

第 1 题:浏览器缓存读取规则
可以分成 Service Worker、Memory Cache、Disk Cache 和 Push Cache,那请求的时候 from memory cache 和 from disk cache 的依据是什么,哪些数据什么时候存放在 Memory Cache 和 Disk Cache中?
1.Service Worker
Service Worker 是运行在浏览器背后的独立线程,一般可以用来实现缓存功能。使用 Service Worker的话,传输协议必须为 HTTPS。因为 Service Worker 中涉及到请求拦截,所以必须使用 HTTPS 协议来保障安全。Service Worker 的缓存与浏览器其他内建的缓存机制不同,它可以让我们自由控制缓存哪些文件、如何匹配缓存、如何读取缓存,并且缓存是持续性的。
Service Worker 实现缓存功能一般分为三个步骤:首先需要先注册 Service Worker,然后监听到 install 事件以后就可以缓存需要的文件,那么在下次用户访问的时候就可以通过拦截请求的方式查询是否存在缓存,存在缓存的话就可以直接读取缓存文件,否则就去请求数据。
当 Service Worker 没有命中缓存的时候,我们需要去调用 fetch 函数获取数据。也就是说,如果我们没有在 Service Worker 命中缓存的话,会根据缓存查找优先级去查找数据。但是不管我们是从 Memory Cache 中还是从网络请求中获取的数据,浏览器都会显示我们是从 Service Worker 中获取的内容。
2.Memory Cache
Memory Cache 也就是内存中的缓存,主要包含的是当前中页面中已经抓取到的资源,例如页面上已经下载的样式、脚本、图片等。读取内存中的数据肯定比磁盘快,内存缓存虽然读取高效,可是缓存持续性很短,会随着进程的释放而释放。一旦我们关闭 Tab 页面,内存中的缓存也就被释放了。
那么既然内存缓存这么高效,我们是不是能让数据都存放在内存中呢?
这是不可能的。计算机中的内存一定比硬盘容量小得多,操作系统需要精打细算内存的使用,所以能让我们使用的内存必然不多。
当我们访问过页面以后,再次刷新页面,可以发现很多数据都来自于内存缓存
内存缓存中有一块重要的缓存资源是preloader相关指令(例如<link rel="prefetch">)下载的资源。总所周知preloader的相关指令已经是页面优化的常见手段之一,它可以一边解析js/css文件,一边网络请求下一个资源。
3.Disk Cache
Disk Cache 也就是存储在硬盘中的缓存,读取速度慢点,但是什么都能存储到磁盘中,比之 Memory Cache 胜在容量和存储时效性上。
在所有浏览器缓存中,Disk Cache 覆盖面基本是最大的。它会根据 HTTP Herder 中的字段判断哪些资源需要缓存,哪些资源可以不请求直接使用,哪些资源已经过期需要重新请求。并且即使在跨站点的情况下,相同地址的资源一旦被硬盘缓存下来,就不会再次去请求数据。绝大部分的缓存都来自 Disk Cache,关于 HTTP 的协议头中的缓存字段,我们会在下文进行详细介绍。
浏览器会把哪些文件丢进内存中?哪些丢进硬盘中?
关于这点,网上说法不一,不过以下观点比较靠得住:
对于大文件来说,大概率是不存储在内存中的,反之优先
当前系统内存使用率高的话,文件优先存储进硬盘
4.Push Cache
Push Cache(推送缓存)是 HTTP/2 中的内容,当以上三种缓存都没有命中时,它才会被使用。它只在会话(Session)中存在,一旦会话结束就被释放,并且缓存时间也很短暂,在Chrome浏览器中只有5分钟左右,同时它也并非严格执行HTTP头中的缓存指令。
Push Cache 在国内能够查到的资料很少,也是因为 HTTP/2 在国内不够普及。这里推荐阅读Jake Archibald的HTTP/2 push is tougher than I thought这篇文章,文章中的几个结论:
所有的资源都能被推送,并且能够被缓存,但是 Edge 和 Safari 浏览器支持相对比较差
可以推送 no-cache 和 no-store 的资源
一旦连接被关闭,Push Cache 就被释放
多个页面可以使用同一个HTTP/2的连接,也就可以使用同一个Push Cache。这主要还是依赖浏览器的实现而定,出于对性能的考虑,有的浏览器会对相同域名但不同的tab标签使用同一个HTTP连接。
Push Cache 中的缓存只能被使用一次
浏览器可以拒绝接受已经存在的资源推送
你可以给其他域名推送资源
如果以上四种缓存都没有命中的话,那么只能发起请求来获取资源了。
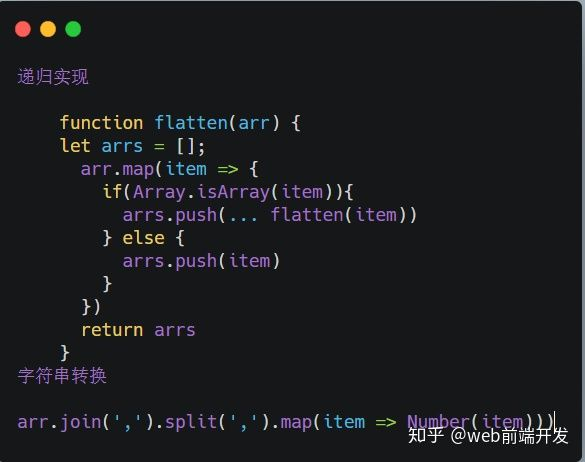
第 2 题:使用迭代的方式实现 flatten 函数。
迭代的实现:

第 3 题:算法题「旋转数组」
给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数。
示例 1:

示例 2:

问题转化为:数组的末尾k个元素移动到数组前面
末尾元素:arr.splice(-k%arr.length)的返回值
剩余元素:arr
const moveArr = (arr,k)=>arr.splice(-k%arr.length).concat(arr)
第 4 题:打印出 1 - 10000 之间的所有对称数
例如:121、1331 等

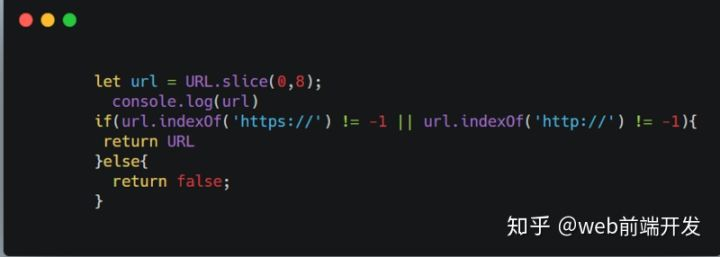
第 5 题:在输入框中如何判断输入的是一个正确的网址。
工作中遇到校验网址是否正确,查了好多方法发现实现不了复杂的校验,最后定的规则是校验是不是以https://或http://开头
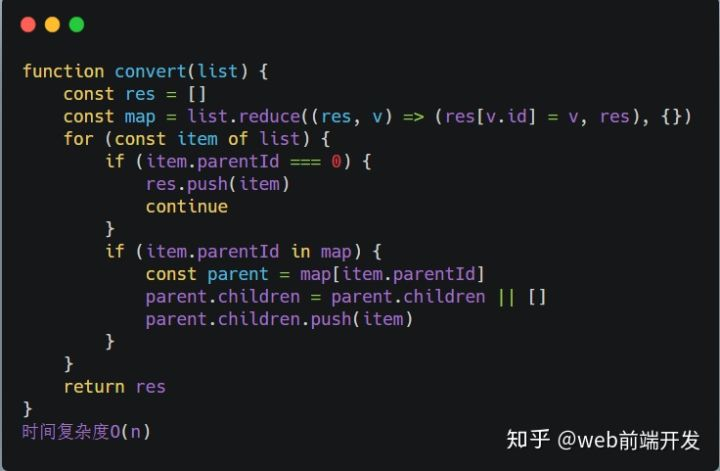
第 6 题:实现 convert 方法,把原始 list 转换成树形结构,要求尽可能降低时间复杂度
以下数据结构中,id 代表部门编号,name 是部门名称,parentId 是父部门编号,为 0 代表一级部门,现在要求实现一个 convert 方法,把原始 list 转换成树形结构,parentId 为多少就挂载在该 id 的属性 children 数组下,结构如下:

第 7 题:实现模糊搜索结果的关键词高亮显示
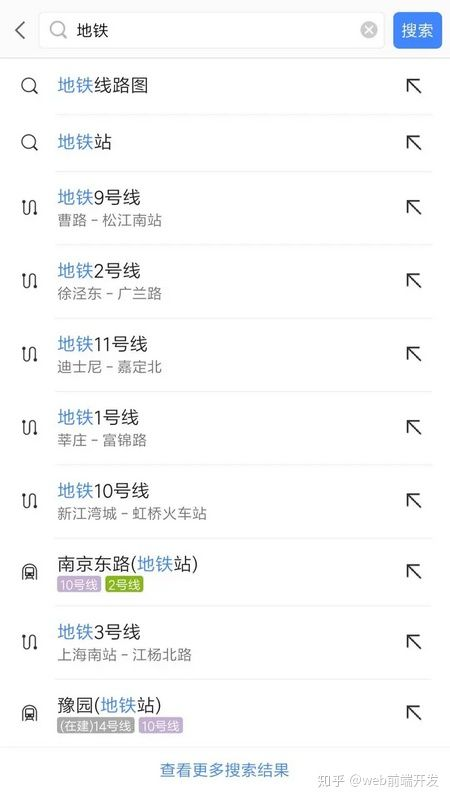
我的大概思路是,用正则替换掉关键词。
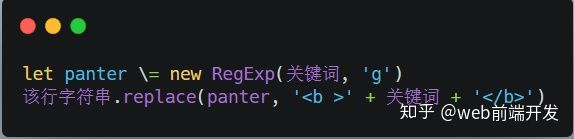
ps:如果是vue项目,直接与v-html结合使用更爽哦~
第 8 题:1000-div问题
难度:阿里p5 ~ p6、腾讯t21 ~ t22
一次性插入1000个div,如何优化插入的性能
使用Fragment
var fragment = document.createDocumentFragment();
fragment.appendChild(elem);**
向1000个并排的div元素中,插入一个平级的div元素,如何优化插入的性能
**
- 先display:none 然后插入 再display:block
- 赋予key,然后使用virtual-dom,先render,然后diff,最后patch
- 脱离文档流,用GPU去渲染,开启硬件加速
