

JS获取HTML DOM元素的方法
1.通过ID选取元素
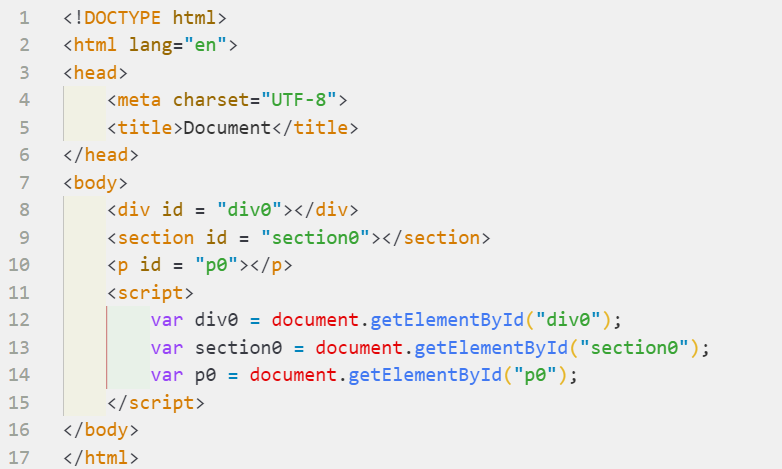
任何HTML元素可以有一个id属性,在文档中该值必须唯一,即同一个文档中的两个元素不能有相同的ID。可以用Document对象的getElementById()方法获取一个基于唯一ID的元素。
例如
2.通过名字选取元素
HTML的name属性类似id属性,name是给元素分配名字,但是区别id,name属性的值不是必须为一:多个元素可能有同样的名字,在表单中,单选和复选按钮通常是这种情况,而且,和id不一样的是name属性只在少数的HTML元素中起效,包括表单、表单元素、iframe和img元素。基于name属性的值选取HTML元素,可以使用Document对象的getElementByName()方法。
例如

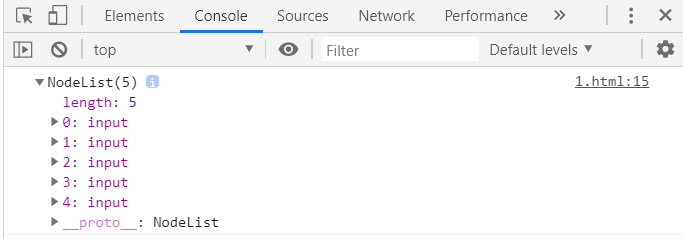
注意:getElementByName()定义在HTMLDocument类中,而不在Document类中,所以它只针对HTML文档可用,在XML文档中不可用。它返回一个NodeList对象,后者的行为类似一个包含若干Element对象的只读数组。
3.通过标签名获取元素
Document对象的getElementsByTagName()方法可以用来选取指定类型(标签名)的所有HTML或XML元素。
例如

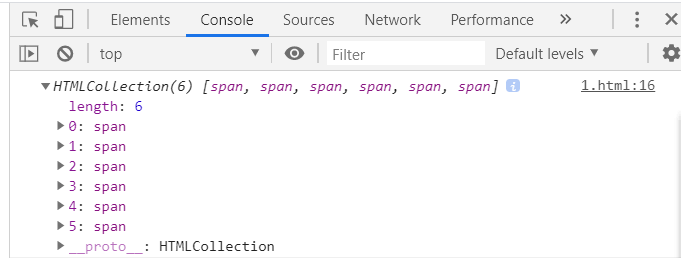
类似于getElementByName(),getElementsByTagName()返回一个NodeList对象。在NodeList中返回的元素按照在文档中的顺序排序,可用如下代码选取文档中的第一个span元素:
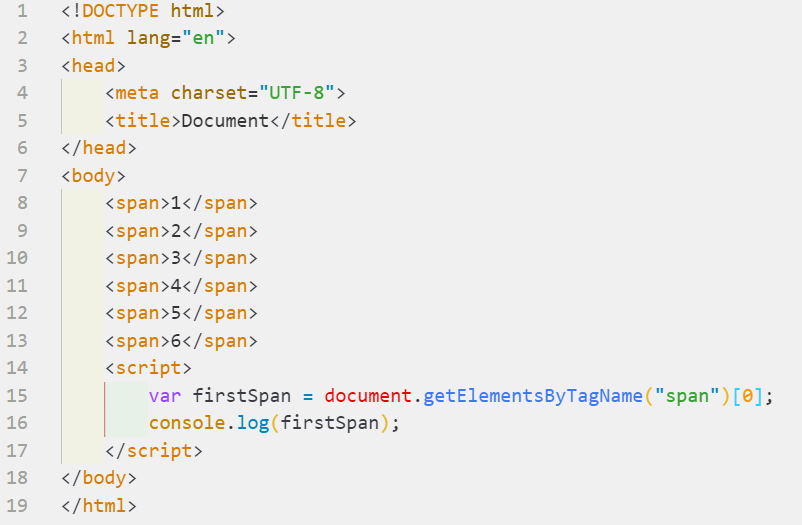

4.通过CSS类选取元素
类似getElementsByTagName(),在HTML文档和HTML元素上都可以调用getElementsByClassName(),它的返回值是一个实时的NodeList对象,包含文档或元素所有匹配的后代节点。getElementsByClassName()只需要一个字符串参数,但是该字符串可以有多个空格隔开的标识符组成,只有当元素的class属性值包含所有指定的标识符时才匹配,但是标识符的顺序是无关紧要的。

5.通过CSS选择器选取元素
通过Document对象的querySelector()和querySelectorAll()方法选取元素。querySelector()返回第一个匹配的元素(以文档顺序)或者如果没有匹配的元素就返回null。querySelectorAll()返回一个表示文档中匹配选择器的所有元素的NodeList对象。与前面描述的选取元素的方法不同,querySelectorAll()返回的NodeList对象不是实时的:它包含在调用时刻选择器所匹配的元素,但它并不更新后续文档的变化。如果没有匹配的元素,querySelectorAll()将返回一个空的NodeList对象。如果选择器字符串非法,querySelectorAll()将抛出一个异常。
