

准备
Flink:1.8.1
hadoop:2.6.7+
zookeeper: 3.4.5
kafka:2.x
1.下载代码:
git clone https://github.com/DTStack/flinkStreamSQL.git
2.修复代码的依赖
[a].com.aiweiergou.tool.logger.api.ChangeLogLevelProcess;
下载袋鼠云开源框架技术交流群 钉钉群【30537511】里的jar包,放到launcher的lib目录,然后修改launcher的pom.xml指定本地jar包

<!--<dependency>-->
<!--<groupId>com.aiweiergou</groupId>-->
<!--<artifactId>tools-logger</artifactId>-->
<!--<version>${logger.tool.version}</version>-->
<!--</dependency>-->
<dependency>
<groupId>com.aiweiergou</groupId>
<artifactId>tools-logger</artifactId>
<version>${logger.tool.version}</version>
<scope>system</scope>
<systemPath>${project.basedir}/lib/tools-logger-1.0.0-SNAPSHOT.jar</systemPath>
</dependency>
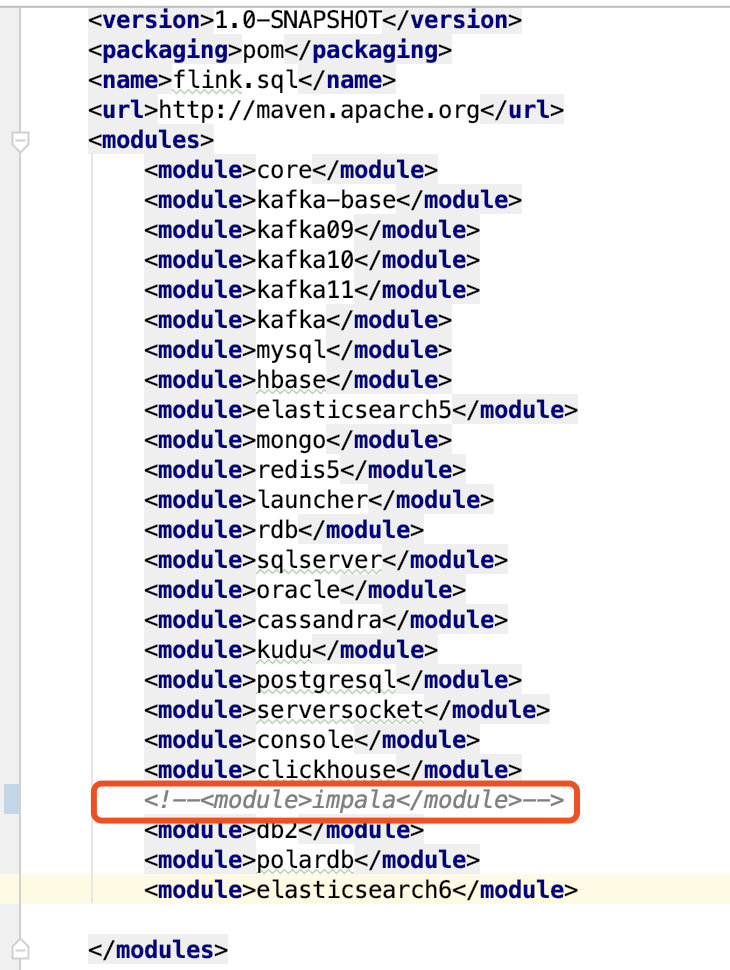
[b] 需要注释掉impala代码(如果需要使用,需要自己研究) 根目录pom.xml下
3.编译
mvn clean package -Dmaven.test.skip
4.编写配置文件
配置文件主要分两部分
- 提交命令 submit ...
- 你的Flink SQL文件,create table...
本次演示的主要是kafka -> MySQL
提交命令
sh submit.sh \
-sql /Users/lionli/lixiyan/flink/flinkSqlPlatform/sqlDev.txt \
-name xctest \
-localSqlPluginPath /Users/lionli/lixiyan/flink/flinkSqlPlatform/flinkStreamSQL/plugins \
-remoteSqlPluginPath /Users/lionli/lixiyan/flink/flinkSqlPlatform/flinkStreamSQL/plugins \
-mode yarnPer \
-yarnconf /Users/lionli/lixiyan/app/hadoop-2.7.6/etc/hadoop \
-confProp {} \
-flinkconf /Users/lionli/lixiyan/app/flink-1.8.1/conf \
-flinkJarPath /Users/lionli/lixiyan/app/flink-1.8.1/lib
Flink SQL文件-sqlDev.txt
CREATE TABLE MyTable( name varchar, channel varchar, pv int, xctime bigint )WITH( type ='kafka', bootstrapServers ='node001:9092', zookeeperQuorum ='node001:2181/kafka', offsetReset ='latest', topic ='nbTest1', parallelism ='2' );CREATE TABLE MyResult( channel varchar, pv int )WITH( type ='mysql', url ='jdbc:mysql://node001:3306/test?charset=utf8', userName ='username', password ='password', tableName ='pv2', parallelism ='1' );
insert into MyResult select channel,pv from MyTable
ps: 并行度设置需要设置不一样,不然会导致kafka无法进出数据(感谢雾幻)
5.启动运行
- 启动zookeeper
- 启动kafka
- 启动Hadoop
- 启动MySQL
ps:flink1.8 需要编译后的,不能是官网下的tag.gz包,lib目录需要同时具备以下的两个jar包

启动:在flinkStreamSQL的bin执行脚本命令
sh submit.sh \
-sql /Users/lionli/lixiyan/flink/flinkSqlPlatform/sqlDev.txt \
-name xctest \
-localSqlPluginPath /Users/lionli/lixiyan/flink/flinkSqlPlatform/flinkStreamSQL/plugins \
-remoteSqlPluginPath /Users/lionli/lixiyan/flink/flinkSqlPlatform/flinkStreamSQL/plugins \
-mode yarnPer \
-yarnconf /Users/lionli/lixiyan/app/hadoop-2.7.6/etc/hadoop \
-confProp {} \
-flinkconf /Users/lionli/lixiyan/app/flink-1.8.1/conf \
-flinkJarPath /Users/lionli/lixiyan/app/flink-1.8.1/lib
查看:查看yarn和ApplicationMaster,已经成功启动Flink
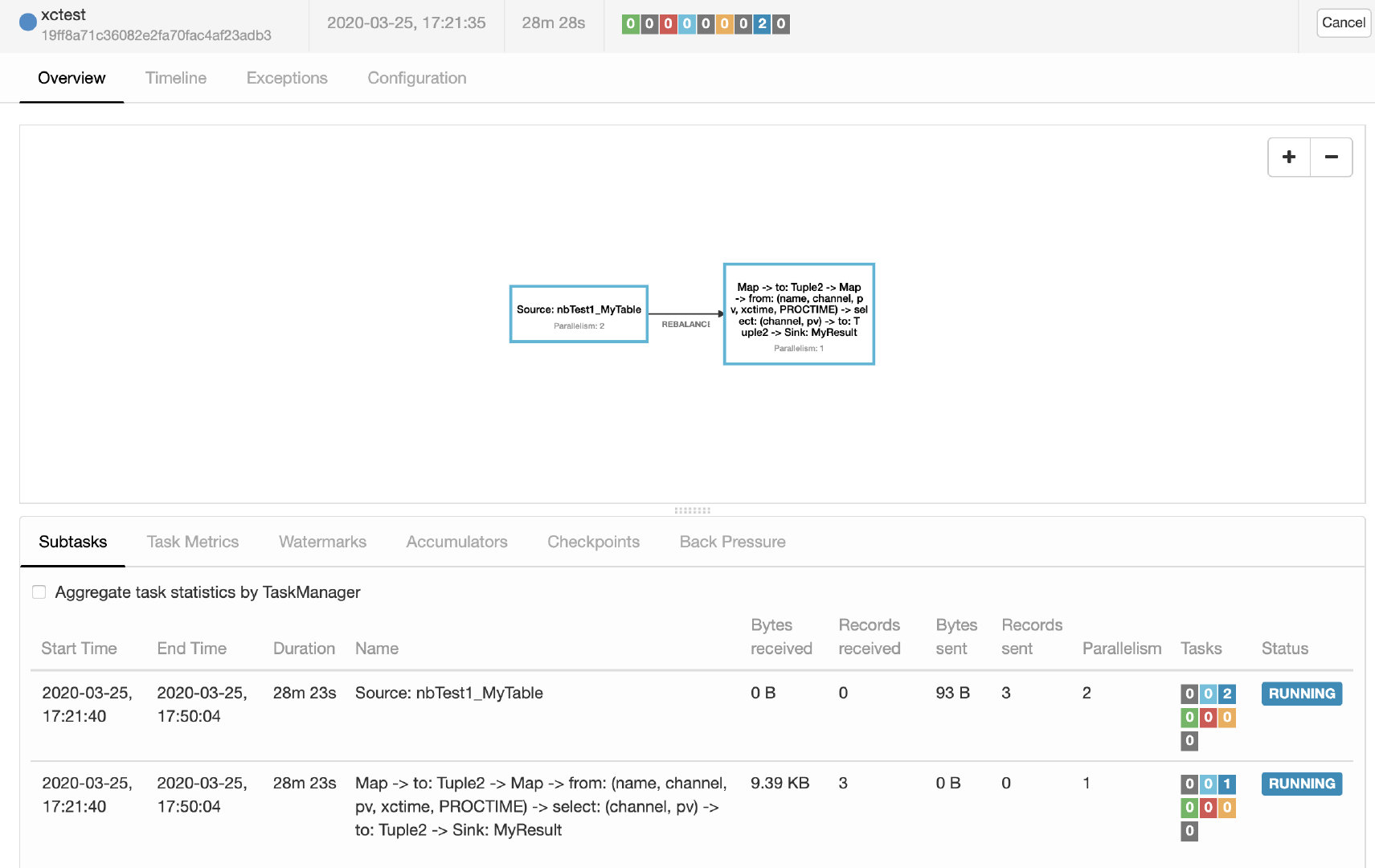
输入:在kafka输入数据,这里输入3行数据

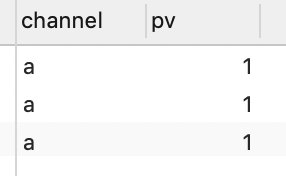
查看MySQL的pv2表,已经看到插入的结果
-- EOF--
