

物理核
经常听到CPU是几核几核的,比如4核CPU,8核CPU,比如服务器很多都是8核CPU
一台PC或者服务器,可以配置多个CPU,CPU安装在主板上。
以Linux服务器为例
cat /proc/cpuinfo
得到
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 60
model name : Intel(R) Core(TM) i7-4700MQ CPU @ 2.40GHz
stepping : 3
microcode : 0x22
cpu MHz : 2393.631
cache size : 6144 KB
physical id : 0
siblings : 8
core id : 0
cpu cores : 4
...
其中有几个physical id,机器上就安装了几个物理CPU
cpu core记录了每个物理CPU,内部有几个物理核
siblings 代表每个物理CPU有多少个逻辑核
逻辑核
经常听人说什么4核4线程,4核8线程
本来一个核会对应处理一个线程(即逻辑处理单元),但为了提高效率,后来Intel的超线程技术(HT)将物理核虚拟成逻辑处理单元,将一个物理核变为2个虚拟核,即每个核两个线程。
进程与线程
两种常见解释
- 进程和线程都是一个时间段的描述,是CPU工作时间段的描述。
- 进程是资源分配的最小单位,线程是CPU调度的最小单位
解释:
- CPU太快了,只有缓存存储器SRAM才能勉强追上它的速度,因此,一台机器上同时开30个程序,CPU可以把这30个程序变成顺序执行,每个只执行一小段,立马切换到下一个程序,再执行一小段,再切回来,人是无感知的。
- 一个程序准备开始执行的时候,相关资源必须要准备好,比如RAM地址,显卡,磁盘资源,这些准备好的东西打包一起就叫做上下文环境,然后CPU开始执行程序A,当然只执行了一小段时间,CPU就要切换到别的程序执行B,以保证几个程序的并发,切换之前要把A的上下问状态保存起来,下次切回来的时候接着用。
- 因此,进程就是包换上下文切换的程序执行时间总和 = CPU加载上下文+CPU执行+CPU保存上下文
- 进程的颗粒度太大,每次都要有上下的调入,保存,调出。线程就是进程的小分支,比如进程A有a,b,c三个线程,那么线程a,b,c就共享了进程A的上下文环境,成为了更细小的执行时间。
程序中的线程 与 CPU的线程
看到这里会懵逼,假设一台8CPU32核的服务器,是不是跑的程序最多只能开32个线程呢?
答案当然是否定的,我们常说的进程中的线程,与CPU的线程,虽然都叫线程,但完全不是一回事。
程序的线程是软件概念,一个程序可以有多个线程,可以在一个CPU核上轮流并发执行。
CPU的线程是硬件的概念,就是核。八线程就是能让八个线程并行执行。
linux中的线程
有人说linux中不存在线程的概念,查了一下,大概是说:
WINDOWS中是真的有进程和线程的,进程来准备上下文环境,是一个实例,线程是CPU调度的最小单位,程序代码执行的最小单元。
linux中一个进程的多个线程在内核中只是多个特殊的进程,它们虽然有各自的进程描述结构,却共享同一个代码上下文。在Linux上,这样的进程称为轻量级进程(Light weight process)。 每个用户线程对应一个LWP,LWP又对应一个内核线程。
LinuxThreads是用户空间的线程库,所采用的是线程-进程1对1模型(即一个用户线程对应一个轻量级进程,而一个轻量级进程对应一个特定的内核线程),将线程的调度等同于进程的调度,调度交由内核完成,而线程的创建、同步、销毁由核外线程库完成。
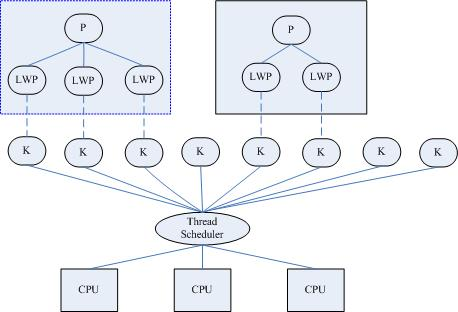
内核线程与用户线程
内核线程就是内核的分身,一个分身可以处理一件特定事情。我们的程序是很少有直接调取内核线程的,而是操作用户线程,用户线程与内核线程有一对一,多对一,多对多。
多对多模型
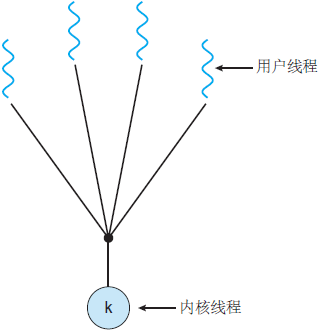
如果一个线程执行阻塞系统调用,那么整个进程将会阻塞。再者,因为任一时间只有一个线程可以访问内核,所以多个线程不能并行运行在多处理核系统上。 早期JAVA用,目前几乎没人用了。
一对一模型
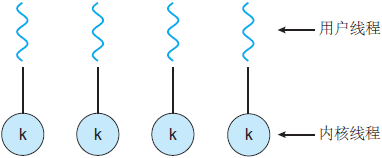
这种模型的唯一缺点是,创建一个用户线程就要创建一个相应的内核线程。由于创建内核线程的开销会影响应用程序的性能,所以这种模型的大多数实现限制了系统支持的线程数量。Linux,还有 Windows 操作系统的家族,都实现了一对一模型。
多对多模型
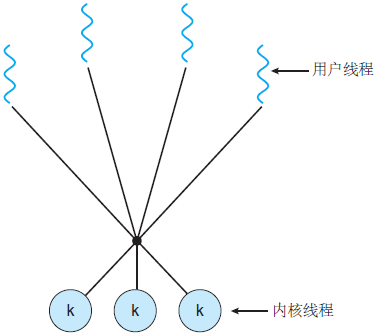
虽然多对一模型允许开发人员创建任意多的用户线程,但是由于内核只能一次调度一个线程,所以并未增加并发性。虽然一对一模型提供了更大的并发性,但是开发人员应小心,不要在应用程序内创建太多线程(有时系统可能会限制创建线程的数量)。
多对多模型没有这两个缺点:开发人员可以创建任意多的用户线程,并且相应内核线程能在多处理器系统上并发执行。而且,当一个线程执行阻塞系统调用时,内核可以调度另一个线程来执行。
