

B-树 B+树
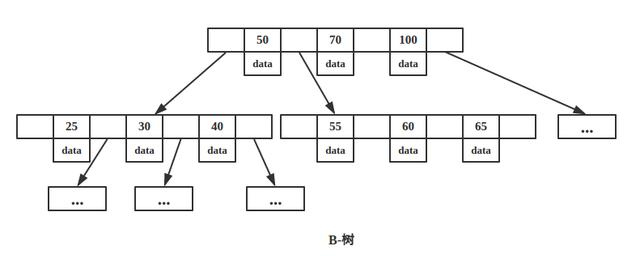
B-树
索引优缺点
优点:
- a.唯一索引,可以保证数据的唯一性。
- b.加快数据的检索速度,这也是创建索引的最主要原因。
- c.加速表和表之间的连接,这在实现数据的参考完整性方面特别有意
- d.在使用分组和排序子句进行数。根据检索时,显著减少查询中分组和排序的时间。
缺点:
- a.创建和维护索引要耗费时间,这种时间随着数据量的增加而增加
- b.除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,需要的空间就会更大。
- c.当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度。
注意事项
- 1、表的主键、外键必须有索引。
- 2、为经常用作查询选择的字段,建立索引;
- 3、经常出现在 Where子句中的字段,特别是大表的字段,应该建立索引。
- 4、在 SQL 语句中经常进行GROUP BY、ORDERBY的字段上建立索引。
- 5、索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引。
- 6、频繁进行数据操作的表,不要建立太多的索引;对于经常存取的列避免建立索引。
- 7、不要在有大量相同取值的字段上,建立索引,如性别。
- 8、创建组合索引时使用最频繁的一列放在最左边。
- 9、组合索引所包含的字段最好不要超过3个。
- 10、删除无用的索引。
慢SQL优化
- 1、当结果集只有一行数据时使用 LIMIT 1;
- 2、避免 SELECT *,始终指定你需要的列;
- 3、使用连接(JOIN)来代替子查询;
- 4、尽量少数据量的条件放在 where 子句前面;
- 5、减少数据库访问次数;
- 6、删除重复记录、
- 7、连接多个表时使用表别名减少解析时间;
- 8、用exists替换distinct(提交一个包含一对多表信息的查询);
- 9、避免在索引列上使用计算;
- 10 避免在索引列上使用 IS NULL 和 IS NOT NULL;
- 11、避免在索引列上使用!=和<>、in、not in。
数据库记录去重方法
- 1)rowid 方法;
- 2)group by 方法;
- 3)distinct 方法
select * from table1 a Where rowid !=(select max(rowid) from table2 b Where a.name1 = b.name1 And a.name2 = b.name2)
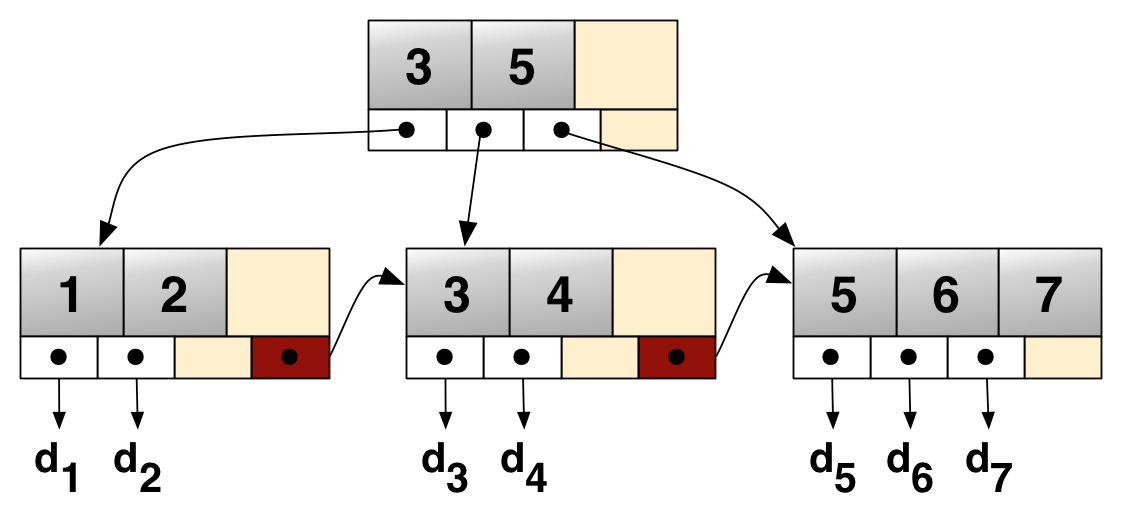
MySQL为什么要使用B+树作为索引
-
1、 B+树的磁盘读写代价更低:B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了。
-
2、B+树的查询效率更加稳定:由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
-
3、由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引。
B树在提高了IO性能的同时并没有解决元素遍历的我效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低。
