

动态处理数据的鉴别器--discriminator元素

简单了解discriminator元素
除了association元素和collection元素之外,resultMap还有一个用于配置复杂映射关系的discriminator元素.
按照官方文档的介绍来看,他和java语言的switch语句类似:
有时候,一个数据库查询可能会返回多个不同的结果集(但总体上还是有一定的联系的)。
鉴别器(discriminator)元素就是被设计来应对这种情况的,另外也能处理其它情况,例如类的继承层次结构。
鉴别器的概念很好理解——它很像 Java 语言中的 switch 语句。

官方介绍有些抽象,但是不难理解,简单来说,discriminator元素可以在运行时根据查询到的数据列值的不同来执行不同的映射处理逻辑.
接触一下discriminator元素的简单用法
实践出真知,有些时候描述起来很抽象的东西,实际使用起来会发现格外简单,比如discriminator元素.
下面是一个真实的业务流程--微信公众号的注册:
微信公众平台的注册页面:
我们以订阅号的注册为例:
在输入了邮箱和密码之后,我们选择账户类型为订阅号:
然后选择不同的主体进行认证:
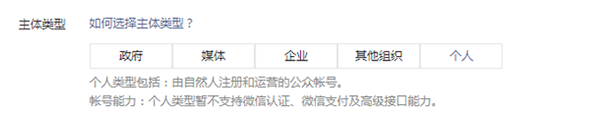
根据我们选择的主体类型不同,我们需要上传的认证信息也不同,比如当我们选择主体为个人时:
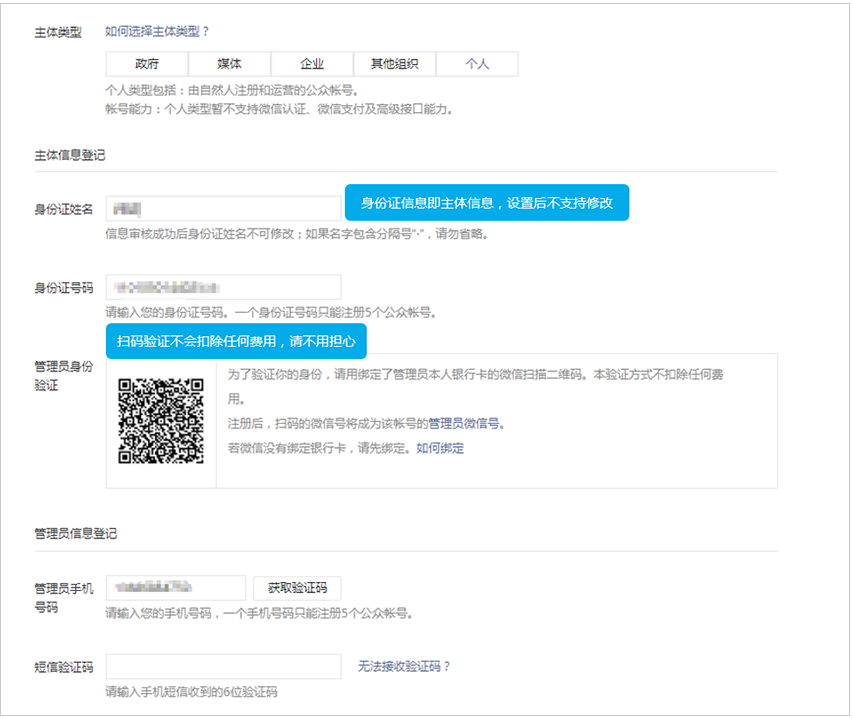
我们需要上传的主要是用户的身份证信息.
如果我们选择的主体是企业,我们需要上传的则主要是企业信息:
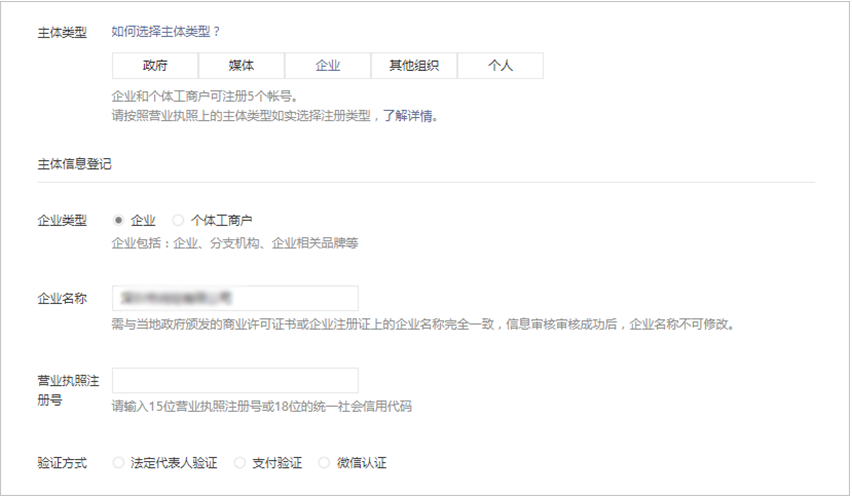
微信注册流程文档:kf.qq.com/product/wei…
在上面这个业务中,用户的认证信息会因为用户主体类型的不同而发生变化.
我们以这种业务场景为例,简单介绍一下discriminator元素的用法:
我们在单元测试learning包下新建一个包org.apache.learning.result_map.discriminator来存放我们的示例代码.
首先我们定义一个主体接口Subject,该接口是一个空实现,主要起标识作用:
public interface Subject {
}
针对个人主体和企业主体分别提供Person和Company两个类型定义:
@Data
public class Person implements Subject {
/**
* 唯一标志
*/
private Integer id;
/**
* 姓名
*/
private String name;
/**
* 身份证号
*/
private String idCard;
}
@Data
public class Company implements Subject {
/**
* 唯一标志
*/
private Integer id;
/**
* 企业名称
*/
private String name;
/**
* 营业执照
*/
private String businessLicense;
}
Person和Company均实现了Subject接口:
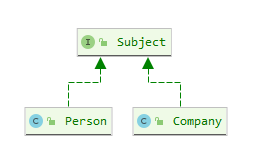
抽象出我们的基本用户对象User:
@Data
public class User {
/**
* 唯一标志
*/
private Integer id;
/**
* 邮箱
*/
private String email;
/**
* 主体类型
*/
private String subjectType;
/**
* 主体唯一标志
*/
private Integer subjectId;
/**
* 主体信息
*/
private Subject subject;
}
User对象的subjectType属性有两个取值:PERSON和COMPANY,分别对应Person和Company类型定义.
提供一个数据初始化脚本CreateDB.sql:
/* ======================== 插入用户数据 =============================*/
drop table USER if exists;
create table USER
(
id int,
email varchar(20),
subject_type varchar(20),
subject_id int
);
insert into USER (id, email,subject_type,subject_id) values (1, 'person@jpanda.cn', 'PERSON',1);
insert into USER (id, email,subject_type,subject_id) values (2, 'company@jpanda.cn', 'COMPANY',1);
/* ======================== 插入主体数据 =============================*/
drop table PERSON if exists;
create table PERSON
(
id int,
name varchar(20),
id_card varchar(20)
);
insert into PERSON (id, name,id_card) values (1, 'JPANDA', '666666');
drop table COMPANY if exists;
create table COMPANY
(
id int,
name varchar(20),
business_license varchar(20)
);
insert into COMPANY (id, name,business_license) values (1, 'JPANDA-COMPANY', 'P_C_666666');
涉及到的数据如下:
-
用户表(
USER)的数据:id email subject_type subject_id 1 person@jpanda.cn PERSON 1 2 company@jpanda.cn COMPANY 1 -
主体-个人表(
PERSON)的数据:id name id_card 1 JPANDA 666666 -
主体-企业表(
COMPANY)的数据:id name business_license 1 JPANDA-COMPANY P_C_666666
完成数据准备工作之后,我们新建一个DiscriminatorMapper接口,及其对应的DiscriminatorMapper.xml配置文件:
DiscriminatorMapper接口定义:
public interface DiscriminatorMapper {
User selectUserById(Integer id);
}
DiscriminatorMapper.xml配置文件:
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.apache.learning.result_map.discriminator.DiscriminatorMapper">
<!-- 查询个人主体 -->
<select id="selectPersonById" resultType="org.apache.learning.result_map.discriminator.Person">
SELECT *
FROM PERSON
WHERE id = #{id}
</select>
<!-- 查询企业主体 -->
<select id="selectCompanyById" resultType="org.apache.learning.result_map.discriminator.Company">
SELECT *
FROM COMPANY
WHERE id = #{id}
</select>
<resultMap id="user" type="org.apache.learning.result_map.discriminator.User" autoMapping="true">
<!-- 使用鉴别器根据用户主体类型的不同从不同的表中获取主体信息 -->
<discriminator column="subject_type" javaType="String">
<case value="PERSON">
<!-- 个人主体信息 -->
<association property="subject" column="{id=subject_id}" select="selectPersonById"/>
</case>
<case value="COMPANY">
<!-- 企业主体信息 -->
<association property="subject" column="{id=subject_id}" select="selectCompanyById"/>
</case>
</discriminator>
</resultMap>
<!-- 查询用户信息 -->
<select id="selectUserById" resultMap="user">
SELECT *
FROM USER
WHERE id = #{id}
</select>
</mapper>
DiscriminatorMapper.xml配置文件看起来内容很多,但是实际上做的事情很简单.

我们用三个简单的select元素配置来分别从USER,PERSON,COMPANY三个表中根据ID属性读取相应的数据.
然后配置了一个名为user的resultMap元素,根据该元素的配置,mybatis在运行时将会根据USER表中subject_type列的取值来决定是从PERSON表还是COMPANY表中获取当前用户所需的主体信息.
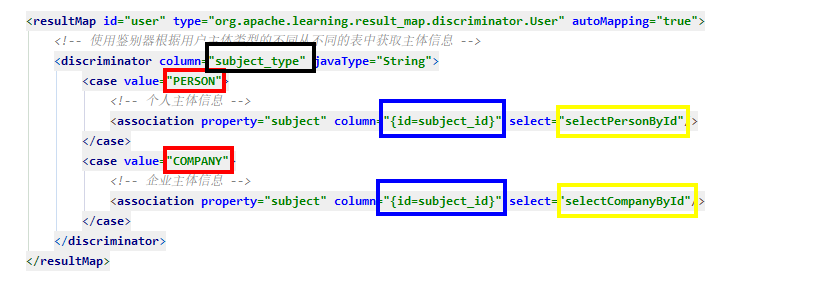
配置中的关键信息,我已经标注出来,在后面的内容中会介绍他们的作用.
最后,我们编写一个单元测试对象DiscriminatorMapperTest,来检验一下鉴别器是否能够按照预期工作:
@Slf4j
public class DiscriminatorMapperTest {
private static SqlSessionFactory sqlSessionFactory;
@BeforeEach
@SneakyThrows
public void setup() {
String currentDir = getClass().getPackage().getName().replaceAll("\\.", "/").concat("/");
@Cleanup
Reader reader = Resources
.getResourceAsReader(currentDir.concat("mybatis-config.xml"));
sqlSessionFactory = new SqlSessionFactoryBuilder().build(reader);
BaseDataTest.runScript(sqlSessionFactory.getConfiguration().getEnvironment().getDataSource(), currentDir.concat("CreateDB.sql"));
}
@Test
public void simpleDiscriminatorTest() {
/* 启用下划线转驼峰的功能 */
sqlSessionFactory.getConfiguration().setMapUnderscoreToCamelCase(true);
sqlSessionFactory.getConfiguration().addMapper(DiscriminatorMapper.class);
@Cleanup
SqlSession sqlSession = sqlSessionFactory.openSession();
/* ID为1用户,主体类型为'PERSON',因此,他的主体应该是Person对象*/
DiscriminatorMapper discriminatorMapper = sqlSession.getMapper(DiscriminatorMapper.class);
User personUser = discriminatorMapper.selectUserById(1);
log.debug("PersonUser={}", personUser);
assert personUser.getSubject() instanceof Person;
/* ID为2用户,主体类型为'COMPANY',因此,他的主体应该是Company对象*/
User companyUser = discriminatorMapper.selectUserById(2);
assert companyUser.getSubject() instanceof Company;
log.debug("CompanyUser={}", companyUser);
}
}
simpleDiscriminatorTest()方法正确运行,并得到下列关键日志信息:
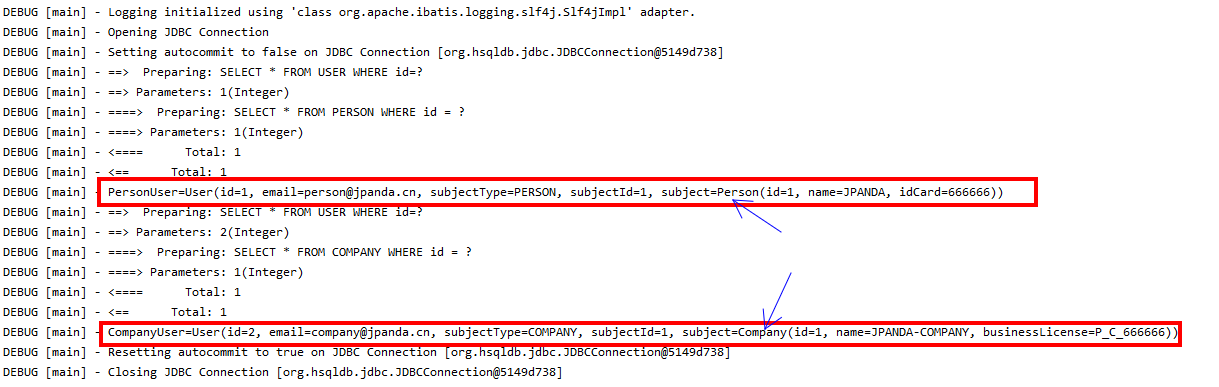
查看上面的日志,我们可以发现DiscriminatorMapper的selectUserById()方法在运行时根据USER表中subject_type列取值的不同执行了不同的查询操作.

而这只是discriminator元素的一个简单应用,管中窥豹,足以体现出discriminator元素的强大之处.
discriminator元素的定义
discriminator元素的DTD定义并不复杂:
<!ELEMENT resultMap ( ... discriminator?)>
<!ELEMENT discriminator (case+)>
<!ATTLIST discriminator
column CDATA #IMPLIED
javaType CDATA #REQUIRED
jdbcType CDATA #IMPLIED
typeHandler CDATA #IMPLIED
>
在一个resultMap元素中只允许配置一个discriminator元素,discriminator元素只有一个子元素和四个属性定义,其中column和javaType这两个属性在前面的示例中我们已经有过简单的使用:
虽然在DTD定义中,column属性是可选的,但是在实际使用中column和javaType都是必填的,如果你不传column属性,那么你就会得到一个异常:
java.lang.IllegalStateException: Mapping is missing column attribute for property null
根据官方文档的介绍:
column 指定了 MyBatis 查询被比较值的地方。 而 javaType 用来确保使用正确的相等测试(虽然很多情况下字符串的相等测试都可以工作)。
简单来说就是,column属性用于指定具体哪一列数据将会被用于数据对比操作,javaType属性则指定了这一列数据将会被转换为哪一种java类型来执行对比操作.
代入到上面的示例代码中,mybatis在查询出USER对应的数据记录之后,会将subject_type列的值转换为javaType属性指向的String对象进行对比操作,选择一个合适的case分支,进一步执行数据映射操作.
其实,discriminator元素的javaType,jdbcType以及typeHandler这三个属性存在的目的是一致的,就是让myabtis通过这三个属性能够推断出一个TypeHandler实例,然后用获取到的TypeHandler实例将数据列的值转换为具体对象来进行对比操作.
因此,我们会发现在我们指定了typeHandler属性的值之后,javaType属性就失去了他应有的效用.
关于更多关于鉴别器的处理细节,我们将会在解析过程中逐步了解.
discriminator元素还有一个case子元素:
<!ELEMENT case (constructor?,id*,result*,association*,collection*, discriminator?)>
<!ATTLIST case
value CDATA #REQUIRED
resultMap CDATA #IMPLIED
resultType CDATA #IMPLIED
>
case子元素的子元素定义和resultMap也是完全一样,因此,case子元素和association以及collection一样,也是一个特殊的resultMap对象.
case子元素有三个属性定义,其中必填的value属性和discriminator元素column属性相对应,discriminator元素column属性指向的列的取值将会同value属性的值对比,如果二者一致,则当前case元素对应的映射关系将会被处理.
多个
case子元素之间的关系是互斥的,因此,在一条数据记录中,同一discriminator元素下的多个case元素只会有一个生效.
除了value属性之外,case子元素还有resultMap和resultType两个属性定义,其中,属性resultMap指向了一个标准的resultMap元素配置.
接下来就比较有意思了,resultType理论上应该指向一个标准的java类型,但是实际上该属性不会被处理,也就是说resultType属性是一个无效的属性定义.

总结
功能强大的discriminator元素涉及的新知识点并不多,现在我们总结一下.
discriminator元素可以在运行时根据查询到的数据列值的不同来执行不同的映射处理逻辑.
他有四个属性定义,其中column指定了用于提供判断依据的数据列名称,javaType,jdbcType以及typeHandler则用于推断出一个TypeHandler实例获取到的TypeHandler实例将数据列的值转换为具体对象来进行对比操作.
discriminator元素还有一个case子元素定义,case子元素用来声明在某种条件下需要指定的映射处理操作.
case子元素也是一种特殊的resultMap,他有三个属性定义,其中必填的value属性和discriminator元素column属性相对应,用于做判断操作.
属性resultMap指向了一个标准的resultMap元素配置,而resultType属性是一个无效的属性定义.
上面就是discriminator元素涉及到的相关内容了.
就酱!告辞!

关注我,一起学习更多知识

