

HBase架构组成
从物理结构上,HBase包含了三种类型的server,zookeeper、HMaster、region server,采用一种主从模式的结构。
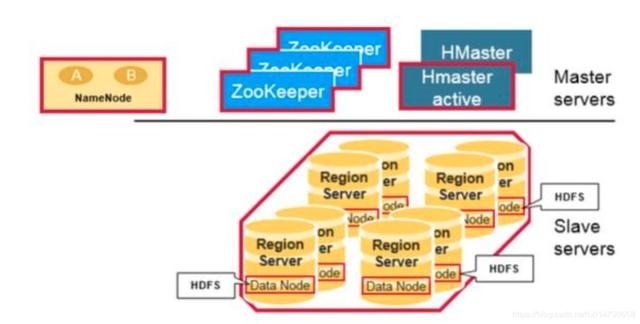
- region server主要用来服务读和写操作。当用户通过client访问数据时,client会和HBase RegionServer 进行直接通信。
- HMaster主要进行region server的管理、DDL(创建、删除表)操作等。
- Zookeeper是HDFS(Hadoop Distributed File System)的一部分,主要用来维持整个集群的存活,保障了HA,故障自动转移。
而底层的存储,还是依赖于HDFS的。
- Hadoop的DataNode存储了Region Server所管理的数据,所有HBase的数据都是存在HDFS中的。
- Hadoop的NameNode维护了所有物理数据块的metadata。
1.1 region server
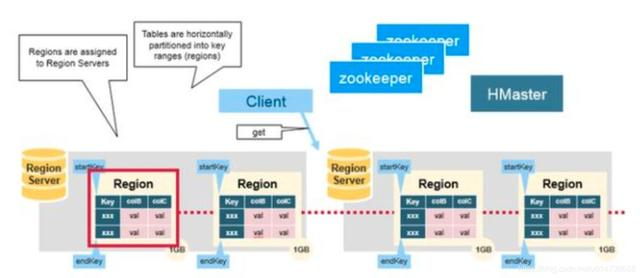
HBase 的tables根据rowkey的范围进行水平切分,切分后分配到各个regions。一个region包含一个表在start key和end key所有行。region会被分配到集群中的各个region server,而用户都是跟region server进行读写交互。一个region一般建议大小在5-10G。
1.2 HBase HMaster
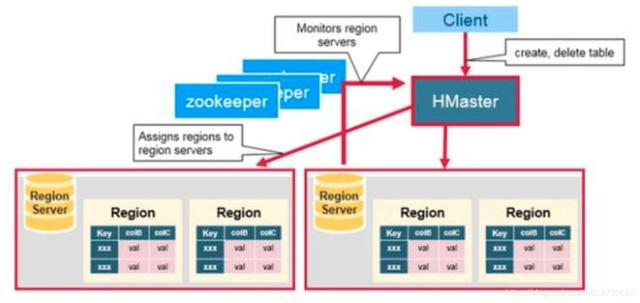
一般也叫作HMaster,HMaster主要职责包括两个方面:
- 与region server的交互,对region server进行统一管理:启动时region的分配、崩溃后恢复的region重新分配、负载均衡的region重新分配
- Admin相关功能:创建、删除、更新表结构等DDL操作
1.3 Zookeeper
HBase使用Zookeeper作为分布式协调服务,来维护集群内的server状态。
Zookeeper通过 heartbeat 维护了哪些server是存活并可用的,并提供server的故障通知。同时,使用一致性协议来保证各个分布式节点的一致性。
这里,需要特别关注,zookeeper负责来HMaster的选举工作,如果一个HMater节点宕机了,就会选择另一个HMaster节点进入active状态。
1.4 这些组件如何一起协调工作
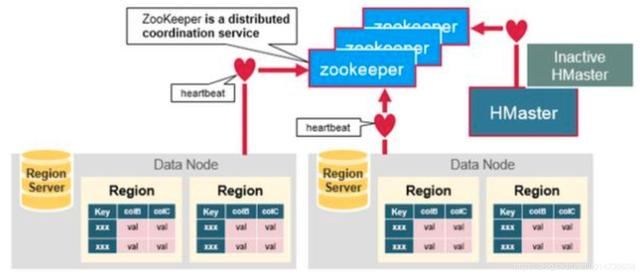
Zookeeper用来共享分布式系统中成员的状态,它会和region server、HMaster(active)保持会话,通过heartbeat维持与这些ephemeral node(zk中的临时节点概念)的活跃会话。
下面,我们可以看到,zk在其中起到了最核心的作用。
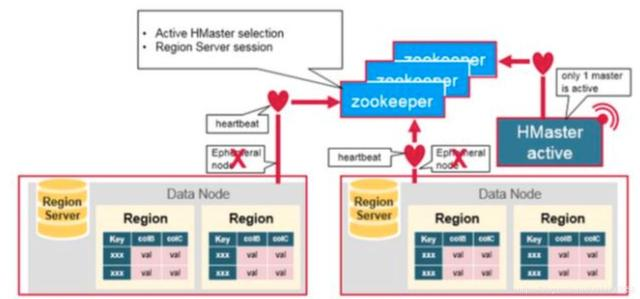
多个HMaster会去竞争成为zookeeper上的临时节点,而zookeeper会将第一个创建成功的HMaster作为唯一当前active的HMaster,其他HMater进入stand by的状态。这个active的HMaster会不断发送heartbeat给zk,其他stand by状态的HMaster节点会监听这个active HMaster的故障信息。一旦发现active HMaster宕机了,就会重新竞争新的active HMaster。这就实现了HMaster的高可用。
每个region server会创建一个ephemeral node。HMaster会监视这些节点来确认哪些region server是可用的,哪些节点发生了故障宕机了。
如果一个region server或者active的HMaster 没有发送heatbeat给zk,那么和zk之间的会话将会过期,并且zk上会删掉这个临时节点,认为这个节点发生故障需要下线了。
其他监听者节点会收到这个故障节点被删除的消息。比如actvie的HMaster会监听region server的消息,如果发现某个region server下线了,那么就会重新分配region server来恢复相应的region数据。再比如,stand by的HMaster节点会监听active 的HMaster节点,一旦收到故障通知,就会竞争上线成为新的active HMaster。
1.5 第一次访问HBase
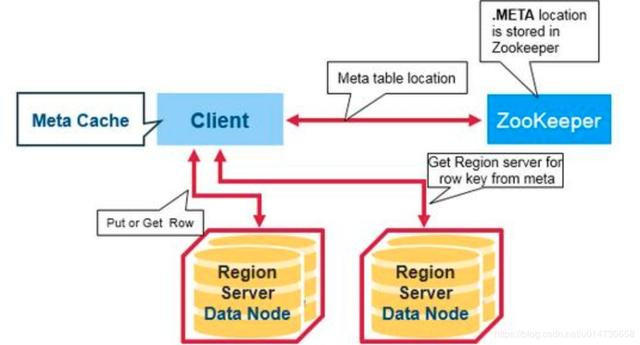
有一个特殊的HBase目录表,叫做META table,保存了集群中各个region的位置。zookeeper中保存了这个meta table 的位置信息。
当我们第一次访问HBase集群时,会做以下操作:
1)客户端从zk中获取保存meta table的位置信息,知道meta table保存在了哪个region server,并在客户端缓存这个位置信息;
2)client会查询这个保存meta table的特定的region server,查询meta table信息,在table中获取自己想要访问的row key所在的region在哪个region server上。
3)客户端直接访问目标region server,获取对应的row
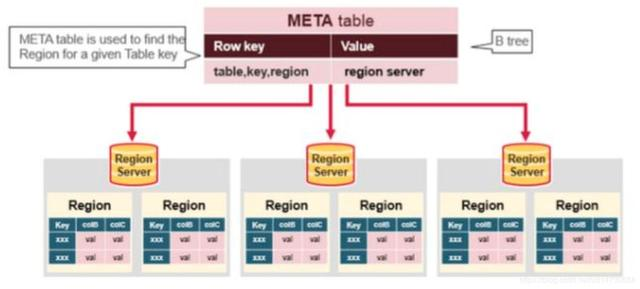
进一步,我们了解一下meta table的存储结构。
- Meta table保存了所有region信息的一张表
- Meta table存储的数据形式类似一颗b树
- 以keyvalue形式保存数据
- Key: region的table name, start key等信息 Values: region server的相关信息
深入region server
一个region server运行在一个HDFS的data node上,并且拥有以下组件:
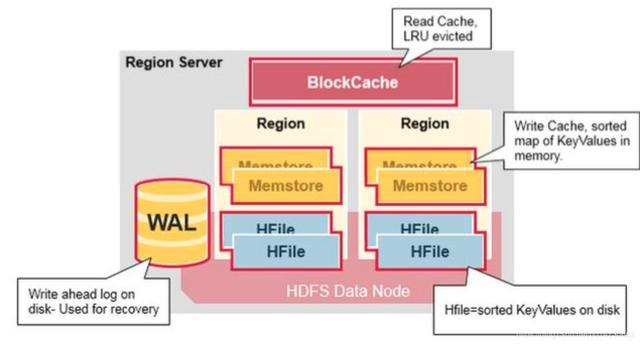
- WAL:全称Write Ahead Log, 属于分布式系统上的文件。主要用来存储还未被持久化到磁盘的新数据。如果新数据还未持久化,节点发生宕机,那么就可以用WAL来恢复这些数据。
- BlockCache:是一个读缓存。它存储了被高频访问的数据。当这个缓存满了后,会清除最近最少访问的数据。
- MenStore: 是一个写缓存。它存储了还未被写入磁盘的数据。它会在写入磁盘前,对自身数据进行排序,从而保证数据的顺序写入。每个region的每个colum family会有一份对应的memstore。(没错,如果节点宕机了,存在这个缓存里的数据没有落盘,可以通过WAL保证这些数据不会丢失)
- HFiles:按照字典序存储各个row的键值。
2.1 HBase写数据与region server的交互
整个写的过程更加复杂,而与region server的交互式最重要的一部分,这里只介绍跟region server的交互。
主要分为两个步骤,写WAL 和 写缓存。
“实际上,这里除了保证数据不丢,还跟提高写入效率有关,具体后续专门写一个相关文档进行展开说明”
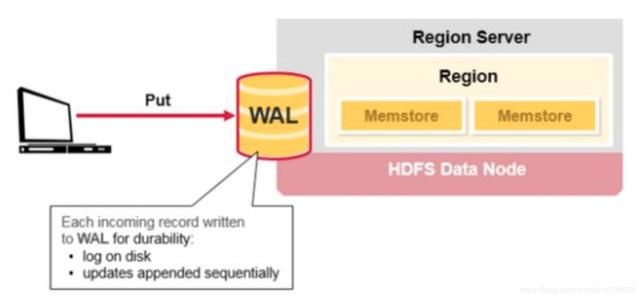
1)写WAL
当客户端提交了一个put 请求,那么在region server上需要首先写WAL(write-ahead-log)。
需要注意三点:
- Hlog是一个region server上一个,并不是一个region一个
- 写入数据是添加在log尾部
- log上的数据主要为了保证没有落盘的数据能在server崩溃后不丢失
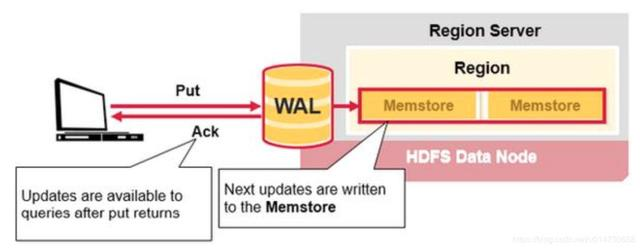
2)写缓存
数据写入WAL成功,才会继续写入MemStore。
然后才会返回ack给客户端,表示写入成功了。
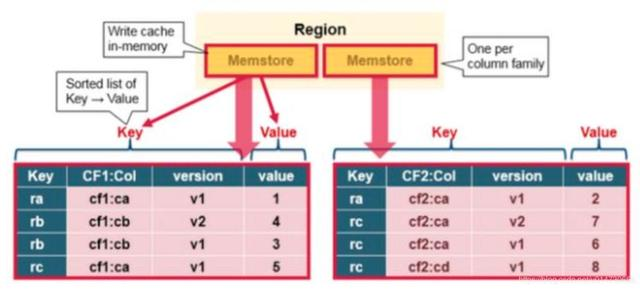
2.2 HBase MemStroe
MemStore主要保存数据更新在内存中,以字典序的KeyValue形式,跟HFile里面保存的一样。
每一个column family会有一个对应的memstore
更新的数据会在memstore中以key-value形式排好序存储,注意看图,按字典序排,同时按version的倒序排列。
我们可以看到,key的组成包括rowkey-cf-col-version。
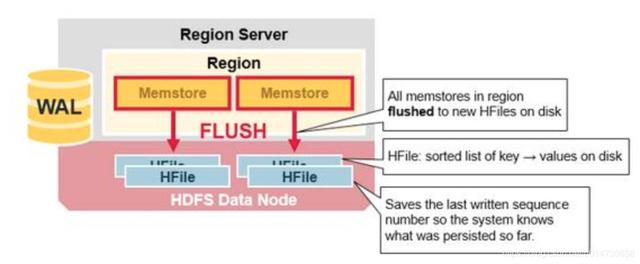
2.3 HBase region flush
当MemStore存储了足够多的数据,整个有序集会被写入一个新的HFile文件中,保存在HDFS。
HBase中每个colum family会有多个HFile,用来存储实际的keyValue。
注意,这里解释了为什么HBase中columfaily的数量是有限制的(具体是多少?)。
每一个cf有一个对应的MemStore,当一个MemStore满了,所属region的所有memstore都会被flush到磁盘。所以MemStore的flush的最小单位是一个region,而不是一个MemStore。
flush的同时,它还会存储一些额外的信息,比如最后一个写的序列号,让系统知道它当前持久化到什么位置了。
最大的序列号作为元数据,会被存储在每个HFile中,表示持久化到哪个位置了,下一次持久化应该从哪里继续。一个region启动时,会读取每个HFile的序列号,然后最大的序列号会被用来作为新的起始序列号。
深入HFile
3.1 HFile的写入
HBase中,数据以有序KV的形式,存储在HFile中。当MemStore存储了足够的数据,全部kv对被写入HFile存入HDFS。
这里写文件的过程是顺序写,避免了硬盘大量移动磁头的过程,比随机写高效很多。
HFile的逻辑结构如图:
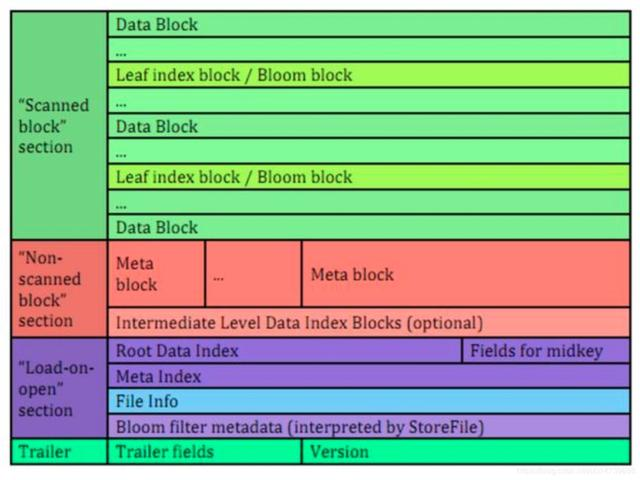
主要分为四个部分:Scanned block section,Non-scanned block section,Opening-time data section和Trailer。
- Scanned block section:表示扫描HFile时,这部分所有数据块都会被读取,包括Leaf Index Block和Bloom Block。
- Non-scanned block section:表示在扫描HFile时不会被读取,主要包括Meta Block和Intermediate Level Data Index Blocks两部分。
- Load-on-open-section:表示在HBase的region server启动时,会被加载到内存中。包括FileInfo、Bloom filter block、data block index和meta block index。
- Trailer:表示HFile的基本信息、各个部分的偏移值和寻址信息。
文件中采用类似b+树都多层索引:
- Kv对按递增顺序存储;
- Root index指向非叶子结点
- 每个数据块的最后一个key被放入中间索引(b+树的非叶子结点)
- 每个数据块有自己的叶子索引(b+树的叶子结点)
- 叶子索引通过row key指向64kb的kv数据块
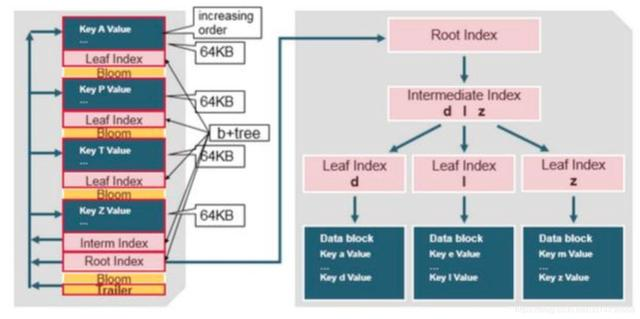
文件的末尾有个trailer节点,指向了meta block。trailer节点还拥有其他信息,比如布隆过滤器和时间范围信息。
布隆过滤器帮助我们过滤那些不包含在这个HFilfe中的rowkey。
时间范围信息用来跳过那些不在这个HFilie时间范围内的row。
因此,当一个HFile被读取后,HFile的索引信息就会被缓存在BlockCache中,这样使得查询只需要一次磁盘查询操作,后续查找只需要读取blockcache内的索引信息即可。
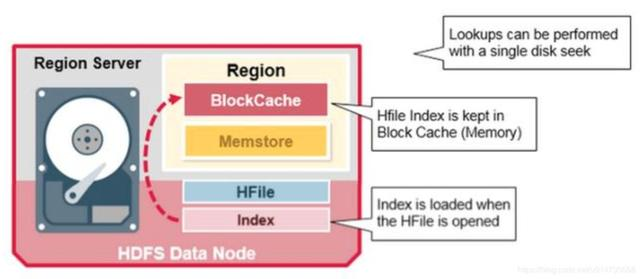
region server上的实体结构关系如下:
regionserver : region = 1 : n,每个region server上有多个region。
region : store= 1 :n,每个region里面有多个store
store : memstore = 1 : 1。
Memstore:Hfile = 1:n。
