存放的函数是有限制的,一旦存放了过多的函数且没有得到释放的话,就会出现栈溢出。
