

node URL模块API解析
node URL模块API有两套:
const urlStr = 'http://user:pass@sub.example.com:8080/p/a/t/h?query=string#hash'
// 旧版本遗留API
const URL = require('url')
console.log(URL.parse(urlStr))
// 实现了WHATWG标准的新API
console.log(new URL(urlStr))
下图解释了两套API的区别,其中上面为旧API,下面为实现了WHATWG标准的新API
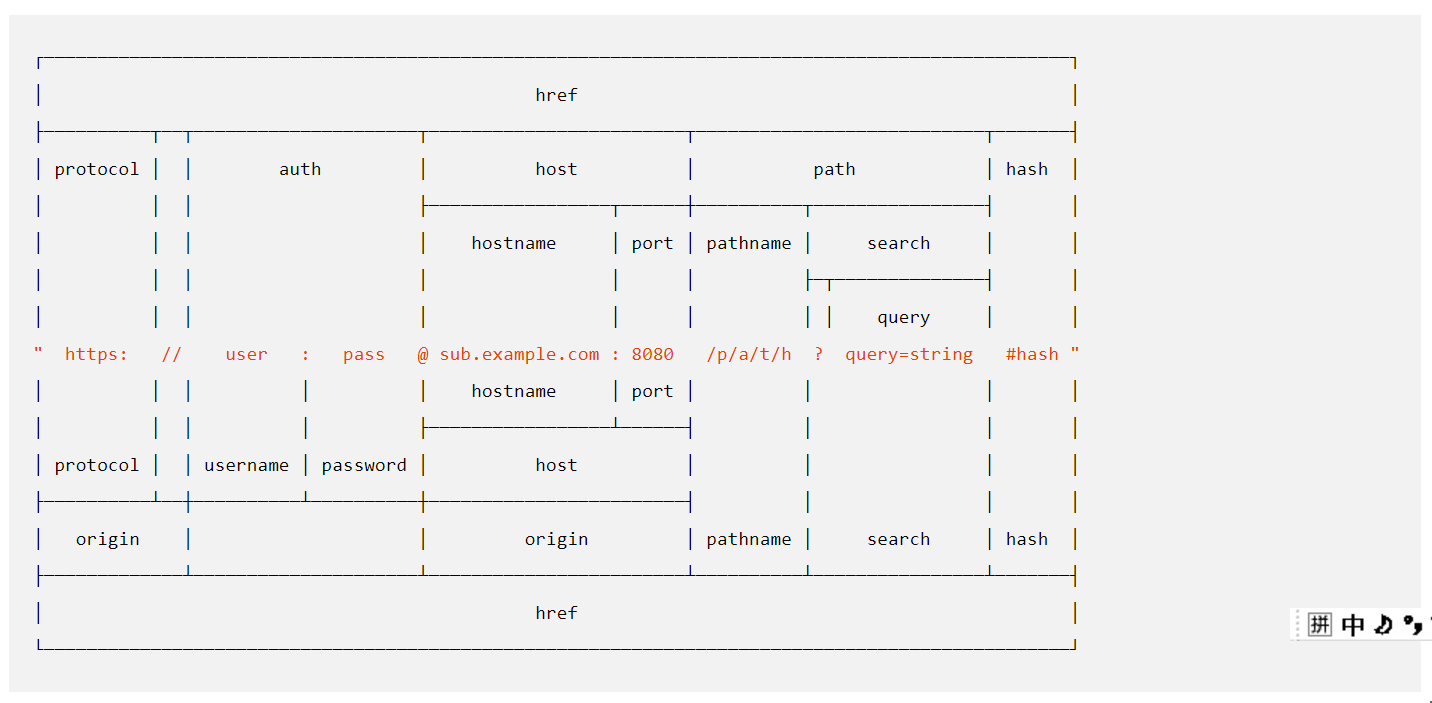
- 新版省去了query
- 新版增加了origin,包含protocol和host
利用正则解析url字符串
const reg = /^([a-z]+:)\/\/(?:([^:]+):([^@]+)@)?([^:?#/]+)?(?::(\d+))?([^?#]+)?(\?[^#]+)?(#.+)?$/i
正则解析
- 协议:
// 匹配协议: 如"https://" 捕获部分不包含"//"
// 注意以下协议才会正常返回:'http:', 'https:', 'ws:', 'wss:', 'file:', 'ftp:'
const protocol = /^([a-z]+:)\/\//
- username和password
// 匹配username和password, 这部分可能没有
// ? 0次或1次
// 认为username中不可包含":",password中不可包含"@"
const user = /(?:([^:]+):([^@]+)@)?/
- hostname
// hoatname 中不会包含":?#/"四个字符的一个
// 出现':'进入port,"?"认为进入query,'#'进入hash,'/'则进入pathname
const hostname = /([^:?#/]+)?/
- port
// 匹配端口号,可省略端口号
// ? 0次或1次(端口号可省略)
// ?: 只匹配不捕获,不需要捕获如":8080"这样的内容
// 端口号由一位到多位数字组成
const port = /(?::(\d+))?/
- pathname
// 匹配pathname
// 可能没有
const pathname = /([^?#]+)?/
- query
// 匹配query
// '?'后为query,'?'需转义
// 不为'#','#'为hash的标识
// 可能没有
const query = /(\?[^#]+)?/
- hash
// 匹配hash,可能没有
// #为hash的标识,'#'后可跟除'\n'之外的任意字符
const hash = /(#.+)?/
何为hash
- '#' 代表网页的位置,右侧字符为该位置的标识
- '#' http请求不包含'#'后面的内容
- '#' 后的任何字符都会被解读为位置标识
encodeURIComponent
- 把字符串作为 URI 组件进行编码
- 不会对 ASCII 字母和数字进行编码,也不会对这些 ASCII 标点符号进行编码: - _ . ! ~ * ' ( )
- 会转义用于分隔 URI 各个部分的标点符号
