

金三银四,各位老弟老哥朋友兄弟姐妹么肯定都参与了不少 面试,现在面试不光光得会,还要有闪光点,比别人懂得多一点点总没错,这张图总结了jdk1.7和jdk1.8的区别,让shiyao酱细细解释一下
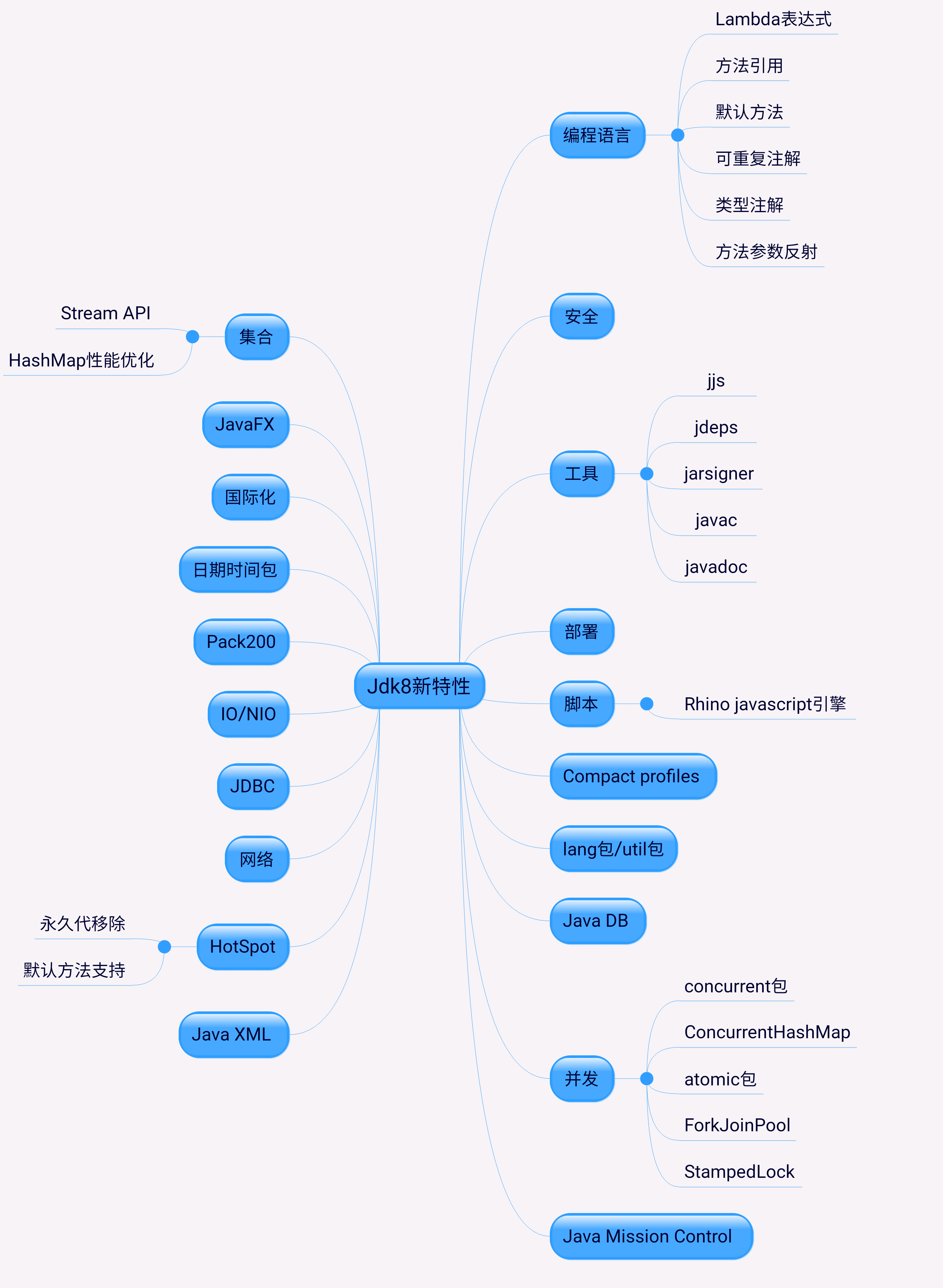
一 StreamApi--jdk1.8增加了stream特性,主要是基于fork-join框架构建,而且你可以通过parallel()与sequential()在并行流与顺序流之间进行切换。
二 Hashmap性能优化: 1最重要的一点是底层结构不一样,1.7是数组+链表,1.8则是数组+链表+红黑树结构; 2.插入键值对的put方法的区别,1.8中会将节点插入到链表尾部,而1.7中是采用头插 3.jdk1.7中的hash函数对哈希值的计算直接使用key的hashCode值,而1.8中则是采用key的hashCode异或上key的hashCode进行无符号右移16位的结果,避免了只靠低位数据来计算哈希时导致的冲突,计算结果由高低位结合决定,使元素分布更均匀 4.扩容策略:1.7中是只要不小于阈值就直接扩容2倍;而1.8的扩容策略会更优化,当数组容量未达到64时,以2倍进行扩容,超过64之后若桶中元素个数不小于7就将链表转换为红黑树,但如果红黑树中的元素个数小于6就会还原为链表,当红黑树中元素不小于32的时候才会再次扩容。
三 永久代移除,变成元空间 1.字符串存在永久代中,容易出现性能问题和内存溢出。 2.类及方法的信息等比较难确定其大小(比如动态加载类时),因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出
四 lamda表达式,很关键的一个新特性 用法举例: Comparator com = (x, y) -> Integer.compare(y, x);
五 并发:LongAdder 2. CompletableFuture 3. StampedLock 这3个也是很重要
LongAdder(L————AtomicLong 的并发进化版) 相比较Atomiclong,相当于用空间来换时间,longAdder的基本思路就是分散热点,里面有几个核心要素,需要记住
Striped64抽象类,Striped64中定义了Cell内部类和各重要属性 cell类------当并发高时,拆分到多个cell进行计算 base-------基础值
顺便提一下Atomiclong的原理---AtomicLong的实现方式是内部有个value 变量,当多线程并发自增,自减时,主要是调用了Unsafe类的getAndAddLong方法,该方法是个native方法,它的逻辑是采用自旋的方式不断更新目标值,直到更新成功。----缺点就是在高并发的情况下,自旋的情况会明显变多,这样子CAS的性能就会大幅度下降了
AtomicLong,常见方法--addAndGet、decrementAndGet、compareAndSet,getAndIncrement(),incrementAndGet()
六. CompletableFuture---针对异步对于future的优化,它实现了Future和CompletionStage接口,completionstage它代表一个明确完成的Future,也有可能代表一个完成阶段( CompletionStage ),在计算完成以后触发一些函数或执行某些动作。
future的缺点:结果的获取却是很不方便,只能通过阻塞或者轮询的方式得到任务的结果
七 StampedLock: StampedLock是Java8引入的一种新的所机制,简单的理解,可以认为它是读写锁的一个改进版本,读写锁虽然分离了读和写的功能,使得读与读之间可以完全并发,但是读和写之间依然是冲突的,读锁会完全阻塞写锁,它使用的依然是悲观的锁策略.如果有大量的读线程,他也有可能引起写线程的饥饿 而StampedLock则提供了一种乐观的读策略,这种乐观策略的锁非常类似于无锁的操作,使得乐观锁完全不会阻塞写线程
StampedLock的原理 每次获取锁的时候,都会返回一个邮戳(stamp),相当于mysql里的version字段 释放锁的时候,再根据之前的获得的邮戳,去进行锁释放
八. concurreenthashmap 其实可以看出JDK1.8版本的ConcurrentHashMap的数据结构已经接近HashMap,相对而言,ConcurrentHashMap只是增加了同步的操作来控制并发,从JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树,相对而言
备注:JDK1.8为什么使用内置锁synchronized来代替重入锁ReentrantLock,我觉得有以下几点
1。因为粒度降低了,在相对而言的低粒度加锁方式,synchronized并不比ReentrantLock差,在粗粒度加锁中ReentrantLock可能通过Condition来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition的优势就没有了 2.JVM的开发团队从来都没有放弃synchronized,而且基于JVM的synchronized优化空间更大,使用内嵌的关键字比使用API更加自然 3.在大量的数据操作下,对于JVM的内存压力,基于API的ReentrantLock会开销更多的内存,虽然不是瓶颈,但是也是一个选择
九. fork-join框架的优化
各位兄弟姐妹如果能把这些不同点都答上,一定加分不少
