

目前国内国外等许多互联网公司都正在使用微服务架构将业务应用程序实现为一组松耦合服务,并迁移部署到分布式系统之上。与早期传统的单体架构一样。分布式系统设计同样需要关注服务水平的质量。本文要讲解的负载均衡机制就是提升目标可用性、维持实例健康的一种方式。
负载均衡从语义上简单介绍,即将负载按某种算法分配给多个目标以保证各个目标达到一种相对的均衡,这相对的均衡更多的是表示适合目标当前状态的应有分配,而不是简单的均匀分配。至于多均衡,这就取决于具体负载均衡算法的实现和业务的关注了。其主要应用的场景罗列有下:
-
提升访问性能和过载保护
部署多个服务实例,并通过负载均衡机制流量分发到不同的节点进行处理,在提高访问效率的同事也提供过载保护,避免某个实例被高流量打垮拖垮整个业务。
-
动态扩展&消除单点故障
可以动态扩展后端实例,由负载均衡机制来选择一台合适的实例转发上游的请求。并且该扩展对于客户端无感知。除此之外,负载均衡机制都会配套健康检查机制,从而保证筛选掉不健康的实例,优先健康的实例调用。
-
跨区域调用
某些负载均衡机制,能动态感知上游请求发出的地域信息,从而探测对应地域的下游服务实例进行请求,减少网络延时开销。
-
同城容灾和跨地域容灾
在遇到可用区故障时,提供智能转换可用区能力,将流量导流到其他健康的备用可用区,具体实现可以看文末的参考链接。
负载均衡总体可以分为两种:
- 硬件负载均衡。硬件负载均衡主要通过安装专门用于负载均衡的设备如F5。
- 软件负载均衡。软件负载均衡则主要是在服务器上安装一些具有负载均衡功能的软件来完成请求分发进而实现负载均衡,比较有名的是Ngixn和最近兴起的Envoy以及客户端侧的负载均衡模块。
按具体的实现方式来看:
- L2层负载均衡:基于MAC地址信息(虚拟MAC地址到真实MAC地址)进行负载均衡。
- L3/L4层负载均衡:通过报文中的IP、端口等信息,再加上负载均衡设备所采用的负载均衡算法进行选择合适的节点。
- L7负载均衡:负载均衡算法通过应用请求的信息,例如URL信息进行选择对应的节点。
按实现具体架构来看:
- 客户端负载均衡
- 代理负载均衡
- 外部负载均衡
- sidecar负载均衡
本文主要介绍的是根据负载均衡的架构方式介绍四种负载均衡架构的特点与基本运行原理。
客户端负载均衡
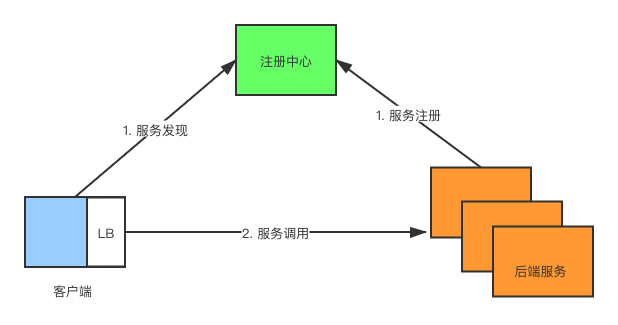
客户端负载均衡,通过客户端内置对应的负载均衡模块实现,该方式实现简单,成本低,不需要任何外部的负载均衡设备和进程,一般也叫做软负载均衡。像大家熟知的一些微服务框架,例如SpringCloud、Dubbo、Motan等的远程调用系统都是使用的这种负载均衡模式。除此之外,客户端为了满足负载均衡的实现,通常也集成服务发现、服务跟踪、健康检查等基础功能。
其具体工作原理:
- 步骤1,服务提供者在启动时,向注册中心注册。服务消费者在启动时,向注册中心订阅自己所需的服务。注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
- 步骤2,服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
常用的软负载均衡算法:RoundRobin、Least Active、Least Connection、Consistent Hash等。
其特点:
-
使用成本较低,不需要任何外部进程和硬件LB设施,但是因为该负载均衡作为客户端的内置模块,当团队内使用多语言开发时,以及与业务代码耦合度高造成维护升级困难,需要额外的维护成本。
-
适合客户端和服务端流量比较大的场景,减少端到端的额外跳数。
-
负载均衡算法实现简单,一般无法根据丰富服务端的负载信息(CPU load、mem used)等进行动态的负载均衡。
个人认为该方式适合用于大流量场景,对部署成本有要求的、并且客户端和服务端之间相互信任能直接通信。特别是RPC框架中。
代理负载均衡
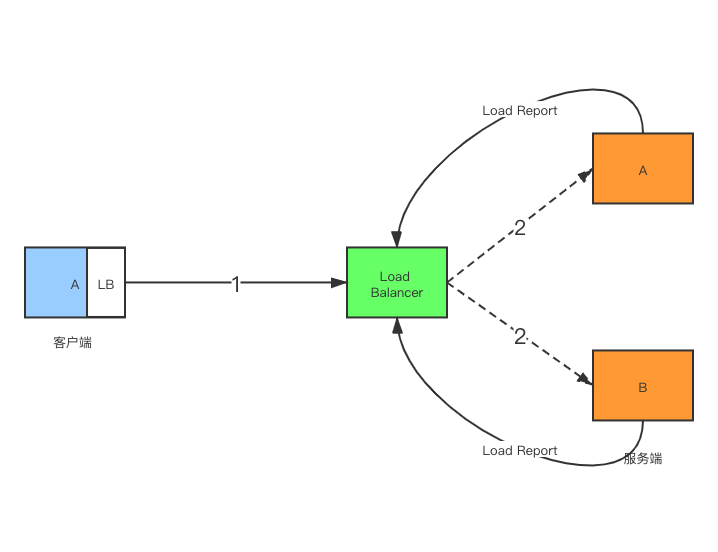
代理负载均衡一般也称作服务端负载均衡,但并不是指其部署在服务端进程内。而是该负载均衡机制实现一般对客户端透明。其通过接受客户端请求,并根据配置的负载均衡方式进行负载均衡转发到某一个后端服务节点上,具体的工作原理如下:
- 客户端向Load Balancer代理发出请求,上图步骤1。
- Load Balancer代理通过负载均衡算法,选择其中的一台后端服务节点进行发送请求,如上步骤2。并接受响应。随后再转发给客户端。
- Load Balancer定期拉或者由服务端推的方式进行获取当前后端节点的负载状态,例如服务健康状态、连接数、CPU负载等,为Load Balancer智能的负载均衡算法提供数据支持。
该方式客户端其实并不知道自己请求的是哪个后端节点,客户端只负责将请求发送给Load Balancer,从而达到客户端透明的效果。举个例子,你在浏览器中输入www.baidu.com,但是这可能就是一个指向Load Balancer设备的域名,而你并不知道具体的服务端地址。
服务端负载均衡方式的特点:
- 增加了额外的一跳,即需要经过独立的Load Balancer代理,增加了网络延迟。
- 需要额外维护Load Balancer的可用性。在大流量情况下,需要支持其性能要求。
- 降低开发成本和业务代码耦合,客户端完全不需要处理服务发现、负载均衡等逻辑。
- 因为Load Balancer是单独部署的,所以其一般可以实现更智能的负载均衡算法,例如根据后端服务的系统负载进行优先选择。
个人认为该方式一般应用于网站架构中对后台服务端负载均衡的场景,以及对客户端和服务端通信可靠性和安全性等有所要求。
外部负载均衡器
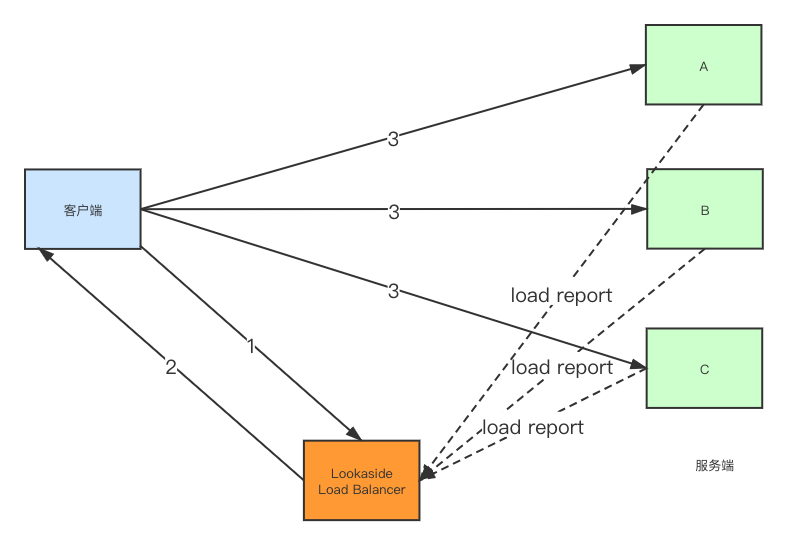
该模式下,外部负载均衡器会和后端服务进行不断交互,获取负载情况,这些负载信息会作为负载均衡的一个依据。并且外部负载均衡器通常会和其他基础设施组件交互,例如和注册中心进行服务发现等,典型的实现方式有gRPCLB负载均衡策略。
工作方式可以简化如下:
-
步骤1中,客户端先发送负载均衡请求给外部负载均衡器。
-
步骤2中,Lookaside Load Balancer通过名称服务订阅和获取所有该服务的服务列表(具体实现可能有所差别),并根据负载均衡算法返回具体的某个后端节点地址。(有些可能会返回一个列表)
-
步骤3中,客户端拿到地址后,向该服务端地址进行发送请求。
后端服务实例也会定时地将当前实例的负载信息、请求处理信息等发送给Lookaside LoadBalancer,以提供负载均衡算法的数据支持。
该方式:
- 和服务端负载均衡类似,也增加了额外的一跳,即需要经过独立的Lookaside Load Balancer查询负载均衡结果,增加了网络延迟,但具体实现不同可能有所优化,例如本地定期缓存结果。
- 需要额外维护Lookaside Load Balancer的可用性,但整体性能要求和可用性要求比服务端负载均衡的服务端代理要求低。
- 客户端仍需要部分负载均衡处理逻辑。
- 与服务端负载均衡类似,负载均衡算法也可以智能动态地根据后端实例负载信息调整。
个人认为该方式适合于低延时、高性能需求的微服务场景。
sidecar负载均衡
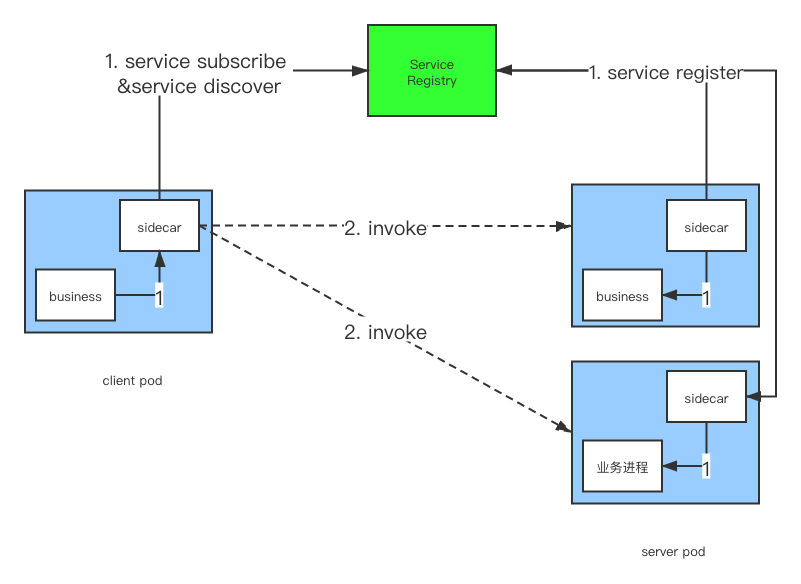
看起来该方式很类似于客户端负载均衡的架构,可以认为该方式是由客户端负载均衡以及服务端负载均衡衍生而来的。其负载均衡运行在客户端侧,但是却独立于客户端业务进程运行,为绑定其的业务进程充当一个专用的小代理,这其实就是典型的边车设计模式,其将负载均衡以及负载均衡的依赖服务如服务注册发现、服务跟踪等一系列与业务逻辑无关的代码抽象分离到sidecar这个程序中,并独立运行。sidecar一般与业务进程一起运行在同一个Pod下,行成一个贴合的线程组,共享网络等运行环境。该模式是Service Mesh概念中尤为重要的一环。
sidecar负载均衡的基本运行过程:
- 步骤1中,服务提供者pod在启动时,由sidecar向注册中心注册当前应用的地址(业务进程地址或者是sidecar地址,不同实现有所区别)。服务消费者在启动时,向注册中心订阅自己所需的服务。注册中心返回服务提供者地址列表给sidecar,如果有变更,注册中心将基于长轮询或者长连接推送变更数据给sidecar。
- 步骤2中,服务消费端的sidecar从提供者地址列表中,基于软负载均衡算法,选一个节点进行调用,如果调用失败,再选另一台调用。
该方式一般用于Service Mesh架构。
相关阅读
常用负载均衡算法:
kemptechnologies.com/load-balanc…
边车设计模式:
gRPC负载均衡博客介绍:
负载均衡的应用场景:
LVS的工作机制:
VIP的实现原理

