

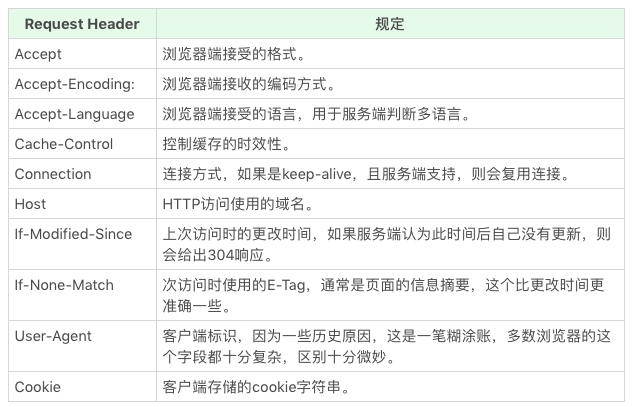
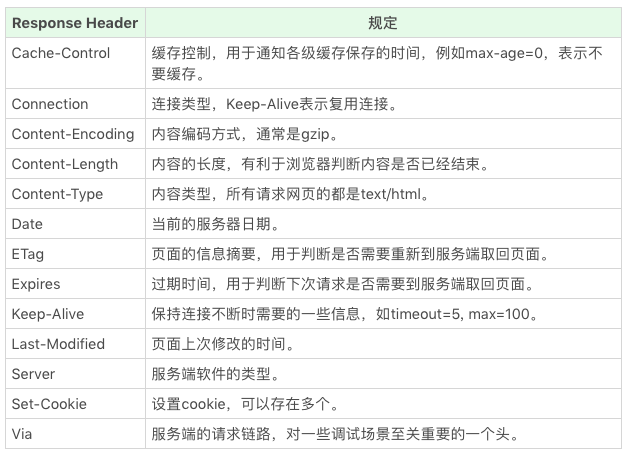
HTTP有哪些常见请求头
HTTP常见状态码
301 302 304 400 500
URL 输入到渲染的过程
- DNS域名解析,根据url找到对应的服务地址
- 三次握手构建 TCP 连接,若有 https,则多一层 TLS 握手,
- 发送HTTP请求
- 服务端响应请求,返回相应的资源文件
- 解析文档
- 构建 DOM 树和 CSSOM(css object modal)
- 生成渲染树render tree:从DOM树的根节点开始遍历每个可见节点,对于每个可见的节点,找到CSSOM树中对应的规则,并应用它们,根据每个可见节点以及其对应的样式,组合生成渲染树
- Layout(回流):根据生成的渲染树,进行回流(Layout),得到节点的集合信息
- Painting(重绘):根据渲染树及其回流得到的集合信息,得到节点的绝对像素。
- 绘制,在页面上展示,这一步还涉及到绘制层级、GPU相关的知识点
- 加载js脚本,加载完成解析js脚本
浏览器渲染过程
参考:zhuanlan.zhihu.com/p/111099605
进程 vs 线程
对于操作系统来说,一个任务就是一个进程,比如打开一个浏览器就是启动了一个浏览器进程,打开一个 Word 就启动了一个 Word 进程。
有些进程同时不止做一件事,比如 Word,它同时可以进行打字、拼写检查、打印等事情。在一个进程内部,要同时做多件事,就需要同时运行多个“子任务”,我们把进程内的这些“子任务”称为线程。一个进程可以包含多个线程。
由于每个进程至少要做一件事,所以一个进程至少有一个线程。系统会给每个进程分配独立的内存,因此进程有它独立的资源。同一进程内的各个线程之间共享该进程的内存空间(包括代码段,数据集,堆等)。
浏览器进程:
主进程 Browser Process
负责浏览器界面的显示与交互。各个页面的管理,创建和销毁其他进程。网络的资源管理、下载等。
第三方插件进程 Plugin Process
每种类型的插件对应一个进程,仅当使用该插件时才创建。
GPU 进程 GPU Process
最多只有一个,用于 3D 绘制等
渲染进程 Renderer Process
称为浏览器渲染进程或浏览器内核,内部是多线程的。主要负责页面渲染,脚本执行,事件处理等。
渲染进程 (浏览器内核)
浏览器的渲染进程是多线程的
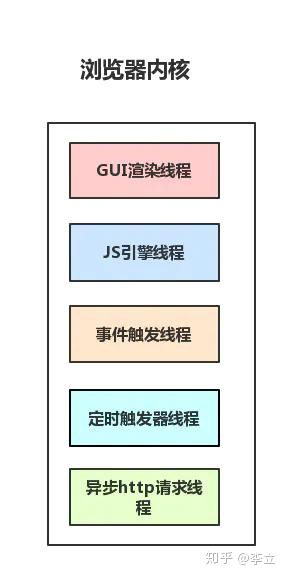
1. GUI渲染线程
- 负责渲染浏览器界面,解析 HTML,CSS,构建 DOM 树和 RenderObject 树,布局和绘制等。
- 当界面需要重绘(Repaint)或由于某种操作引发回流(reflow)时,该线程就会执行。
- 注意,GUI 渲染线程与 JS 引擎线程是互斥的,当 JS 引擎执行时 GUI 线程会被挂起(相当于被冻结了),GUI 更新会被保存在一个队列中等到 JS 引擎空闲时立即被执行。
2. JS 引擎线程
- Javascript 引擎,也称为 JS 内核,负责处理 Javascript 脚本程序。(例如 V8 引擎)
- JS 引擎线程负责解析 Javascript 脚本,运行代码。
- JS 引擎一直等待着任务队列中任务的到来,然后加以处理,一个 Tab 页(renderer 进程)中无论什么时候都只有一个 JS 线程在运行 JS 程序。
- 注意,GUI 渲染线程与 JS 引擎线程是互斥的,所以如果 JS 执行的时间过长,这样就会造成页面的渲染不连贯,导致页面渲染加载阻塞。
3. 事件触发线程
- 归属于浏览器而不是 JS 引擎,用来控制事件循环(可以理解,JS 引擎自己都忙不过来,需要浏览器另开线程协助)
- 当 JS 引擎执行代码块如 setTimeOut 时(也可来自浏览器内核的其他线程,如鼠标点击、AJAX 异步请求等),会将对应任务添加到事件线程中
- 当对应的事件符合触发条件被触发时,该线程会把事件添加到待处理队列的队尾,等待 JS 引擎的处理
- 注意,由于 JS 的单线程关系,所以这些待处理队列中的事件都得排队等待 JS 引擎处理(当 JS 引擎空闲时才会去执行)
4. 定时触发器线程
- 传说中的 setInterval 与 setTimeout 所在线程
- 浏览器定时计数器并不是由 JavaScript 引擎计数的,(因为 JavaScript 引擎是单线程的, 如果处于阻塞线程状态就会影响记计时的准确)
- 因此通过单独线程来计时并触发定时(计时完毕后,添加到事件队列中,等待 JS 引擎空闲后执行)
- 注意,W3C 在 HTML 标准中规定,规定要求 setTimeout 中低于 4ms 的时间间隔算为 4ms。
5. 异步 http 请求线程
- 在 XMLHttpRequest 在连接后是通过浏览器新开一个线程请求。
- 将检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件,将这个回调再放入事件队列中。再由 JavaScript 引擎执行。
http vs https
HTTP是明文传输,因此在传输的每一个环节,数据都有可能被第三方窃取或者篡改,具体来说,HTTP 数据经过 TCP 层,然后经过WIFI路由器、运营商和目标服务器,这些环节中都可能被中间人拿到数据并进行篡改,也就是我们常说的中间人攻击。
HTTPS是在HTTP和TCP之间建立了一个中间层SSL,当HTTP和TCP通信时并不是像以前那样直接通信,直接经过中间层SSL进行加密,将加密后的数据包传给TCP响应的,TCP必须将数据包解密,才能传给上面的HTTP。这个中间层也叫安全层。安全层的核心就是对数据加解密。
对称加密 vs 非对称加密
http2 vs http1
http2 vs http1, 关于http2我说多路复用让解释,感觉自己解释得好像看了假资料。问我http1没有长连接吗?? 有长连接,字段Keep-Alive允许建立一次HTTP连接,来返回多次请求。
HTTP2 和 HTTP1.1 比起来有什么优势
1. HTTP/2采用二进制格式而非文本格式
2. HTTP/2是完全多路复用的,而非有序并阻塞的——只需一个连接即可实现并行
3. 使用报头压缩,HTTP/2降低了开销
4. HTTP/2让服务器可以将响应主动“推送”到客户端缓存中
其中的 多路复用对前端优化性能有很大的帮助
什么是多路复用
在 HTTP 1.1 中,发起一个请求是这样的:
浏览器请求 url -> 解析域名 -> 建立 HTTP 连接 -> 服务器处理文件 -> 返回数据 -> 浏览器解析、渲染文件
这个流程最大的问题是,每次请求都需要建立一次 HTTP 连接,也就是我们常说的3次握手4次挥手,这个过程在一次请求过程中占用了相当长的时间,而且逻辑上是非必需的,因为不间断的请求数据,第一次建立连接是正常的,以后就占用这个通道,下载其他文件,这样效率多高啊!
为了解决这个问题, HTTP 1.1 中提供了 Keep-Alive,允许我们建立一次 HTTP 连接,来返回多次请求数据。
但是这里有两个问题:
HTTP 1.1 基于串行文件传输数据,因此这些请求必须是有序的,所以实际上我们只是节省了建立连接的时间,而获取数据的时间并没有减少
最大并发数问题,假设我们在 Apache 中设置了最大并发数 300,而因为浏览器本身的限制,最大请求数为 6,那么服务器能承载的最高并发数是 50
而 HTTP/2 引入二进制数据帧和流的概念,其中帧对数据进行顺序标识,这样浏览器收到数据之后,就可以按照序列对数据进行合并,而不会出现合并后数据错乱的情况。同样是因为有了序列,服务器就可以并行的传输数据。
HTTP/2 对同一域名下所有请求都是基于流,也就是说同一域名不管访问多少文件,也只建立一路连接。同样Apache的最大连接数为300,因为有了这个新特性,最大的并发就可以提升到300,比原来提升了6倍。
HTTP的options请求
OPTIONS请求方法的主要用途有两个:
1、获取服务器支持的HTTP请求方法;也是黑客经常使用的方法。
2、用来检查服务器的性能。例如:AJAX进行跨域请求时的预检,需要向另外一个域名的资源发送一个HTTP OPTIONS请求头,用以判断实际发送的请求是否安全。
CORS跨域需要注意的问题:options预检
浏览器缓存机制
问了expires缺点,只说了有时差问题,还有呢?浏览器时间和服务端时间可能不一致
1、强缓存
catch-control:max-age=3600
no-catch(表示使用协商缓存)
no-store(表示不进行任何形式的缓存)
2、协商缓存
状态码304
前端存储, cookie、sessionStorage、localStorage
由于http协议是无状态的,只要客户端与服务端数据交换完,就会断掉链接,如果再请求就再次链接,而服务器是无法保存这种链接的状态,只有不停地链接、断链接,所以可以使用cookie来做一个身份认证
cookie会在http请求头中携带,会在服务器和客户端间传递,所以cookie会有大小限制,不能超过4k,sessionStorage和localStorage只会存在本地,大小要比cookie大,其中sessionStorage是仅在当前的会话窗口有效,不是所有窗口都可以共享数据的。其它两个是真个浏览器都可以数据共享。
