

If in the deterministic case, the adjoint equations are backward ordinary differential equations and represent, in some sense, the same forward equation.
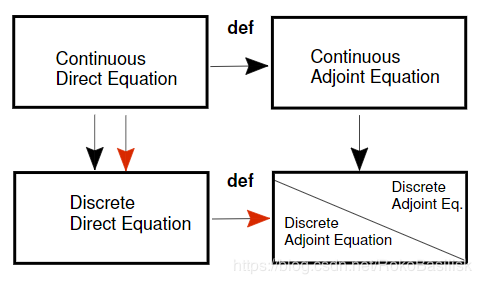
Continuous vs. Discrete Adjoint Equations
The adjoint equations can be derived using two different approaches.
By definition we have
Both with advantages and disadvantages:
Continuous approach: The adjoint equations are derived by definition using the continuous direct equations.
- + Straightforward derivation, reuse old code when programming;
- – Accuracy depends on discretization, difficulties with boundary conditions.
Discrete approach: The adjoint equations are derived from the discretized direct equations.
- + Accuracy can be achieved close to machine precision,and can be independent of discretization;
- –Tricky derivation, usually requires making a new code,or larger changes of an existing code.
Consider the following optimization problem (ODE) whereφis the state andgthe control
with initial condition
We can now define an optimization problem in which the goal is to find an optimalg(t) by minimizing the following objective function
Continuous approach
We can solve this problem using an adjoint identity approach or by introducing Lagrange multipliers.
If we now define the adjoint equation as with an arbitrary initial condition
then the identity reduces to:
By definition the Left Hand Side is identically zero but this is exactly what must be checked numerically , i.e. error=|LHS|.
The gradient of Jw.r.t. g can be derived considering the J is nonlinear in and
. We linearise by
,
and then write the linearised objective function as:
If we choose then the equation for
can be substituted into the expression for the adjoint identity. If you further define the adjoint equations, remember that
, then the final identity is written:
The adjoint equations and gradient of Jw.r.t. g are written:
The so called optimality condition is given by .
Discrete approach
A discrete version of the direct equation is written:
where denotes the number of discrete points on the interval
,
is the constant time step, and
is the initial condition. This can be written as a discrete evolution equation.
with , and
the identity matrix. A discrete version of the objective function can be written:
An adjoint variable is introduced defined on
and we write the adjoint identity as
We then introduce the definition of the state equation on the left hand side of and impose that
This is thediscrete adjoint equation. Using the discrete direct and adjoint yields:
which must be valid for any and
. An error can therefore be written as
This can be compared with the error for the continuous formulation from the previous derivation
Comparison
Error from the discrete approach
Error from the continuous approach
The convergence of the physical problem and the accuracy of the gradient can be considered two different issues.
-
In the continuous approach the adjoint solution depends on the discretization scheme used and the error will decrease as the spatial and temporal resolution increase. In this case it is difficult to distinguish between different errors in the case an optimization problem fail to converge.
-
The advantage of the discrete approach is that the adjoint solution will be numerically "exact", independently of the spatial and temporal resolution.
The discrete optimality condition is then derived. Since is nonlinear with respect to
and
we must first linearize. This can be written
We now choose the terminal condition of the adjoint as and substitute this expression into the discrete adjoint identity. This is written
By inspection one can see that the left hand side is identical to the first term in the expression for , and
. Rearranging the terms, we get
from which we get the discrete optimality condition
Note that if is a matrix then
