

Redis特性
为什么Redis快
- 单线程,避免线程切换和资源竞争
- 非阻塞IO,使用epoll作为IO多路复用的技术实现,处理客户端请求时不会阻塞主线程
- 纯内存访问
优化网络延迟
Redis的性能瓶颈可能是网络 优化方案:
- 单机部署采用unix进程间通讯代替TCP
- multi-key的方式合并指定,减少请求数。如使用mget
- 使用transaction、script合并requests和responses
- 使用pipeline合并response
数据结构
String
在Redis中String称为动态字符串(检测SDS Simple Dynamic String),内部数据结构类似ArrayList,维护着一个字节数组,并且内部预分配了一定的空间,减少内存频繁分配。

内存分配机制:
- 当字符串长度小于1M时,每次扩容都是加倍现有空间
- 当字符串长度超过1M时,每次扩容只扩展1MB的空间 字符串的最大长度为512M
内部编码
- int: 8个字节的长整数
- embstr: 小于等于39字节的字符串
- raw: 大于39个字节的字符串
数据结构:
struct SDS{
T capacity; //数组容量
T len; //实际长度
byte flages; //标志位,低三位表示类型
byte[] content; //数组内容
}
capacity 和 len两个属性都是泛型,为什么不直接用int类型?因为Redis内部有很多优化方案,为更合理的使用内存,不同长度的字符串采用不同的数据类型表示,且在创建字符串的时候 len 会和 capacity 一样大,不产生冗余的空间,所以String值可以是字符串、数字(整数、浮点数) 或者 二进制。
应用场景
- 缓存
- 计数 统计访问次数
- 共享session
常用命令
set [key] [value] 给指定key设置值(set 可覆盖老的值)
get [key] 获取指定key 的值
del [key] 删除指定key
exists [key] 判断是否存在指定key
mset [key1] [value1] [key2] [value2] ...... 批量存键值对
mget [key1] [key2] ...... 批量取key
expire [key] [time] 给指定key 设置过期时间 单位秒
setex [key] [time] [value] 等价于 set + expire 命令组合
setnx [key] [value] 如果key不存在则set 创建,否则返回0
incr [key] 如果value为整数 可用 incr命令每次自增1
incrby [key] [number] 使用incrby命令对整数值 进行增加 number
List
Redis中的List和Java的LinkedList很像,底层都是链表结构,插入和删除操作非常快时间复杂度O(1)。当数据量较少时底层的结构为一块连续的累成,称为ziplist(压缩列表),它讲所有的元素紧挨一起存储,分配的是一块连续的内存。当数据较多的时候回变成quicklist(快速与列表)。单纯链表需要维护prev和next指针需要占用较多内存。在redis3.2之后采用ziplist+链表的混合结构。简称为quicklist
内部编码
- ziplist,当列表中的元素个数小于list-max-ziplist-entries(默认512),并且列表中每个元素值都小于list-max-ziplist-value(默认64),来减少内存使用
- linkedlist: 当列表类型无法满足ziplist条件时,redis使用linkedlist作为列表内部实现
应用场景
- 消息队列:通过lpop和rpush(或rpop和lpush)实现队列功能
- 列表,朋友圈点赞列表、评论列表、排行榜。lpush明丽和lrange命令实现最新列表的功能。
常用命令
rpush [key] [value1] [value2] ...... 链表右侧插入
rpop [key] 移除右侧列表头元素,并返回该元素
lpop [key] 移除左侧列表头元素,并返回该元素
llen [key] 返回该列表的元素个数
lrem [key] [count] [value] 删除列表中与value相等的元素,count是删除的个数。 count>0 表示从左侧开始查找,删除count个元素,count<0 表示从右侧开始查找,删除count个相同元素,count=0 表示删除全部相同的元素
(PS: index 代表元素下标,index 可以为负数, index= 表示倒数第一个元素,同理 index=-2 表示倒数第二 个元素。)
lindex [key] [index] 获取list指定下标的元素 (需要遍历,时间复杂度为O(n))
lrange [key] [start_index] [end_index] 获取list 区间内的所有元素 (时间复杂度为 O(n))
ltrim [key] [start_index] [end_index] 保留区间内的元素,其他元素删除(时间复杂度为 O(n))
Hash
Redis中的Hash和Java中的HashMap很相似,采用数组+链表的结构,当发生hash碰撞时将元素追加到链表上。但Redis的Hash 只能是字符串 Hash和String都可以存储用户数据。但是Hash可以对用户信息的每个字段单独存储;String存储的是序列化之后的字符串。从修改角度考虑,使用hash存储可针对某个字段进行修改,网络带宽。但是Hash的内存占用要大于String
内部编码
- ziplist(压缩列表),当Hash类的元素小于hash-max-ziplist-entries(默认512)同时所有值小于hash-max-ziplist-value(默认64),采用ziplist作为hash的内部实现,ziplist采用更紧凑的数据结构实现多个元素的连续储存,节约内存比hashtable更优
- hashtable(哈希表):当哈希类型无法满足ziplist条件时,会采用hashable作为哈希的内部实现,因为此时ziplist读写效率下降,而hashtable的读写复杂度都为O(1)
应用场景
- 购物车:hset [key] [field] [value] 命令, 可以实现以用户Id,商品Id为field,商品数量为value,恰好构成了购物车的3个要素。
- 存储对象:hash类型的(key, field, value)的结构与对象的(对象id, 属性, 值)的结构相似,也可以用来存储对象。
常用命令
hset [key] [field] [value] 新建字段信息
hget [key] [field] 获取字段信息
hdel [key] [field] 删除字段
hlen [key] 保存的字段个数
hgetall [key] 获取指定key 字典里的所有字段和值 (字段信息过多,会导致慢查询 慎用:亲身经历 曾经用过这个这个指令导致线上服务故障)
hmset [key] [field1] [value1] [field2] [value2] ...... 批量创建
hincr [key] [field] 对字段值自增
hincrby [key] [field] [number] 对字段值增加number
Set
Redis中的Set和HashSet类似,内部的键值对是无序唯一的。它的内部实现相当于一个特殊的字典,字典中所有的vlaue都是一个值null.当集合最后一个元素被移除之后,数据结构自动删除,内存被回收。
内部编码
- intset(整形集合),当集合中的元素都是整数且个数小于set-max-intset-entries配置(默认512个),Redis会选用intset作为集合的内部实现,从而减少内存的使用。
- hashtable,当集合无法满足intset,redsi会使用hashtable作为集合内部实现
应用场景
- 好友集合
- 随机展示。推荐商家用srandmember中随机选取几个
- 去重功能
常用命令
sadd [key] [value] 向指定key的set中添加元素
smembers [key] 获取指定key 集合中的所有元素
sismember [key] [value] 判断集合中是否存在某个value
scard [key] 获取集合的长度
spop [key] 弹出一个元素
srem [key] [value] 删除指定元素
zset 有序集合
Zset保证了内部value的唯一性,另外可以给每个value赋值score,代表这个value的权重。内部实现用的是一种叫做跳跃列表的数据结构。
内部编码
- ziplist:当有序列表中的元素小于zset-max-ziplist-entries(默认128),每个元素值小于zset-max-ziplist-value(默认64),采用ziplist减少内存
- skiplist(跳跃列表),当ziplist条件不足时,有序集合会使用skiplist作为内部实现,因为此时ziplist的读写效率会下降
应用场景
- 排行榜,zset能怼数据进行动态排列
常用命令
zadd [key] [score] [value] 向指定key的集合中增加元素
zrange [key] [start_index] [end_index] 获取下标范围内的元素列表,按score 排序输出
zrevrange [key] [start_index] [end_index] 获取范围内的元素列表 ,按score排序 逆序输出
zcard [key] 获取集合列表的元素个数
zrank [key] [value] 获取元素再集合中的排名
zrangebyscore [key] [score1] [score2] 输出score范围内的元素列表
zrem [key] [value] 删除元素
zscore [key] [value] 获取元素的score
持久化
RDB
RDB持久化是把当前进程数据生成快照保存到硬盘的过程,触发RDB持久化的过程分为手动触发(bgsave命令)
RDB配置
- 保存:RDB文件保存在dir配置指定目录下,文件名可通过dbfilename配置。
- 压缩:Redis默认采用LZF算法对生成的RDB文件进行压缩处理,压缩后的文件远远小于内存大小,默认开启
- 自动触发配置
save 900 1
save 300 10
save 60 10000
900秒之内,如果超过1个key被修改,则发起快照保存;
300秒内,如果超过10个key被修改,则发起快照保存;
1分钟之内,如果1万个key被修改,则发起快照保存;
bgsave流程说明
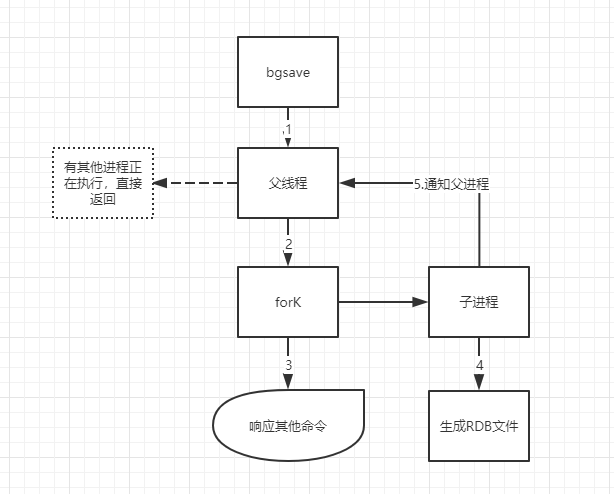
- 执行bgsave命令,Redis父线程判断是否有其他正在执行的子进程(如RDB/AOF子进程)
- 父线程fork子进程,fork操作过程中会父线程会阻塞
- fork完成后,bgsave返回“background saving started”信息,并不在阻塞父进程
- 子进程创造RDB文件,根据父线程内存生成临时快照文件,完成后对原有文件进行原子替换,
- 子进程发送信号给父进程表示完成,父进程更新统计信息
优缺点
优点
- RDB采用紧密压缩的二进制文件,代表Redis在某个时间上的数据快照,非常适合备份和全量复制等场景
- Redis加载RDB恢复数据远远块于AOF方式 缺点
- 没有办法做到实时持久化/秒级持久化。bgsave命令每次运行都要执行fork操作创建子进程,属于重量级操作,频繁执行成本过高
- 采用二进制格式保存,存在老版本redis服务无法兼容新版RDB格式的问题
AOF
AOF(append only file)持久化;以独立日志的方式记录每次写命令,重启时再冲洗执行AOF命令文件达到回复数据的目的。
AOF配置
appendfsync yes #默认不开启
appendfsync always #每次有数据修改发生时都会写入AOF文件。
appendfsync everysec #每秒钟同步一次,该策略为AOF的缺省策略。
AOF使用流程
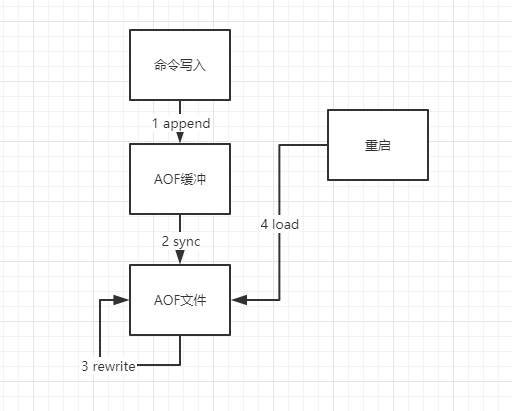
- 所有的写入命令会追加到aof_buf(缓冲区)中
- AOF缓冲区根据对应的策略向硬盘做同步
- 随着AOF文件的增大,需要定期对AOF文件进行重写
- 当Redis服务器重启时,可以假装AOF文件进行数据恢复
优缺点
能保存较实时的数据,存储的数据文件较大,速度慢于RDB
思考
- 为啥AOF采用文件协议格式? 文件协议具有良好的兼容性,开启AOF后,所有写入命令都包含追加操作,直接采用协议格式,避免了二次处理开销 文件协议具有可行性,方便直接修改和处理
- AOF为什么将数据最佳到aof_buf中 Redis使用单线程响应命令,如果每次写AOF命令都追加到磁盘,性能完全取决于磁盘的负载。多种缓冲区同步磁盘的策略,在性能和安全性方面做出平衡。
内存管理
设置内存上线
maxmemory限制的是Redis实际使用的内存量,也就是used_memory统计项对应的内存,由于内存碎片率的存在,实际消费的内存可能回避maxmemory设置更大。
目的
- 用于缓冲场景,当超出内存上限maxmemory时使用LUR等删除策略释放空间
- 防止所用内存超过服务器物理内存
动态设置内存上限
config set maxmemory 6GB
内存回收策略
删除过期键对象
- 惰性删除:客户端读取带有超时属性的键时,如果已经超过键设置的过期实际,会执行删除命令并返回为空
- 定时任务删除:Redis内部维护一个定时任务,默认每秒运行10秒,定时任务中删除逻辑采用自适应算法 定时删除自适应算法(默认采用慢模式运行)
- 定时任务在每个数据库空间随机检查20个键,当发现过期删除对应键
- 如果超过检查数25%的键过期,循环执行回收逻辑知道不足25%或运行超时为止,慢模式下超时时间为25毫秒
- 如果回收超时,Redis触发内部时间再次以快模式运行回收键任务,快模式下超时时间为1毫秒且2秒内只能运行一次(快慢模式内部删除逻辑相同,只是执行的超时时间不同)
内存溢出控制策略
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰allkeys-
- random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-enviction(默认):拒绝所有写请求,只响应读请求
持久化中的过期键
- RDB 文件分为两个阶段,RDB 文件生成阶段和加载阶段。
- 从内存状态持久化成 RDB(文件)的时候,会对 key 进行过期检查,过期的键不会被保存到新的 RDB 文件中,因此 Redis 中的过期键不会对生成新 RDB 文件产生任何影响。
- 如果 Redis 是主服务器运行模式的话,在载入 RDB 文件时,程序会对文件中保存的键进行检查,过期键不会被载入到数据库中。所以过期键不会对载入 RDB 文件的主服务器造成影响;
- 如果 Redis 是从服务器运行模式的话,在载入 RDB 文件时,不论键是否过期都会被载入到数据库中。但由于主从服务器在进行数据同步时,从服务器的数据会被清空。所以一般来说,过期键对载入 RDB 文件的从服务器也不会造成影响。
缓存雪崩、缓存穿透、缓存击透、缓存降级等问题
缓存雪崩
缓存雪崩是指一段时间内缓存集中失效的问题。所有的查询都落到的数据库上,对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。 解决方案:
- 缓存时间增加随机因子,经量分散缓存过期时间
- 通过消息队列方式老保证不会有大量线程对数据进行一次性读写
缓存穿透
缓存穿透指缓存和数据库中都没有数据用户要查询的数据,每次都进行2次查询。若有人恶意攻击,对数据库造成压力可能会压垮数据库。 解决方案:
- 布隆过滤用于存储可能访问的key,布隆过滤用于大数据量的集合中判断元素是否存在(一定不存在或可能存在)
- 对于数据库取不到的数据,写入缓存中。缓存时间可以设置适当短一点。
缓存击透
缓存击透是指缓存中没有但是数据库中有的数据,由于并发量大,同时读取缓存没有数据而导致同时去数据库中取数据,造成数据库压力过大。 解决方案:
- 热点数据不过期
- 设置互斥锁,当获取缓存为空时候上锁,从数据库加载完毕后是否锁。若其他线程获取锁,睡眠50ms后重新尝试。这里的锁需要考虑java并发包和集群环境下的分布式锁
缓存降级
缓存降级指当访问量突然剧增,服务出现问题或者非核心业务影响到核心业务性能时,需要包装服务还是可用。系统可用根据一些关键数据进行降级,来保证核心业务的可用。例如redis中适当删除非关键缓存数据。
参考文章
付磊、张益军《Redis开发与运维》
#TODO 针对Redis数据结构学习+针对分布式和运维相关的了解
