算法分析的相关知识,内容包括什么是算法分析、大 O 表示法、“变位词”判断问题、Python 数据类型的性能。
一、什么是算法分析
1. 对比程序,还是算法?
如何对比两个程序?
- 看起来不同,但解决同一个问题的程序,哪个“更好”?
程序和算法的区别
- 算法是对问题解决的分步描述
- 程序则是采用某种编程语言实现的算法,同一个算法通过不同的程序员采用不同的编程语言,能产生很多程序
2. 累计求和问题
我们来看一段程序,完成从1到n的累加,输出总和
- 设置累计变量=0
- 从1到n循环,逐次累加到累计变量
- 返回累计变量

再看第二段程序,是否感觉怪怪的?
- 但实际上本程序功能与前面那段相同
- 这段程序失败之处在于:变量命名词不达意,以及包含了无用的垃圾代码

3. 算法分析的概念
较程序的“好坏”,有更多因素
- 代码风格、可读性等等
我们主要感兴趣的是算法本身特性
算法分析主要就是从计算资源消耗的角度来评判和比较算法更高效利用计算资源,或者更少占用计算资源的算法,就是好算法
从这个角度,前述两段程序实际上是基本相同的,它们都采用了一样的算法来解决累计求和问题
4. 计算资源指标
何为计算资源?
一种是算法解决问题过程中需要的存储空间或内存,但存储空间受到问题自身数据规模的变化影响,要区分哪些存储空间是问题本身描述所需,哪些是算法占用,不容易
另一种是算法的执行时间我们可以对程序进行实际运行测试,获得真实的 运行时间
5. 运行时间检测
Python中有一个time模块,可以获取计算机系统当前时间,在算法开始前和结束后分别记录系统时间,即可得到运行时间
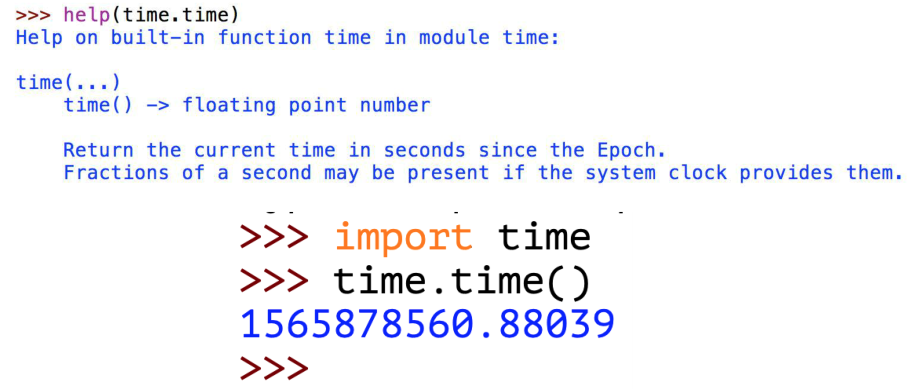
累计求和程序的运行时间检测
- 用time检测总运行时间
- 返回累计和,以及运行时间(秒)

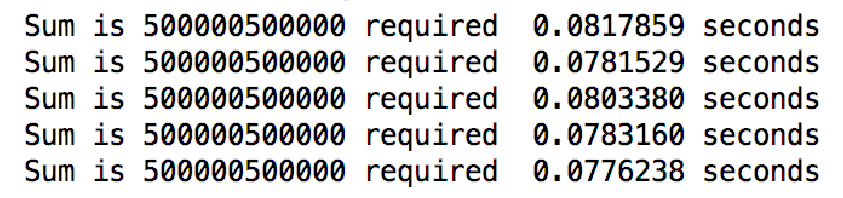
在交互窗口连续运行5次看看,1到10,000累加,每次运行约需0.0007秒
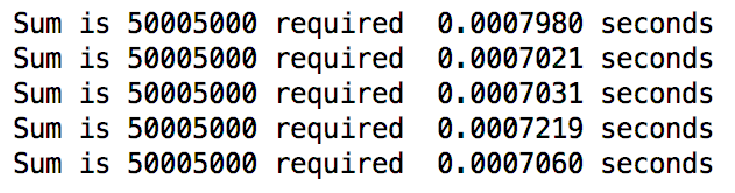
如果累加到100,000?看起来运行时间增加到10,000的10倍
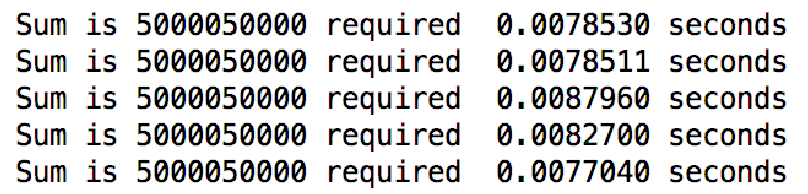
进一步累加到1,000,000?运行时间又是100,000的10倍了
6. 第二种无迭代的累计算法
利用求和公式的无迭代算法

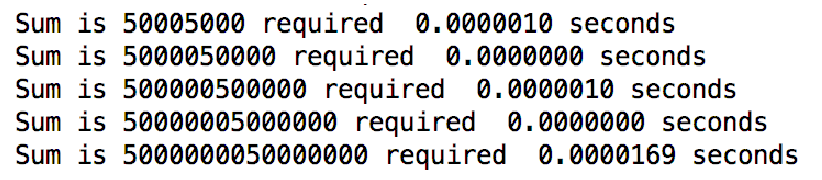
采用同样的方法检测运行时间10,000; 100,000; 1,000,000; 10,000,000; 100,000,000
需要关注的两点
- 这种算法的运行时间比前种都短很多
- 运行时间与累计对象n的大小没有关系(前种算法是倍数增长关系)
新算法运行时间几乎与需要累计的数目无关
7. 运行时间检测的分析
观察一下第一种迭代算法
- 包含了一个循环,可能会执行更多语句
- 这个循环运行次数跟累加值n有关系,n增加,循环次数也增加

但关于运行时间的实际检测,有点问题
- 关于编程语言和运行环境
同一个算法,采用不同的编程语言编写,放在不同的机器上运行,得到的运行时间会不一样,有时候会大不一样,比如把非迭代算法放在老旧机器上跑,甚至可能慢过新机器上的迭代算法
我们需要更好的方法来衡量算法运行时间,这个指标与具体的机器、程序、运行时段都无关
二、大 O 表示法
1. 算法时间度量指标
一个算法所实施的操作数量或步骤数可作为独立于具体程序/机器的度量指标。
哪种操作跟算法的具体实现无关?需要一种通用的基本操作来作为运行步骤的计量单位
赋值语句是一个合适的选择,一条赋值语句同时包含了(表达式)计算和(变量)存储两个基本资源
仔细观察程序设计语言特性,除了与计算资源无关的定义语句外,主要就是三种控制流语句和赋值语句,而控制流仅仅起了组织语句的作用,并不实施处理。
2. 赋值语句执行次数
分析SumOfN的赋值语句执行次数,对于“问题规模”n,赋值语句数量T(n)=1+n,那么,什么是问题规模?

3. 问题规模影响算法执行时间
问题规模:影响算法执行时间的主要因素
在前n个整数累计求和的算法中,需要累计的整数个数合适作为问题规模的指标,前100,000个整数求和对比前1,000个整数求和,算是同一问题的更大规模
算法分析的目标是要找出问题规模会怎么影响一个算法的执行时间
4. 数量级函数 Order of Magnitude
基本操作数量函数T(n)的精确值并不是特别重要,重要的是T(n)中起决定性因素的主导部分。用动态的眼光看,就是当问题规模增大的时候,T(n)中的一些部分会盖过其它部分的贡献
数量级函数描述了T(n)中随着n增加而增加速度最快的主导部分,称作“大O”表示法,记作O(f(n)),其中f(n)表示T(n)中的主导部分
5. 确定运行时间数量级大O的方法
例1:T(n)=1+n
当n增大时,常数1在最终结果中显得越来越无足轻重,所以可以去掉1,保留n作为主要部分,运行时间数量级就是O(n)
例2:T(n)=5n2+27n+1005
当n很小时,常数1005其决定性作用但当n越来越大,n2项就越来越重要,其它两项对结果的影响则越来越小。同样,n2项中的系数5,对于n2的增长速度来说也影响不大。所以可以在数量级中去掉27n+1005,以及系数5 的部分,确定为O(n2)
6. 影响算法运行时间的其它因素
有时决定运行时间的不仅是问题规模,某些具体数据也会影响算法运行时间,分为最好、最差和平均情况,平均状况体现了算法的主流性能对算法的分析要看主流,而不被某几种特定的运行状况所迷惑
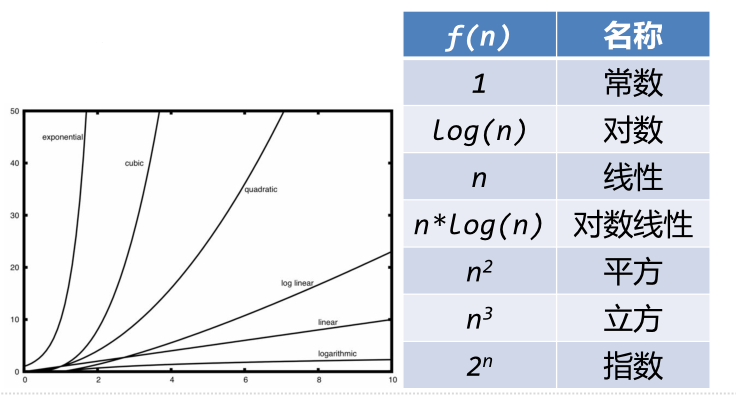
7. 常见的大O数量级函数
通常当n较小时,难以确定其数量级,当n增长到较大时,容易看出其主要变化量级
8. 从代码分析确定执行时间数量级函数
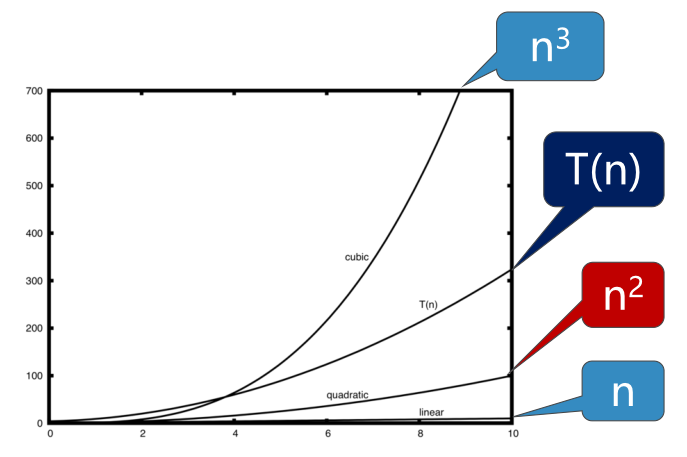
代码赋值语句可以分为4个部分。T(n) = 3+3n2+2n+1 = 3n2+2n+4

仅保留最高阶项n2,去掉所有系数,数量级为O(n2)
9. 其它算法复杂度表示法
大O表示法:表示了所有上限中最小的那个上限。
大𝛀表示法:表示了所有下限中最大的那个下限

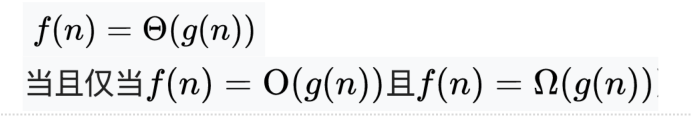
三、“变位词”判断问题
1. “变位词”判断问题
问题描述:
所谓“变位词”是指两个词之间存在组成字母的 重新排列关系,如:heart和earth,python和typhon。为了简单起见,假设参与判断的两个词仅由小写字母构成,而且长度相等
解题目标:
写一个bool函数,以两个词作为参数,返回这两个词是否变位词。这个问题可以很好展示同一问题的不同数量级算法
2. 解法1:逐字检查
解法思路
将词1中的字符逐个到词2中检查是否存在存在就“打勾”标记(防止重复检查)。如果每个字符都能找到,则两个词是变位词,只要有1个字符找不到,就不是变位词
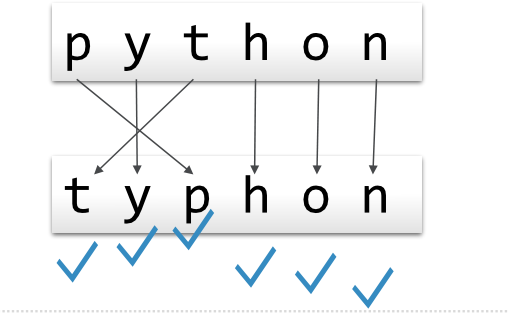
程序技巧
实现“打勾”标记:将词2对应字符设为None,由于字符串是不可变类型,需要先复制到列表中

问题规模:词中包含的字符个数n,主要部分在于两重循环
外层循环遍历s1每个字符,将内层循环执行n次,而内层循环在s2中查找字符,每个字符的对比次数,分别是1、2…n中的一个,而且各不相同
所以总执行次数是1+2+3+……+n,可知其数量级为O(n2)
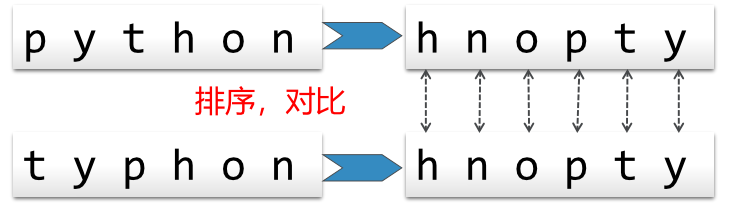
3. 解法2:排序比较
解题思路
将两个字符串都按照字母顺序排好序,再逐个字符对比是否相同,如果相同则是变位词,有任何不同就不是变位词

4. 解法2:排序比较-算法分析
粗看上去,本算法只有一个循环,最多执行n次,数量级是O(n),但循环前面的两个sort并不是无代价的,排序算法采用不同的解决方案,其运行时间数量级差不多是O(n2)或者O(n log n),大过循环的O(n)
所以本算法时间主导的步骤是排序步骤
本算法的运行时间数量级就等于排序过程的数量级O(n log n)
5. 解法3:暴力法
暴力法解题思路为:穷尽所有可能组合将s1中出现的字符进行全排列,再查看s2是否出现在全排列列表中
这里最大困难是产生s1所有字符的全排列,根据组合数学的结论,如果n个字符进行全排列,其所有可能的字符串个数为n!
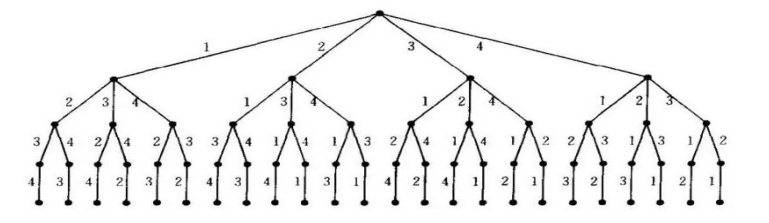
我们已知 n! 的增长速度甚至超过2^n,例如,对于20个字符长的词来说,将产生20!=2,432,902,008,176,640,000个候选词,如果每微秒处理1个候选词的话,需要近8万年时间来做完所有的匹配。
结论:暴力法恐怕不能算是个好算法
6. 解法4:计数比较
解题思路:
对比两个词中每个字母出现的次数,如果26个字母出现的次数都相同的 话,这两个字符串就一定是变位词 具体做法:
为每个词设置一个26位的计数器,先检查每个词,在计数器中设定好每个字母出现的次数。计数完成后,进入比较阶段,看两个字符串的计数器是否相同,如果相同则输出是变位词的结论

7. 解法4:计数比较-算法分析
计数比较算法中有3个循环迭代,但不像解法1那样存在嵌套循坏
前两个循环用于对字符串进行计数,操作次数等于字符串长度n,第3个循环用于计数器比较,操作次数总是26次
所以总操作次数T(n)=2n+26,其数量级为O(n),这是一个线性数量级的算法,是4个变位词判断算法中性能最优的
值得注意的是,本算法依赖于两个长度为26的计数器列表,来保存字符计数,这相比前3个算法需要更多的存储空间。如果考虑由大字符集构成的词(如中文具有上万不同字符),还会需要更多存储空间。
牺牲存储空间来换取运行时间,或者相反,这种在时间空间之间的取舍和权衡,在选择问题解法的过程中经常会出现。
四、Python 数据类型的性能
前面我们了解了“大O表示法”以及对不同的算法的评估,下面来讨论下Python两种内置数据类型上各种操作的大O数量级,列表list和字典dict。这是两种重要的Python数据类型
1. 对比list和dict的操作
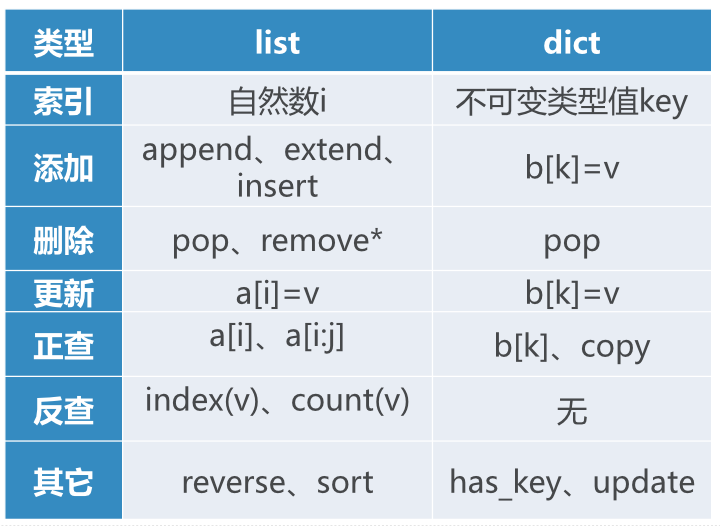
2. List列表数据类型
List类型各种操作(interface)的实现方法有很多,如何选择具体哪种实现方法?
总的方案就是,让最常用的操作性能最好,牺牲不太常用的操作。80/20准则:80%的功能其使用率只有20%
3. List列表数据类型常用操作性能
最常用的是:按索引取值和赋值(v=a[i], a[i]= v)
- 由于列表的随机访问特性,这两个操作执行时间与列表大小无关,均为O(1)
另一个是列表增长,可以选择append()
和__add__()“+”
- lst.append(v),执行时间是O(1)
- lst= lst+ [v],执行时间是O(n+k),其中k是被加的列表长度
选择哪个方法来操作列表,决定了程序的性能
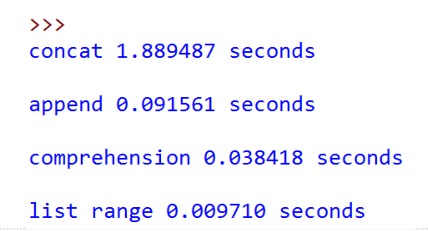
4. 4种生成前n个整数列表的方法

5. 使用timeit模块对函数计时
创建一个Timer对象,指定需要反复运行的语句和只需要运行一次的“安装语句”,然后调用这个对象的timeit方法,其中可以指定反复运行多少次

6. 4种生成前n个整数列表的方法计时
我们看到,4种方法运行时间差别很大
- 列表连接(concat)最慢,List range最快,速度相差近200倍。
- append也要比concat快得多
- 另外,我们注意到列表推导式速度是append两倍的样子
7. List基本操作的大O数量级

8. list.pop的计时试验
我们注意到pop这个操作
- pop()从列表末尾移除元素,O(1)
- pop(i)从列表中部移除元素,O(n)
原因在于Python所选择的实现方法
从中部移除元素的话,要把移除元素后面的元素全部向前挪位复制一遍,这个看起来有点笨拙,但这种实现方法能够保证列表按索引取值和赋值 的操作很快,达到O(1),这也算是一种对常用和不常用操作的折衷方案
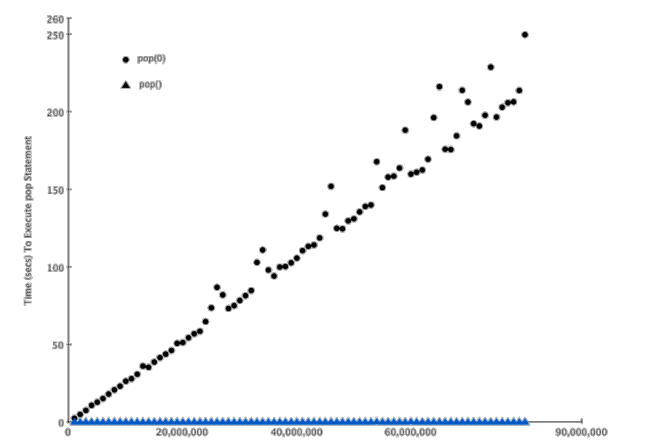
为了验证表中的大O数量级,我们把两种情况下的pop操作来实际计时对比
- 相对同一个大小的list,分别调用pop()和pop(0)
对不同大小的list做计时,期望的结果是pop()的时间不随list大小变化,pop(0)的时间随着list变大而变长

首先我们看对比,对于长度2百万的列表,执行1000次,pop()时间是0.0007秒,pop(0)时间是0.8秒,相差1000倍

我们通过改变列表的大小来测试两个操作的增长趋势

我们通过改变列表的大小来测试两个操作的增长趋势
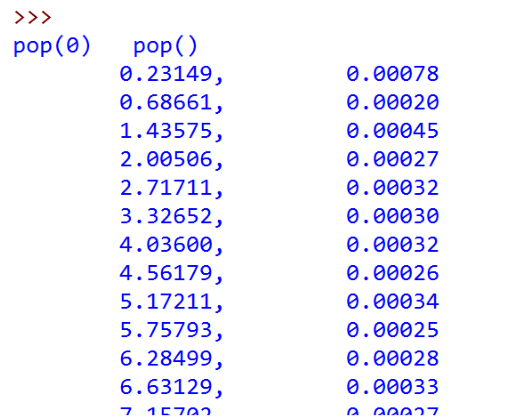
将试验数据画成图表,可以看出增长趋势,pop()是平坦的常数,pop(0)是线性增长的趋势
9. dict数据类型
字典与列表不同,根据关键码(key)找到数据项,而列表是根据位置(index),最常用的取值get和赋值set,其性能为O(1),另一个重要操作contains(in)是判断字典中是否存在某个关键码(key),这个性能也是O(1)
10. list和dict的in操作对比
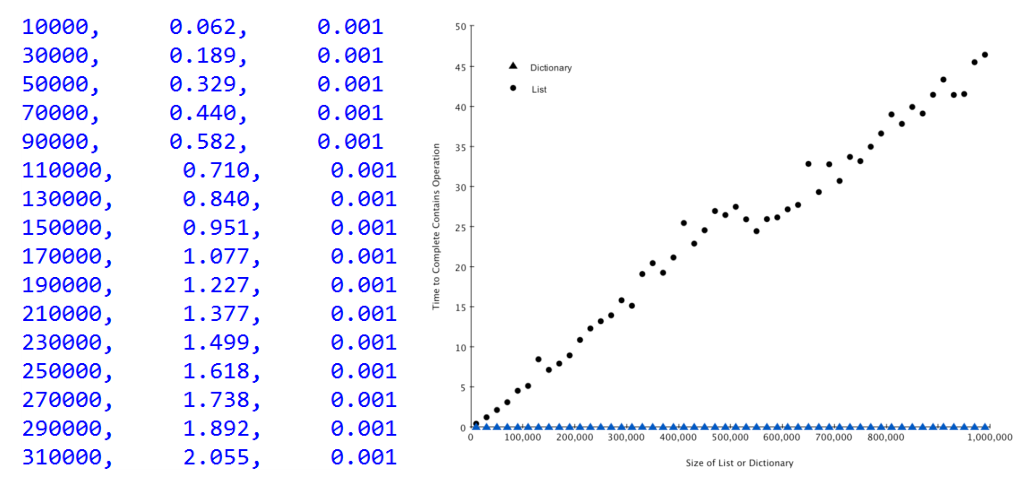
设计一个性能试验来验证list中检索一个值,以及dict中检索一个值的计时对比。生成包含连续值的list和包含连续关键码key的dict,用随机数来检验操作符in的耗时。

可见字典的执行时间与规模无关,是常数,而列表的执行时间则随着列表的规模加大而线性上升
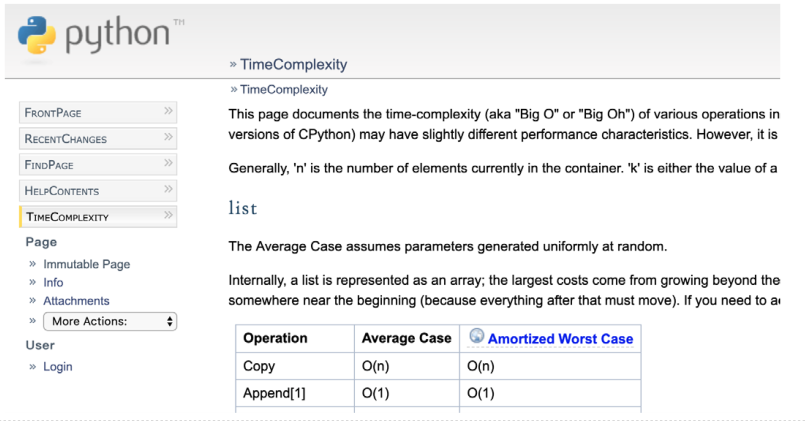
11. 更多Python数据类型操作复杂度
Python官方的算法复杂度网站:wiki.python.org/moin/TimeCo…