

1、决策树基本问题
1.1 定义

我们应该设计什么的算法,使得计算机对贷款申请人员的申请信息自动进行分类,以决定能否贷款?
一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
决策过程:

这个女孩的决策过程就是典型的分类树决策。相当于通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见
决策树是一种描述对样本实例(男人)进行分类(见或不见)的树形结构。
决策树由结点和有向边组成。最上部是根节点,此时所有样本都在一起,经过该节点后样本被划分到各子节点中。每个子节点再用新的特征来进一步决策,直到最后的叶节点。叶节点上只包含单纯一类样本(见或不见),不需要在进行划分。
结点两种类型:内部结点和叶结点。
内部结点表示一个特征或属性,叶节点表示一个类。
1.2 熵
首先,我们该选择什么标准(属性、特征)作为我们的首要条件(根节点)对样本(男人)进行划分,决定见或不见呢?——特征选择
母亲希望女儿能最快速的有一个明确的态度,决定见或不见,这样好给男方一个明确的答复。
母亲需要获得尽可能多的信息,减少不确定性。
信息的如何度量?——熵
母亲得到信息越多,女儿的态度越明确,与男方见与不见的不确定性越低。因此,信息量与不确定性相对应。使用熵来表示不确定性的度量。
熵定义:如果一件事有k种可的结果,每种结果的概率为

则我们对此事件的结果进行观察后得到的信息量为:

熵越大,随机变量(见与不见)的不确定性越大。
1.3 条件熵(局部,现象发生的前提下的熵)
条件熵H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性。例如,知道男生年龄的前提条件下,根据女儿见与不见的不确定性。

熵与条件熵中概率由数据估计得到时,所对应的熵和条件熵称为经验熵和经验条件熵。若概率为0,令0log0=0
1.4 信息增益
信息增益表示得知特征X(年龄)的信息使得类Y(见与不见)的信息的不确定性减少程度。
特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下的经验条件熵H(D|A)之差

熵H(Y)与条件熵H(Y|X)之差称为互信息,即g(D,A)。
信息增益大表明信息增多,信息增多,则不确定性就越小,母亲应该选择使得信息增益增大的条件询问女儿。
1.5 信息增益准则的特征选择方法
对数据集D,计算每个特征的信息增益,并比较他们的大小,选择信息增益最大的特征。
1.6 信息增益率
信息增益率定义:特征A对训练数据集D的信息增益比定义为其信息增益与训练数据D关于特征A的值的熵HA(D)之比



2 ID3
2.1 ID3 的定义
ID3算法的核心是在决策树各个子节点上应用信息增益准则选择特征,递归的构建决策树,具体方法是:从根节点开始,对节点计算所有可能的特征的信息增益,选择信息增益最大的特征作为节点的特征,由该特征的不同取值建立子节点;再对子节点递归调用以上方法,构建决策树。
直到所有特征的信息增益均很小或没有特征可以选择为止。最后得到一个决策树。
例子:贷款申请样本数据表

根据贷款申请样本数据表,我们有15条样本记录,则样本容量为15。最终分为是否贷款2个类,其中是有9条记录,否有6条记录。有年龄、有工作、有自己的房子和信贷情况4个不同特征。每个特征有不同的取值,如年龄有老、中、青3种取值。
由熵的定义:

计算经验熵:

然后计算各特征对数据集D的信息增益。分别以A1,A2,A3,A4表示年龄、有工作、有自己的房子和信贷情况4个特征。
根据年龄有取值青年、中年、老年。
青年贷款是2条记录,否3条记录,共5条记录
中年贷款是3条记录,否2条记录,共5条记录
老年贷款是4条记录,否1条记录,共5条记录
由条件熵公式

条件熵公式

年龄为已知条件的条件熵为

D1,D2,D3分别是年龄取值为青年、中年、老年的样本子集。
以年龄为条件的信息增益为

有工作的信息增益

有房子的信息增益

信贷情况的信息增益

最后比较各特征的信息增益值,对于特征A3有自己房子的信息增益值最大,所以选择特征A3作为最优特征。
由于特征A3(有自己房子)的信息增益值最大,所以选择特征A3作为根节点的特征。它将训练数据集划分为两个子集D1(A3取值为是)和D2(A3取值为否)。由于D1只有同一类样本点,可以明确要贷款给D1,所以它成为一个叶节点,节点类标记为“是”。
对于D2则需要从特征A1(年龄),A2(有工作)和A4(信贷情况)中选择新的特征。计算各个特征的信息增益:



选择信息增益最大的特征A2(有工作)作为节点特征。A2有2个取值,一个对应“是”(有工作)的子节点,包含3个样本,他们属于同一类,所以这是一个叶节点,类标记为“是”;另一个对应“否”(无工作)的子节点,包含6个样本,属于同一类,这也是一个叶节点,类标记为“否”。
换句话有15个贷款人,经过是否有房这一筛选条件,有房子的6个人能够贷款。剩余9个人需要进一步筛选,以是否有工作为筛选条件,有工作的3个人可以贷款,无工作的6个人不能够贷款。

该决策树只用了两个特征(有两个内部结点),以有自己的房子作为首要判决条件,然后以有工作作为判决条件是否可以贷款。
ID3算法只有树的生成,所以该算法生成的树容易产生过拟合,分得太细,考虑条件太多。
2.2 ID3 的缺点
1.用信息增益选择属性时偏向于选择分枝比较多的属性值,即取值 多的属性。
2.不能处理连续属性。
2.3 ID3 的代码实现
1)准备训练数据
2)计算信息增益








3)递归构建决策树
其中当所有的特征都用完时,采用多数表决的方法来决定该叶子节点的分类,即该叶节点中属于某一类最多的样本数,那么我们就说该叶节点属于那一类!



运行测试:

4)查看生成的决策树







构造决策树是一个很耗时的任务。为了节省计算时间,最好能够在每次执行分类时调用已经构造好的决策树。为了解决这个问题,需要使用
模块pickle序列化对象,序列化对象可以在磁盘上保存对象,并在需要的时候读取出来。

运行测试:

7)示例:使用决策树预测隐形眼镜类型






3、C4.5
C4.5算法是数据挖掘十大算法之一,它是对ID3算法的改进,相对于ID3算法主要有以下几个改进
(1)用信息增益比来选择属性
(2)在决策树的构造过程中对树进行剪枝
(3)对非离散数据也能处理
(4)能够对不完整数据进行处理
以下例子以ID3的过程为主,穿插着增添了C4.5的特性:
本文采用评价电信服务保障中的满意度预警专题来解释决策树算法,即假如我家办了电信的宽带,有一天宽带不能上网了,于是我打电话给电信报修,然后电信派相关人员进行维修,修好以后电信的回访专员询问我对这次修理障碍的过程是否满意,我会给我对这次修理障碍给出相应评价,满意或者不满意。根据历史数据可以建立满意度预警模型,建模的目的就是为了预测哪些用户会给出不满意的评价。目标变量为二分类变量:满意(记为0)和不满意(记为1)。自变量为根据修理障碍过程产生的数据,如障碍类型、障碍原因、修障总时长、最近一个月发生故障的次数、最近一个月不满意次数等等。简单的数据如下:
客户ID 故障原因 故障类型 修障时长 满意度
001 1 5 10.2 1
002 1 5 12 0
003 1 5 14 1
004 2 5 16 0
005 2 5 18 1
006 2 6 20 0
007 3 6 22 1
008 3 6 23 0
009 3 6 24 1
010 3 6 25 0
故障原因和故障类型都为离散型变量,数字代表原因ID和类型ID。修障时长为连续型变量,单位为小时。满意度中1为不满意、0为满意。
下面沿着分裂属性的选择和树剪枝两条主线,去描述三种决策树算法构造满意度预警模型:
分裂属性的选择:即该选择故障原因、故障类型、修障时长三个变量中的哪个作为决策树的第一个分支。
ID3算法是采用信息增益来选择树叉,c4.5算法采用增益率,CART算法采用Gini指标。此外离散型变量和连续型变量在计算信息增益、增益率、Gini指标时会有些区别。详细描述如下:
1.ID3算法的信息增益:
信息增益的思想来源于信息论的香农定理,ID3算法选择具有最高信息增益的自变量作为当前的树叉(树的分支),以满意度预警模型为例,模型有三个自变量:故障原因、故障类型、修障时长。分别计算三个自变量的信息增益,选取其中最大的信息增益作为树叉。信息增益=原信息需求-要按某个自变量划分所需要的信息。
如以自变量故障原因举例,故障原因的信息增益=原信息需求(即仅仅基于满意度类别比例的信息需求,记为a)-按照故障原因划分所需要的信息需求(记为a1)。
客户ID 故障原因 故障类型 修障时长 满意度
001 1 5 10.2 1
002 1 5 12 0
003 1 5 14 1
004 2 5 16 0
005 2 5 18 1
006 2 6 20 0
007 3 6 22 1
008 3 6 23 0
009 3 6 24 1
010 3 6 25 0
故障原因和故障类型都为离散型变量,数字代表原因ID和类型ID。修障时长为连续型变量,单位为小时。满意度中1为不满意、0为满意。
下面沿着分裂属性的选择和树剪枝两条主线,去描述三种决策树算法构造满意度预警模型:
分裂属性的选择:即该选择故障原因、故障类型、修障时长三个变量中的哪个作为决策树的第一个分支。
ID3算法是采用信息增益来选择树叉,c4.5算法采用增益率,CART算法采用Gini指标。此外离散型变量和连续型变量在计算信息增益、增益率、Gini指标时会有些区别。详细描述如下:
1.ID3算法的信息增益:
信息增益的思想来源于信息论的香农定理,ID3算法选择具有最高信息增益的自变量作为当前的树叉(树的分支),以满意度预警模型为例,模型有三个自变量:故障原因、故障类型、修障时长。分别计算三个自变量的信息增益,选取其中最大的信息增益作为树叉。信息增益=原信息需求-要按某个自变量划分所需要的信息。
如以自变量故障原因举例,故障原因的信息增益=原信息需求(即仅仅基于满意度类别比例的信息需求,记为a)-按照故障原因划分所需要的信息需求(记为a1)。
其中原信息需求a的计算方式为:
其中D为目标变量,此例中为满意度。m=2,即满意和不满意两种情况。Pi为满意度中属于分别属于满意和不满意的概率。此例中共计10条数据,满意5条,不满意5条。概率都为1/2。Info(满意度)即为仅仅基于满意和满意的类别比例进行划分所需要的信息需求,计算方式为:
按照故障原因划分所需要的信息需求(记为a1)可以表示为:
其中A表示目标变量D(即满意度)中按自变量A划分所需要的信息,即按故障类型进行划分所需要的信息。V表示在目标变量D(即满意度)中,按照自变量A(此处为故障原因)进行划分,即故障原因分别为1、2、3进行划分,将目标变量分别划分为3个子集,{D1、D2、D3},因此V=3。即故障原因为1的划分中,有2个不满意和1个满意。D1即指2个不满意和1个满意。故障原因为2的划分中,有1个不满意和2个满意。D2即指1个不满意和2个满意。故障原因为3的划分中,有2个不满意和2个满意。D3即指2个不满意和2个满意。具体公式如下:
注:此处的计算结果即0.165不准确,没有真正去算,结果仅供参考。
因此变量故障原因的信息增益Gain(故障原因)=Info(满意度)- Info故障原因(满意度)=1-0.165=0.835
同样的道理,变量故障类型的信息增益计算方式如下:
=0.205(结果不准,为准确计算)
变量故障类型的信息增益Gain(故障类型)=1-0.205=0.795
故障原因和故障类型两个变量都是离散型变量,按上述方式即可求得信息增益,但修障时长为连续型变量,对于连续型变量该怎样计算信息增益呢?
(此处的方法来自于C4.5)
只需将连续型变量由小到大递增排序,取相邻两个值的中点作为分裂点,然后按照离散型变量计算信息增益的方法计算信息增益,取其中最大的信息增益作为最终的分裂点。如求修障时长的信息增益,首先将修障时长递增排序,即10.2、12、14、16、18、20、22、23、24、25,取相邻两个值的中点,如10.2和12,中点即为(10.2+12)/2=11.1,同理可得其他中点,分别为11.1、13、15、17、19、21、22.5、23.5、24.5。对每个中点都离散化成两个子集,如中点11.1,可以离散化为两个<=11.1和>11.1两个子集,然后按照离散型变量的信息增益计算方式计算其信息增益,如中点11.1的信息增益计算过程如下:
中点11.1的信息增益Gain(修障时长)=1-0.222=0.778
中点13的信息增益计算过程如下:
中点11.1的信息增益Gain(修障时长)=1-1=0
同理分别求得各个中点的信息增益,选取其中最大的信息增益作为分裂点,如取中点11.1。然后与故障原因和故障类型的信息增益相比较,取最大的信息增益作为第一个树叉的分支,此例中选取了故障原因作为第一个分叉。按照同样的方式继续构造树的分支。
总之,信息增益的直观解释为选取按某个自变量划分所需要的期望信息,该期望信息越小,划分的纯度越高。因为对于某个分类问题而言,Info(D)都是固定的,而信息增益Gain(A)=Info(D)-InfoA(D) 影响信息增益的关键因素为:-InfoA(D),即按自变量A进行划分,所需要的期望信息越小,整体的信息增益越大,越能将分类变量区分出来。
由于信息增益选择分裂属性的方式会倾向于选择具有大量值的属性(即自变量),如对于客户ID,每个客户ID对应一个满意度,即按此变量划分每个划分都是纯的(即完全的划分,只有属于一个类别),客户ID的信息增益为最大值1。但这种按该自变量的每个值进行分类的方式是没有任何意义的。为了克服这一弊端,有人提出了采用增益率(GainRate)来选择分裂属性。计算方式如下:
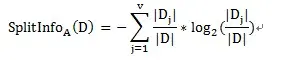
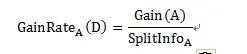
其中Gain(A)的计算方式与ID3算法中的信息增益计算方式相同。
以故障原因为例:
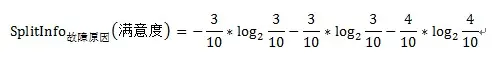
=1.201
Gain(故障原因)=0.835(前文已求得)
GainRate故障原因(满意度)=1.201/0.835=1.438
同理可以求得其他自变量的增益率。
选取最大的信息增益率作为分裂属性。
其中Gain(A)的计算方式与ID3算法中的信息增益计算方式相同。
以故障原因为例:
=1.201
Gain(故障原因)=0.835(前文已求得)
GainRate故障原因(满意度)=1.201/0.835=1.438
同理可以求得其他自变量的增益率。
选取最大的信息增益率作为分裂属性。
4、CART
CART算法选择分裂属性的方式是比较有意思的,首先计算不纯度,然后利用不纯度计算Gini指标。以满意度预警模型为例,计算自变量故障原因的Gini指标时,先按照故障原因可能的子集进行划分,即可以将故障原因具体划分为如下的子集:{1,2,3}、{1,2}、{1,3}、{2,3}、{1}、{2}、{3}、{},共计8(2^V)个子集。由于{1,2,3}和{}对于分类来说没有任何意义,因此实际分为2^V-2共计6个有效子集。然后计算这6个有效子集的不纯度和Gini指标,选取最小的Gini指标作为分裂属性。
不纯度的计算方式为:
pi表示按某个变量划分中,目标变量不同类别的概率。
某个自变量的Gini指标的计算方式如下:
对应到满意度模型中,A为自变量,即故障原因、故障类型、修障时长。D代表满意度,D1和D2分别为按变量A的子集所划分出的两个不同元组,如按子集{1,2}划分,D1即为故障原因属于{1,2}的满意度评价,共有6条数据,D2即故障原因不属于{1,2}的满意度评价,共有3条数据。计算子集{1,2}的不纯度时,即Gini(D1),在故障原因属于{1,2}的样本数据中,分别有3条不满意和3条满意的数据,因此不纯度为1-(3/6)^2-(3/6)^2=0.5。
以故障原因为例,计算过程如下:
=0.5
计算子集故障原因={1,3}的子集的Gini指标时,D1和D2分别为故障原因={1,3}的元组共计7条数据,故障原因不属于{1,3}的元组即故障原因为2的数据,共计3条数据。详细计算过程如下:
=0.52
同理可以计算出故障原因的每个子集的Gini指标,按同样的方式还可以计算故障类型和修障时长每个子集的Gini指标,选取其中最小的Gini指标作为树的分支( Gini(D)越小,则数据集D的纯度越高)。连续型变量的离散方式与信息增益中的离散方式相同。
5、树的剪枝
1)先剪枝:
通过提前停止树的构造,如通过决定在给定的节点不再分裂或划分训练元组的子集,而对树剪枝,一旦停止,该节点即成为树叶。在构造树时,可以使用诸如统计显著性、信息增益等度量评估分裂的优劣,如果划分一个节点的元组低于预先定义阈值的分裂,则给定子集的进一步划分将停止。但选取一个适当的阈值是困难的,较高的阈值可能导致过分简化的树,而较低的阈值可能使得树的简化太少。
2)后剪枝:
2)后剪枝:
它由完全生长的树剪去子树,通过删除节点的分支,并用树叶替换它而剪掉给定节点的子树,树叶用被替换的子树中最频繁的类标记。
其中c4.5使用悲观剪枝方法,CART则为代价复杂度剪枝算法(后剪枝)。
悲观剪枝法的基本思路是:设训练集生成的决策树是T,用T来分类训练集中的N的元组,设K为到达某个叶子节点的元组个数,其中分类错误地个数为J。由于树T是由训练集生成的,是适合训练集的,因此J/K不能可信地估计错误率。所以用(J+0.5)/K来表示。设S为T的子树,其叶节点个数为L(s),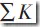 为到达此子树的叶节点的元组个数总和,
为到达此子树的叶节点的元组个数总和,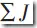 为此子树中被错误分类的元组个数之和。在分类新的元组时,则其错误分类个数为
为此子树中被错误分类的元组个数之和。在分类新的元组时,则其错误分类个数为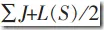 ,其标准错误表示为:
,其标准错误表示为: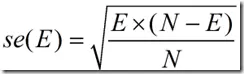 。当用此树分类训练集时,设E为分类错误个数,当下面的式子成立时,则删掉子树S,用叶节点代替,且S的子树不必再计算。
。当用此树分类训练集时,设E为分类错误个数,当下面的式子成立时,则删掉子树S,用叶节点代替,且S的子树不必再计算。





更多免费技术资料可关注:annalin1203
