第一部分:泛型编程
我们需要清楚地知道,无论哪种程序语言,都避免不了一个特定的类型系统。
哪怕是可随意改变变量类型的动态类型的语言,我们在读代码的过程中也需要脑补某个变量在运行时的类型。
所以,每个语言都需要一个类型检查系统。
-
静态类型检查是在编译器进行语义分析时进行的。如果一个语言强制实行类型规则(即通常只允许以不丢失信息为前提的自动类型转换),那么称此处理为强类型,反之称为弱类型。
-
动态类型检查系统更多的是在运行时期做动态类型标记和相关检查。所以,动态类型的语言必然要给出一堆诸如:is_array(), is_int(), is_string() 或是 typeof() 这样的运行时类型检查函数。
静态类型语言的支持者和动态类型自由形式的支持者,经常发生争执。前者主张,在编译的时候就可以较早发现错误,而且还可增进运行时期的性能。
一定要注重基础和原理,基础打牢,学什么都快,而学得快就会学得多,学得多,就会思考得多,对比得多,结果是学得更快。
后者主张,使用更加动态的类型系统,分析代码更为简单,减少出错机会,才能更加轻松快速地编写程序。与此相关的是,后者还主张,考虑到在类型推断的编程语言中,通常不需要手动宣告类型,这部分的额外开销也就自动降低了
泛型的本质
要了解泛型的本质,就需要了解类型的本质。
- 类型是对内存的一种抽象。不同的类型,会有不同的内存布局和内存分配的策略。
- 不同的类型,有不同的操作。所以,对于特定的类型,也有特定的一组操作。所以,要做到泛型,我们需要做下面的事情:标准化掉类型的内存分配、释放和访问。
- 标准化掉类型的操作。比如:比较操作,I/O操作,复制操作……
- 标准化掉数据容器的操作。比如:查找算法、过滤算法、聚合算法……
- 标准化掉类型上特有的操作。需要有标准化的接口来回调不同类型的具体操作……
所以,C++动用了非常繁多和复杂的技术来达到泛型编程的目标。
- 通过类中的构造、析构、拷贝构造,重载赋值操作符,标准化(隐藏)了类型的内存分配、释放和复制的操作。
- 通过重载操作符,可以标准化类型的比较等操作。
- 通过 iostream,标准化了类型的输入、输出控制。
- 通过模板技术(包括模板的特化),来为不同的类型生成类型专属的代码。
- 通过迭代器来标准化数据容器的遍历操作。
- 通过面向对象的接口依赖(虚函数技术),来标准化了特定类型在特定算法上的操作。
- 通过函数式(函数对象),来标准化对于不同类型的特定操作。
第二部分:函数式编程
特征
- stateless:函数不维护任何状态。函数式编程的核心精神是 stateless,简而言之就是它不能存在状态,打个比方,你给我数据我处理完扔出来。里面的数据是不变的。
- immutable:输入数据是不能动的,动了输入数据就有危险,所以要返回新的数据集。
优势
- 没有状态就没有伤害。
- 并行执行无伤害。
- Copy-Paste 重构代码无伤害。
- 函数的执行没有顺序上的问题
劣势
- 数据复制比较严重。
但是很多人并不习惯函数式编程,因为函数式编程和过程式编程的思维方式完全不一样。过程式编程是在把具体的流程描述出来,所以可以不假思索,而函数式编程的抽象度更大,在实现方式上,有函数套函数、函数返回函数、函数里定义函数……把人搞得很糊涂。
函数式编程用到的技术
- first class function(头等函数) :这个技术可以让你的函数就像变量一样来使用。也就是说,你的函数可以像变量一样被创建、修改,并当成变量一样传递、返回,或是在函数中嵌套函数。
- tail recursion optimization(尾递归优化) : 我们知道递归的害处,那就是如果递归很深的话,stack 受不了,并会导致性能大幅度下降。因此,我们使用尾递归优化技术——每次递归时都会重用 stack,这样能够提升性能。当然,这需要语言或编译器的支持。Python 就不支持。
- map & reduce :这个技术不用多说了,函数式编程最常见的技术就是对一个集合做 Map 和 Reduce 操作。这比起过程式的语言来说,在代码上要更容易阅读。(传统过程式的语言需要使用 for/while 循环,然后在各种变量中把数据倒过来倒过去的)这个很像 C++ STL 中 foreach、find_if、count_if 等函数的玩法。
- pipeline(管道):这个技术的意思是,将函数实例成一个一个的 action,然后将一组 action 放到一个数组或是列表中,再把数据传给这个 action list,数据就像一个 pipeline 一样顺序地被各个函数所操作,最终得到我们想要的结果。
- recursing(递归) :递归最大的好处就简化代码,它可以把一个复杂的问题用很简单的代码描述出来。注意:递归的精髓是描述问题,而这正是函数式编程的精髓。
- currying(柯里化) :将一个函数的多个参数分解成多个函数, 然后将函数多层封装起来,每层函数都返回一个函数去接收下一个参数,这可以简化函数的多个参数。在 C++ 中,这很像 STL 中的 bind1st 或是 bind2nd。
- higher order function(高阶函数):所谓高阶函数就是函数当参数,把传入的函数做一个封装,然后返回这个封装函数。现象上就是函数传进传出,就像面向对象对象满天飞一样。这个技术用来做 Decorator 很不错。
函数式编程关注的是:describe what to do, rather than how to do it。于是,我们把以前的过程式编程范式叫做 Imperative Programming – 指令式编程,而把函数式编程范式叫做 Declarative Programming – 声明式编程。
所谓的修饰器模式其实是在做下面的几件事。
- 表面上看,修饰器模式就是扩展现有的一个函数的功能,让它可以干一些其他的事,或是在现有的函数功能上再附加上一些别的功能。
- 除了我们可以感受到函数式编程下的代码扩展能力,我们还能感受到函数的互相和随意拼装带来的好处。
- 但是深入看一下,我们不难发现,Decorator 这个函数其实是可以修饰几乎所有的函数的。于是,这种可以通用于其它函数的编程方式,可以很容易地将一些非业务功能的、属于控制类型的代码给抽象出来(所谓的控制类型的代码就是像 for-loop,或是打日志,或是函数路由,或是求函数运行时间之类的非业务功能性的代码)。
第三部分:面向对象编程
面向对象的编程有三大特性:封装、继承和多态。
优点
- 能和真实的世界交相辉映,符合人的直觉。
- 面向对象和数据库模型设计类型,更多地关注对象间的模型设计。
- 强调于“名词”而不是“动词”,更多地关注对象和对象间的接口。
- 根据业务的特征形成一个个高内聚的对象,有效地分离了抽象和具体实现,增强了可重用性和可扩展性。
- 拥有大量非常优秀的设计原则和设计模式。
- S.O.L.I.D(单一功能、开闭原则、里氏替换、接口隔离以及依赖反转,是面向对象设计的五个基本原则)、DRY、KISS、YAGNI、IoC/DIP……
缺点
- 代码都需要附着在一个类上,从一侧面上说,其鼓励了类型。
- 代码需要通过对象来达到抽象的效果,导致了相当厚重的“代码粘合层”。
- 因为太多的封装以及对状态的鼓励,导致了大量不透明并在并发下出现很多问题。
通过对象来达到抽象结果,把代码分散在不同的类里面,然后,要让它们执行起来,就需要把这些类粘合起来。所以,它另外一方面鼓励相当厚重的代码黏合层(代码黏合层就是把代码黏合到这里面)。
在 Java 里有很多注入方式,像 Spring 那些注入,鼓励黏合,导致了大量的封装,完全不知道里面在干什么事情。而且封装屏蔽了细节,具体发生啥事你还不知道。这些都是面向对象不太好的地方。
原型(Prototype)
基于原型(Prototype)的编程其实也是面向对象编程的一种方式。没有 class 化的,直接使用对象。又叫,基于实例的编程。其主流的语言就是 JavaScript,与传统的面对象编程的比较如下:
- 在基于类的编程当中,对象总共有两种类型。类定义了对象的基本布局和函数特性,而接口是“可以使用的”对象,它基于特定类的样式。在此模型中,类表现为行为和结构的集合,对所有接口来说这些类的行为和结构都是相同的。因而,区分规则首先是基于行为和结构,而后才是状态。
- 原型编程的主张者经常争论说,基于类的语言提倡使用一个关注分类和类之间关系的开发模型。与此相对,原型编程看起来提倡程序员关注一系列对象实例的行为,而之后才关心如何将这些对象划分到最近的使用方式相似的原型对象,而不是分成类。
- 在基于类的语言中,一个新的实例通过类构造器和构造器可选的参数来构造,结果实例由类选定的行为和布局创建模型。
- 在基于原型的系统中构造对象有两种方法,通过复制已有的对象或者通过扩展空对象创建。很多基于原型的系统提倡运行时进行原型的修改,而基于类的面向对象系统只有动态语言允许类在运行时被修改(Common Lisp、Dylan、Objective-C、Perl、Python、Ruby 和 Smalltalk)。
需要解释一下 JavaScript 的两个东西,一个是 __proto__,另一个是 prototype,这两个东西很容易混淆。这里说明一下:
- __proto__ 主要是安放在一个实际的对象中,用它来产生一个链接,一个原型链,用于寻找方法名或属性,等等。
- prototype 是用 new 来创建一个对象时构造 __proto__ 用的。它是构造函数的一个属性。
我们再来看一段代码:
// 一种构造函数写法
function Foo(y) {
this.y = y;
}
// 修改 Foo 的 prototype,加入一个成员变量 x
Foo.prototype.x = 10;
// 修改 Foo 的 prototype,加入一个成员函数 calculate
Foo.prototype.calculate = function (z) {
return this.x + this.y + z;
};
// 现在,我们用 Foo 这个原型来创建 b 和 c
var b = new Foo(20);
var c = new Foo(30);
// 调用原型中的方法,可以得到正确的值
b.calculate(30); // 60
c.calculate(40); // 80
那么,在内存中的布局是怎么样的呢?大概是下面这个样子。
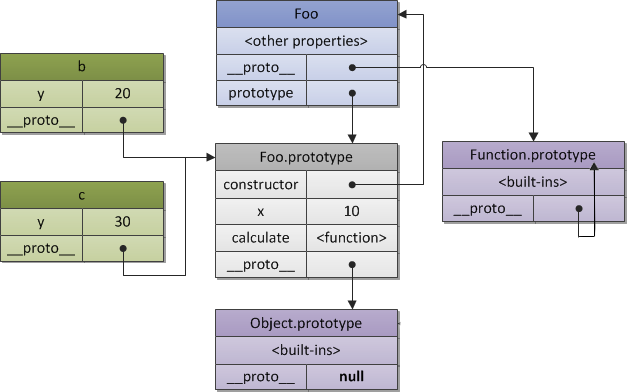
我们可以简单地认为,__proto__ 是所有对象用于链接原型的一个指针,而 prototype 则是 Function 对象的属性,其主要是用来当需要new一个对象时让 __proto__ 指针所指向的地方。 对于超级对象 Function 而言, Function.__proto__ 就是 Function.prototype。
第四部分:编程本质和逻辑编程
如果将 Logic 和 Control 部分有效地分开,那么代码就会变得更容易改进和维护。
编程的本质
两位老先生的两个表达式:
- Programs = Algorithms + Data Structures
- Algorithm = Logic + Control
第一个表达式倾向于数据结构和算法,它是想把这两个拆分,早期都在走这条路。他们认为,如果数据结构设计得好,算法也会变得简单,而且一个好的通用的算法应该可以用在不同的数据结构上。
第二个表达式则想表达的是数据结构不复杂,复杂的是算法,也就是我们的业务逻辑是复杂的。我们的算法由两个逻辑组成,一个是真正的业务逻辑,另外一种是控制逻辑。程序中有两种代码,一种是真正的业务逻辑代码,另一种代码是控制我们程序的代码,叫控制代码,这根本不是业务逻辑,业务逻辑不关心这个事情
通过这两个表达式,我们可以得出:
Program = Logic + Control + Data Structure
前面讲了这么多的编程范式,或是程序设计的方法。其实,我们都是在围绕着这三件事来做的。比如:
- 就像函数式编程中的Map/Reduce/Filter,它们都是一种控制。而传给这些控制模块的那个 Lambda 表达式才是我们要解决的问题的逻辑,它们共同组成了一个算法。最后,我再把数据放在数据结构里进行处理,最终就成为了我们的程序。
- 就像我们 Go 语言的委托模式的那个 Undo 示例一样。Undo 这个事是我们想要解决的问题,是 Logic,但是 Undo 的流程是控制。
- 就像我们面向对象中依赖于接口而不是实现一样,接口是对逻辑的抽象,真正的逻辑放在不同的具现类中,通过多态或是依赖注入这样的控制来完成对数据在不同情况下的不同处理。
如果你再仔细地结合我们之前讲的各式各样的编程范式来思考上述这些概念的话,你是否会觉得,所有的语言或编程范式都在解决上面的这些问题。也就是下面的这几个事。
- Control 是可以标准化的。比如:遍历数据、查找数据、多线程、并发、异步等,都是可以标准化的。
- 因为 Control 需要处理数据,所以标准化 Control,需要标准化 Data Structure,我们可以通过泛型编程来解决这个事。
- 而 Control 还要处理用户的业务逻辑,即 Logic。所以,我们可以通过标准化接口 / 协议来实现,我们的 Control 模式可以适配于任何的 Logic。
上述三点,就是编程范式的本质。
- 有效地分离 Logic、Control 和 Data 是写出好程序的关键所在!
- 有效地分离 Logic、Control 和 Data 是写出好程序的关键所在!
- 有效地分离 Logic、Control 和 Data 是写出好程序的关键所在!
这就是编程的本质:
- Logic 部分才是真正有意义的(what to do)
- Control 部分只是影响 Logic 部分的效率(how to do)
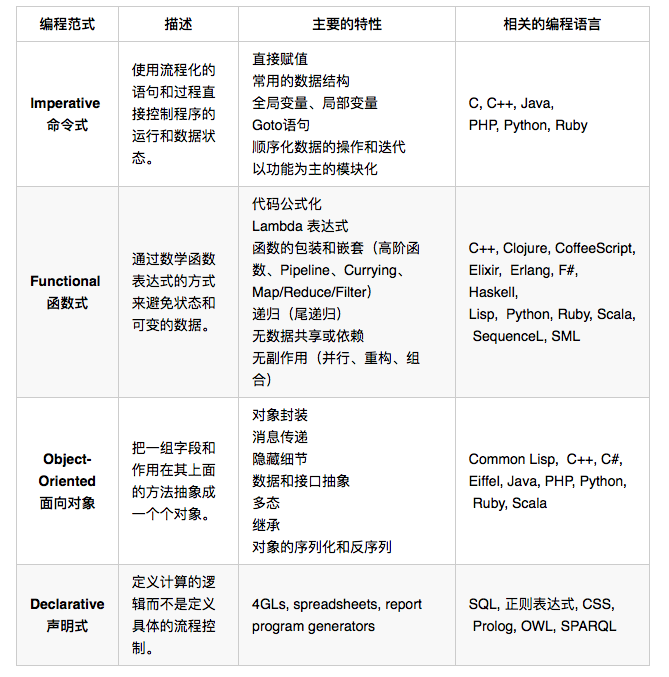
下面再结合一张表格说明一下这世界上四大编程范式的类别,以及它们的特性和主要的编程语言。