

1.栈
栈是一种只能从表的一端存取数据且遵循 "先进后出" 原则的线性存储结构。栈的结构示意图如下:

栈的开口端被称为栈顶;相应地,封口端被称为栈底。
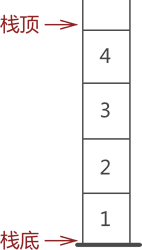
基于栈结构的特点,在实际应用中,通常只会对栈执行以下两种操作: 向栈中添加元素,此过程被称为"进栈"(入栈或压栈); 从栈中提取出指定元素,此过程被称为"出栈"(或弹栈);
2.顺序栈
顺序栈,即用顺序表实现栈存储结构。通top作为下标来标记栈顶元素进行操作。 代码实现及操作如下:
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
#define MAXSIZE 20 /* 存储空间初始分配量 */
typedef int Status;
typedef int SElemType; /* SElemType类型根据实际情况而定,这里假设为int */
/* 顺序栈结构 */
typedef struct
{
SElemType data[MAXSIZE];
int top; /* 用于栈顶指针 */
}SqStack;
2.1构建一个空栈
Status InitStack(SqStack *S){
//topc初始为-1,栈底下标为0
S->top = -1;
return OK;
}
2.2置空
Status ClearStack(SqStack *S){
//疑问: 将栈置空,需要将顺序栈的元素都清空吗?
//不需要,只需要修改top就可以了。 数据会覆盖,清空会把栈销毁了。
S->top = -1;
return OK;
}
2.3 判断顺序栈是否为空;
根据下标判断
Status StackEmpty(SqStack S){
if (S.top == -1)
return TRUE;
else
return FALSE;
}
2.4 返回栈的长度
长度为top+1
int StackLength(SqStack S){
return S.top + 1;
}
2.5 获取栈顶元素
传入e的地址,用于将值带回
Status GetTop(SqStack S,SElemType *e){
if (S.top == -1)
return ERROR;
else
*e = S.data[S.top];
return OK;
}
2.6 压栈push
Status PushData(SqStack *S, SElemType e){
//栈已满
if (S->top == MAXSIZE -1) {
return ERROR;
}
//栈顶指针+1;
S->top ++;
//将新插入的元素赋值给栈顶空间
S->data[S->top] = e;
return OK;
}
2.7 出栈pop
Status Pop(SqStack *S,SElemType *e){
//空栈,则返回error;
if (S->top == -1) {
return ERROR;
}
//将要删除的栈顶元素赋值给e
*e = S->data[S->top];
//栈顶指针--;
S->top--;
return OK;
}
2.8 遍历
Status StackTraverse(SqStack S){
int i = 0;
printf("此栈中所有元素");
while (i<=S.top) {
printf("%d ",S.data[i++]);
}
printf("\n");
return OK;
}
3.链栈
链栈,即用链表实现栈存储结构。
链栈的实现思路同顺序栈类似,顺序栈是将数顺序表(数组)的一端作为栈底,另一端为栈顶;链栈也如此,通常我们将链表的头部作为栈顶,尾部作为栈底。

链表的头部作为栈顶,意味着: 在实现数据"入栈"操作时,需要将数据从链表的头部插入; 在实现数据"出栈"操作时,需要删除链表头部的首元节点;
因此,链栈实际上就是一个只能采用头插法插入或删除数据的链表。
代码实现如下:
//链栈元素结构
typedef struct StackNode
{
SElemType data;
struct StackNode *next;
}StackNode,*LinkStackPtr;
//链栈
typedef struct
{
LinkStackPtr top;
int count;
}LinkStack;
3.1初始化
Status InitStack(LinkStack *S)
{
S->top=NULL;
S->count=0;
return OK;
}
3.2置空
Status ClearStack(LinkStack *S){
LinkStackPtr p,temp;
p = S->top;
while (p) {
temp = p->next;
free(p);//需要释放结点
p = temp;
}
S->count = 0;
return OK;
}
3.3 判断顺序栈是否为空;
根据元素数目判断
Status StackEmpty(LinkStack S){
if (S.count == 0)
return TRUE;
else
return FALSE;
}
3.4 返回栈的长度
元素个数,即为栈的长度。
int StackLength(LinkStack S){
return S.count;
}
3.5 获取栈顶元素
若链栈S不为空,则用e返回栈顶元素,并返回OK ,否则返回ERROR
Status GetTop(LinkStack S,SElemType *e){
if(S.top == NULL)
return ERROR;
else
*e = S.top->data;
return OK;
}
3.6 压栈push
采用头插法
Status Push(LinkStack *S, SElemType e){
//创建新结点temp
LinkStackPtr temp = (LinkStackPtr)malloc(sizeof(StackNode));
//赋值
temp->data = e;
//把当前的栈顶元素赋值给新结点的直接后继
temp->next = S->top;
//将新结点temp 赋值给栈顶指针
S->top = temp;
S->count++;
return OK;
}
3.7 出栈pop
若栈不为空,则删除S的栈顶元素,用e返回其值. 并返回OK,否则返回ERROR
Status Pop(SqStack *S,SElemType *e){
//空栈,则返回error;
if (S->top == -1) {
return ERROR;
}
//将要删除的栈顶元素赋值给e
*e = S->data[S->top];
//栈顶指针--;
S->top--;
return OK;
}
3.8 遍历
Status StackTraverse(LinkStack S){
LinkStackPtr p;
p = S.top;
while (p) {
printf("%d ",p->data);
p = p->next;
}
printf("\n");
return OK;
}
4.递归
什么是递归?如果在一个函数,过程或数据结构定义的内部又直接(或间接)出现定义本身的应用,则称他们是递归的,或者递归定义。
4.1递归解决哪些问题
在下⾯3种情况下,我们会使⽤到递归来解决问题:
4.1.1定义是递归的
⽐如很多数学定义本身就是递归定义; 例如⼤家⾮常熟悉的阶乘,斐波那契数列;
阶乘Fact(n)
(1) 若n = 0,则返回1;
(2) 若n > 1,则返回 n*Fact(n-1);
long Fact(Long n){
if(n=0) return -1;
else return n * Fact(n-1);
}
⼆阶斐波拉契数列Fib(n)
(1) 若n = 1或者n = 2, 则返回1;
(2) 若n > 2,则Fib(n-1) + Fib(n-2);
long Fib(Long n){
if(n == 1 || n == 2)
return 1;
else
return Fib(n-1)+Fib(n-2);
}
对于类似这种复杂问题,若能够分解成⼏个简单且解法相同或类似的⼦问题,来求解,便称为递归求解.
例如,在求解4!时先求解3!,然后再进⼀步分解进⾏求解, 这种求解⽅式叫做"分治法".
采取"分治法"进⾏递归求解的问题需满⾜以下三个条件: 能将⼀个问题转换变成⼀个⼩问题,⽽新问题和原问题解法相同或类同. 不同的仅仅是处理的对象, 并且 这些处理更⼩且变化有规律的.
可以通过上述转换⽽使得问题简化 必须有⼀个明确的递归出⼝, 或称为递归边界.
void p(参数表){
if(递归结束条件成⽴) 可直接求解; //递归终⽌条件
else p(较⼩的参数); //递归步骤
}
4.1.2数据结构是递归的.
其数据结构本身具有递归的特性.
例如,对于链表,其结点LNode的定义由数据域data 和指针域next 组成,⽽指针域next是⼀种指向LNode类 型的指针,即LNode的定义中⼜⽤到了其⾃身. 所以链表是⼀种递归的数据结构;
void TraverseList(LinkList p){
//递归终⽌
if(p == NULL) return;
else{
//输出当前结点的数据域
printf("%d",p->data); 8 //p指向后继结点继续递归
TraverseList(p->next);
}
}
总结, 在递归算法中, 如果当递归结束条件成⽴,只执⾏return 操作时,分治法求解递归问题算法⼀般形式可 以简化为:
void p(参数表){
if(递归结束条件不成⽴)
p(较⼩参数);
}
void TraverseList(LinkList p){
if(p){
printf("%d",p->data); 5 TraverseList(p->next);
}
}
4.1.3问题的解法是递归的
有⼀类问题,虽然问题本身并没有明显的递归结构,但是采样递归求解⽐迭代求解更简单, 如Hanoi塔问题,⼋ 皇后问题,迷宫问题.
4.2 递归过程与递归⼯作栈
⼀个递归函数,在函数的执⾏过程中,需要多次进⾏⾃我调⽤. 那么思考⼀下,⼀共递归函数是如何执⾏的?
在了解递归函数是如何执⾏之前,先来了解⼀下任何的2个函数之间调⽤是如何进⾏的; 在⾼级语⾔的程序中,调⽤函数和被调⽤的函数之间的链接与信息交换都是通过栈来进⾏的.
通常,当在⼀个函数的运⾏期间调⽤另⼀个函数时, 在运⾏被调⽤函数之前, 系统需要先完成3件事情: 1. 将所有的实参,返回地址等信息调⽤传递被调⽤函数保存; 2. 为被调⽤函数的局部变量分配存储空间 3. 将控制转移到被调函数⼊⼝; ⽽从被调⽤函数返回调⽤函数之前,系统同样需要完成3件事:
- 保存被调⽤函数的计算结果;
- 释放被调⽤函数的数据区
- 依照被调⽤函数保存的返回地址将控制移动到调⽤函数.
当多个函数构成嵌套调⽤时, 按照"先调⽤后返回"的原则, 上述函数之间的信息传递和控制转移必须通 过"栈"来实现. 即系统将整个程序运⾏时的所需要的数据空间都安排在⼀个栈中, 每当调⽤⼀个函数时,就在 它的栈顶分配⼀个存储区. 每当这个函数退出时,就释放它的存储区.则当前运⾏时的函数的数据区必在栈顶.
int second(int d){
int x,y;
//...
}
int first(int s,int t){
int i;
//...
second(i)
//2.⼊栈
//...
}
void main(){
int m,n;
first(m,n);
//1.⼊栈
//...
}
在主函数main中调⽤函数first, ⽽在函数first ⼜嵌套调⽤了second 函数. 则,当我们执⾏当前在执⾏的firt 函数时,则栈空间⾥保存了这些信息; ⽽当我们执⾏second则图(b)保存了这些信息.
⼀个递归函数的运⾏过程类似多个函数嵌套调⽤; 只是调⽤函数和被调⽤函数是同⼀个函数. 因此, 和每次 调⽤相关的⼀个重要概念是递归函数运⾏的"层次". 假设调⽤该递归函数的主函数为第0层, 则从主函数调 ⽤递归函数进⼊第1层, 从第i层递归调⽤本函数为进⼊下⼀层.即第i+1层. 反正退出第i层递归应返回上⼀层, 即第i-1层.
为了保证递归函数正确执⾏, 系统需要设⽴⼀个"递归⼯作栈"作为整个递归函数运⾏期间使⽤的数据存储 区. 每⼀层递归所需信息构成⼀个⼯作记录, 其中包括所有的实参,所有的局部变量以及上⼀层的返回地址.
每进⼊⼀层递归, 就产⽣⼀个新的⼯作记录压⼊栈顶. 每退出⼀个递归,就从栈顶弹出⼀个⼯作记录, 则当前 执⾏层的⼯作记录必须是递归⼯作栈栈顶的⼯作记录, 称为"活动记录".
