

最近一个在国外学习的朋友做家庭经济学方面的研究,想用一些美国的PSID(The Panel Study of Income Dynamics),即收入动态面板调查数据库下载相关数据,就找到了我。应朋友请求,我帮他去下载数据。但是PSID毕竟是美国的数据,网站全部是英文的,国内很少人用,一时难以找到专门的操作教程去指导。一开始毫无头绪,完全不知道从哪下手,下载下来的txt数据也很大,几十M半天打不开,用excel导入txt等了半天打开后,发现没有变量且数据分列的很不理想。最后经过不断苦苦摸索,终于找到了其中的窍门。虽然,对于国内的研究人员很少用这个数据库,但是国内毕竟没有PSID数据库的操作指南,作为一个为数不多的经过长时间摸索终于掌握其中窍门的人,笔者决定还是把自己的经验分享给大家,万一国内有人用呢?
1、关于PSID数据库
PSID数据库源于1968年,密歇根大学的调查研究中心开始收集各类关于个人,家庭的数据。其中包罗万象,从收入,职业,教育背景,贷款,医疗保险甚至到孩子的时间分配,零用钱等等都有所关注。
1968年时,参与调查的有4800个家庭,而到2001年时,这个数目已经增加到7000个。PSID追踪了65000个个人在36年间的生活和各类经济活动。PSID基本上两年调查一次(这是我个人从网站获得的信息,如有不准确还请见谅),目前主要的调查数据已经更新到2017年,每年都会有新的调查样本加入进来,同时也会启动一些新的调查项目,如消费支出、儿童发展、婚姻历史等等。
其网址为:https://psidonline.isr.umich.edu/default.aspx,下边就是主页的截图,上边介绍了PSID的情况,并强调数据可在此网站上获得,而研究人员和分析人员无需付费。数据被全球的研究人员,政策分析师和教师使用。 超过6,000种经过同行评审的出版物均基于PSID。 认识到数据的重要性,许多国家创建了自己的类似于PSID的研究,现在可以促进跨国比较研究。

目前国内很少人用PSID数据库,基本上都是美国学者在用,如2019年5月北师大举办的第三届劳动经济学前沿论坛,加利福尼亚大学欧文分校David Neumark教授的演讲主题为“EITC对女性收入的长期影响”。他就使用PSID数据中的婚姻和子女数据,探索女性在成年以后二十年间接触EITC对于其劳动力市场表现的影响,发现接触更慷慨的EITC将对于未婚生子的女性带来工资、收入及工作时间的上升,而对于结婚生子的女性,则会带来导致较低的收入和较长的工作时间。意味着EITC这一反贫困政策在长期有助于通过促进工作的激励措施产生有益影响。
2、注册PSID数据库
下载PSID首先需要注册,在主页的右侧有个quick links,倒数第二个Register就是注册:

点击进去到了注册页面(这里边还有个User Guide我们也可以下载下来作为指引):
填写相关信息并打上勾,然后点击SUBMIT就注册完成了。然后在下边的页面登录你的注册邮箱(qq邮箱也可以的)和密码,就可以免费下载数据了!!
3、如何找到并下载数据?
注册完之后,登录进去,再回到PSID的主页,可以看到菜单栏里有个Data,点击进去,就进入以下界面:

这里包括Data Center、Packaged Data、Restricted Data、FIMS、User Generated,只有Data Center、Packaged Data是可以免费下载的公共数据,其他的都是首先数据或者PSID的一些开发系统与功能。
其中,Data Center是PSID的数据中心,它是一些高级的数据搜索、列表与使用、存储等功能,比如可以通过Variable Search来搜索所需的不同年度不同调查项目的数据,但是对于我们来说,对PSID的数据完全不熟悉,小白很难使用这些功能,而且国内访问这个网站速度很慢,搜索的时候网页经常在“转圈”,还不如直接把数据下载下来自己去筛选,所以接下来还是直奔主题。
主要的数据下载在Packaged Data里,会有Main and Supplemental Studies(主要和补充研究的数据),以及Early Release和Auxiliary Files这些辅助的数据,基本的数据都在Main and Supplemental Studies里。
打开Main and Supplemental Studies页面,就到了数据下载页面:
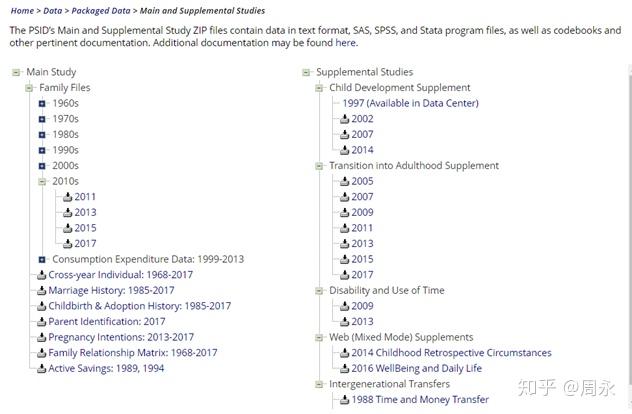
这里有不同的数据项目供我们下载,大多数变量都包含在Family file,下载下来的数据中,会有样本编号(访问编号、家庭编号等等),因此不同的数据项目之间是有关联的,可以通过样本编号来合并数据,但是通常对我们不熟悉的人来说Family file基本就够用。
点击Family file的加号,展开各个年度的数据之后,再点击年份就自动下载数据了。
4、如何提取数据?
下载下来的数据是一个压缩包,以2017年Family file的数据为例,解压之后的文件如下:
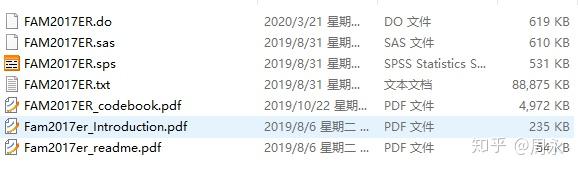
前三个是stata的do文件,SAS的sas文件以及SPSS的sps文件,FAM2017ER.txt就是我们需要的数据文件了,后边三个就是2017年Family file数据的代码手册(codebook)、介绍、说明等。
需要注意的是这个txt里包含9607个样本和5571个变量,所以对于txt来说,数据文件很大(88多M),用记事本很难打开且打开后数据格式是混乱的,还没有变量,用excel导入后也是比较乱的。所以这里需要用到前三个是stata的do文件,SAS的sas文件以及SPSS的sps文件,打开相关软件,然后把这些程序文件(do、sas、sps)运行一下,就可以浏览数据了。以stata为例:
首先用记事本打开do文件,前边都是ER66001 - ER71571都是变量名的创建,往下拉,拉到变量标签的生成这个部分(label variable),可以看到中间有个导入FAM2017ER.txt文件的命令:
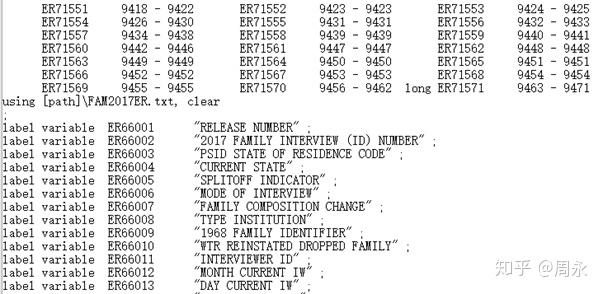
这里我们需要改成我们自己的文件路径,如在E盘,就改成:using "E:\FAM2017ER.txt", clear。然后保存,打开stata(使用SAS、SPSS都要这样改),选择file-do,将该文件打开,点击,有时候程序运行会出现以下问题:
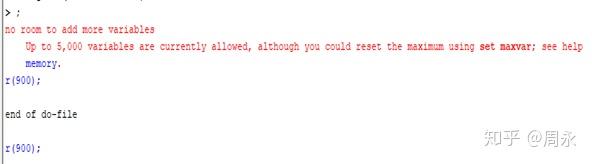
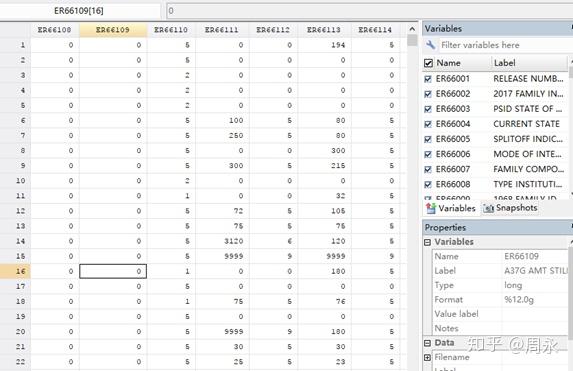
这是因为我们在stata设置了最高变量数为5000的限制,导致没有足够空间打开该文件。在stata里输入“set maxvar 10000”,再重新file-do以下,就可以打开该数据文件:
5、如何筛选变量?
对于这么多的数据,我们肯定不会全部用上且让我们眼前白花花一片,无从入手,那么怎么筛选变量,找到我们研究所需的变量呢?这就要用到之前压缩包里的FAM2017ER_codebook.pdf了,这个文本就是介绍了每个变量ER66001 - ER71571所代表的问题,及其选项的含义、回答情况等等,以ER66017 "AGE OF REFERENCE PERSON"为例,如图:

最上边是对该变量多对应标签、调查问题的介绍,num(3.0)为变量的数值类型即长度,下边的表格中,第一列是不同选项的问答频数,第二列是频率(比重),第三类是选项的取值,第四列是选项对应的含义,如14-120是实际的年龄,999就表示没有回答或数据缺失等等。
那么我们就可以根据codebook来筛选变量,如我们需要研究对象的收入、教育等,那就可以在pdf查找wage、income、education、schooling等单词,再根据相应的解释说明,来找到我们需要的变量。
需要注意的是,我们在筛选变量是最好把:
ER66001 "RELEASE NUMBER"
ER66009 "1968 FAMILY IDENTIFIER"
ER66011 "INTERVIEWER ID"
等变量保留,这代表了不同样本的ID,特别是ER66009代表了“1968 Family Number (ID Number)”,有助于跨年度数据的对接与研究。
以上就是我在探索PSID数据的一些经验,由于我只是一时的研究,很多功能尚未涉及与深挖,只是介绍一些基础的内容,以飨大家。

