

举个例子:
早上9点,我的10个爬虫同时启动作业,他们都需要代理。
其中爬虫中,我都从代理服务商,取了一个5分钟的IP代理,去相关网站爬取,但是在第3分钟,IP被ban;
这时候代码就需要干2件事情:
1、判断被ban的条件,发出被ban的信号
2、向代理服务商发出请求,更换IP
那么问题来了:
虽然代理IP 111.111.111.111 在网站A被ban,但是他可以在网站B使用,应该考虑复用的问题。
初步想法:
存入Redis的数据:
{
"ip": "122.4.42.131",
"port": 4242,
"expire_time": "2020-03-22 16:16:16",
"city": "山东省济南市",
"isp": "电信"
"ban": ["taobao.com", "baidu.com"] # IP被ban的域名列表
}
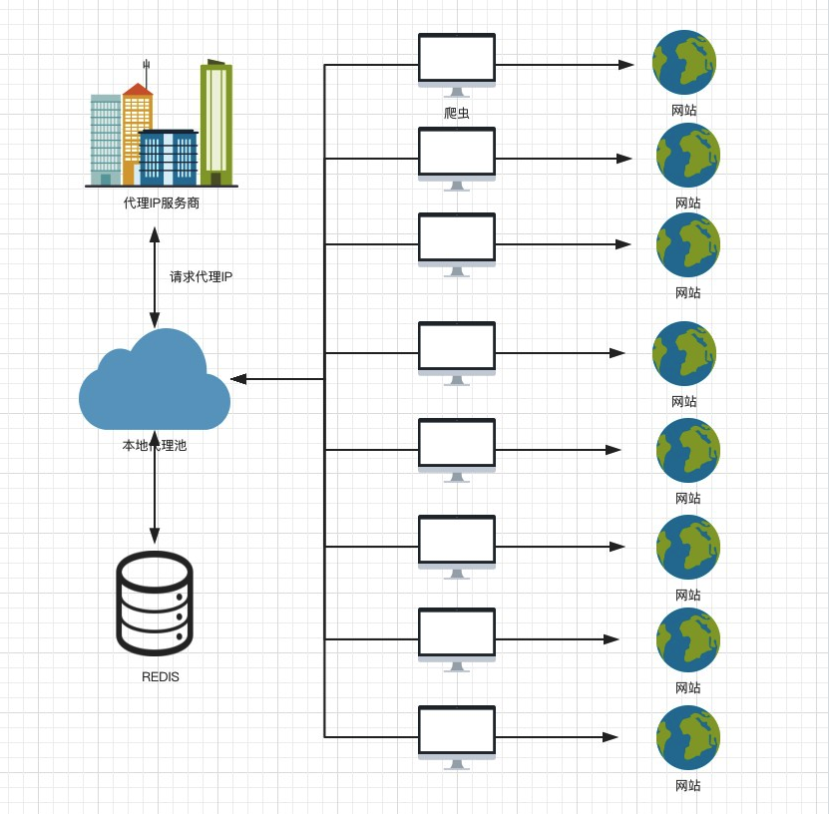
所有爬虫初始化的时候,从发送需要并发值 检测网址到代理IP池 API,代理池 根据 并发值 向 代理服务商请求 同等数量的IP代理,使用 检测网址作为目标网站,进行检测(比如统一请求baidu.com,如果IP访问通,则此时此IP已经计费),如果不可以访问,则在
"ban": ["baidu.com"] # IP被ban的域名列表
添加被ban的域名。
爬虫A 开始第一个请求,从代理池拉取IP,使用 Redis pop,排除被ban的IP;
如果第一个请求,判断出IP被ban,修改json数据,再存入代理池供其他爬虫取用。如果没有被ban,则继续使用
现状:
目前市面上的代理池,大多解决的是免费代理聚合,免费使用的问题,并没有关心这个场景的应用。
如果,像阿布云代理这样的隧道代理,可以循环取用, 变更ip,不用担心代理消耗的问题,但是,包月场景,在高并发的情况下,显得有些贵。
欢迎大家讨论~
