

本周工作概述
- 进入
machine_run_board_init对函数行为有一个大概了解 - 深入分析
machine_run_board_init函数中第一步完成NUMA的配置,即numa_complete_configuration部分
machine 模块
void machine_run_board_init(MachineState *machine)
这是主函数中第一个调用的/hw/相关的函数。参数为MachineState类型的结构体,保存了目标虚拟的状态信息。
函数的基本内容形式如下:
void machine_run_board_init(MachineState *machine)
{
MachineClass *machine_class = MACHINE_GET_CLASS(machine);
if (machine_class->numa_mem_supported) {
...
}
if (machine_class->valid_cpu_types && machine->cpu_type) {
...
}
machine_class->init(machine);
}
可以看到,函数首先从machine中获取machine class信息:
MachineClass *machine_class = MACHINE_GET_CLASS(machine);
在QEMU中,MachineClass结构体代表一个虚拟机,对于PC,使用MachineClass的派生类PCMachineClass,定义在/hw/i386/pc.h中。
根据machine的不同,定义不同的PCMachineClass,如q35系列的PCMachineClas通过宏定义的方式定义在hw/i386/pc_q35.c中。函数获取machine_class利用MACHINE_GET_CLASS,也是通过宏定义方式定义了方法,之后再分析此处涉及到的QEMU中关于类的获取、构造方式。
QEMU支持的machine类型可以通过qemu-system -machine help指令查看:
Supported machines are:
pc-i440fx-zesty Ubuntu 17.04 PC (i440FX + PIIX, 1996)
pc-i440fx-yakkety Ubuntu 16.10 PC (i440FX + PIIX, 1996)
pc-i440fx-xenial Ubuntu 16.04 PC (i440FX + PIIX, 1996)
pc-i440fx-wily Ubuntu 15.04 PC (i440FX + PIIX, 1996)
pc-i440fx-trusty Ubuntu 14.04 PC (i440FX + PIIX, 1996)
ubuntu Ubuntu 18.04 PC (i440FX + PIIX, 1996) (alias of pc-i440fx-bionic)
pc-i440fx-bionic Ubuntu 18.04 PC (i440FX + PIIX, 1996) (default)
pc-i440fx-bionic-hpb Ubuntu 18.04 PC (i440FX + PIIX, +host-phys-bits=true, 1996)
pc-i440fx-artful Ubuntu 17.10 PC (i440FX + PIIX, 1996)
pc-i440fx-2.9 Standard PC (i440FX + PIIX, 1996)
pc-i440fx-2.8 Standard PC (i440FX + PIIX, 1996)
pc-i440fx-2.7 Standard PC (i440FX + PIIX, 1996)
pc-i440fx-2.6 Standard PC (i440FX + PIIX, 1996)
pc-i440fx-2.5 Standard PC (i440FX + PIIX, 1996)
pc-i440fx-2.4 Standard PC (i440FX + PIIX, 1996)
pc-i440fx-2.3 Standard PC (i440FX + PIIX, 1996)
pc-i440fx-2.2 Standard PC (i440FX + PIIX, 1996)
pc Standard PC (i440FX + PIIX, 1996) (alias of pc-i440fx-2.11)
pc-i440fx-2.11 Standard PC (i440FX + PIIX, 1996)
pc-i440fx-2.10 Standard PC (i440FX + PIIX, 1996)
pc-i440fx-2.1 Standard PC (i440FX + PIIX, 1996)
pc-i440fx-2.0 Standard PC (i440FX + PIIX, 1996)
pc-i440fx-1.7 Standard PC (i440FX + PIIX, 1996)
pc-i440fx-1.6 Standard PC (i440FX + PIIX, 1996)
pc-i440fx-1.5 Standard PC (i440FX + PIIX, 1996)
pc-i440fx-1.4 Standard PC (i440FX + PIIX, 1996)
pc-1.3 Standard PC (i440FX + PIIX, 1996)
pc-1.2 Standard PC (i440FX + PIIX, 1996)
pc-1.1 Standard PC (i440FX + PIIX, 1996)
pc-1.0 Standard PC (i440FX + PIIX, 1996)
pc-0.15 Standard PC (i440FX + PIIX, 1996)
pc-0.14 Standard PC (i440FX + PIIX, 1996)
pc-0.13 Standard PC (i440FX + PIIX, 1996)
pc-0.12 Standard PC (i440FX + PIIX, 1996)
pc-0.11 Standard PC (i440FX + PIIX, 1996)
pc-0.10 Standard PC (i440FX + PIIX, 1996)
pc-q35-zesty Ubuntu 17.04 PC (Q35 + ICH9, 2009)
pc-q35-yakkety Ubuntu 16.10 PC (Q35 + ICH9, 2009)
pc-q35-xenial Ubuntu 16.04 PC (Q35 + ICH9, 2009)
pc-q35-bionic Ubuntu 18.04 PC (Q35 + ICH9, 2009)
pc-q35-bionic-hpb Ubuntu 18.04 PC (Q35 + ICH9, +host-phys-bits=true, 2009)
pc-q35-artful Ubuntu 17.10 PC (Q35 + ICH9, 2009)
pc-q35-2.9 Standard PC (Q35 + ICH9, 2009)
pc-q35-2.8 Standard PC (Q35 + ICH9, 2009)
pc-q35-2.7 Standard PC (Q35 + ICH9, 2009)
pc-q35-2.6 Standard PC (Q35 + ICH9, 2009)
pc-q35-2.5 Standard PC (Q35 + ICH9, 2009)
pc-q35-2.4 Standard PC (Q35 + ICH9, 2009)
q35 Standard PC (Q35 + ICH9, 2009) (alias of pc-q35-2.11)
pc-q35-2.11 Standard PC (Q35 + ICH9, 2009)
pc-q35-2.10 Standard PC (Q35 + ICH9, 2009)
isapc ISA-only PC
none empty machine
xenfv Xen Fully-virtualized PC
xenpv Xen Para-virtualized PC
可以在QEMU的参数中增加-machine参数来选择machine的类型(参考链接1、
参考链接2),如:
-machine pc-i440fx-2.11
或者
-machine type=q35,accel=kvm
在我的参数中,使用了q35的machine
在确定MachineClass之后,machine_run_board_init做了两次条件检查,当满足特定条件时执行某些动作。最后调用对应目标虚拟机的初始化函数,完成对主板以及CPU基本外设的虚拟化,对于不同类型的主板有不同的初始化函数。
先看第一个条件检查,检查和numa相关的信息:
if (machine_class->numa_mem_supported) {
numa_complete_configuration(machine);
if (machine->numa_state->num_nodes) {
machine_numa_finish_cpu_init(machine);
}
}
回到代码中的判断,machine_class类有一个成员numa_mem_supported:
@numa_mem_supported:
true if '--numa node.mem' option is supported and false otherwise
在我的调试信息中可以看到numa_mem_supported为True:

进而完成numa_complete_configuration
numa模块
为测试NUMA,QEMU的启动配置设置如下:
-m
1024
-smp
cpus=4
-numa
node,cpus=0-1
-numa
node,cpus=2-3
--enable-kvm
-drive
if=virtio,file=test.qcow2,cache=none
-vnc
:1
void numa_complete_configuration(MachineState *ms)
什么是NUMA
这要先看一下numa的概念。
Non-Uniform Memory Access (NUMA) refers to multiprocessor systems whose memory is divided into multiple memory nodes. The access time of a memory node depends on the relative locations of the accessing CPU and the accessed node. (This contrasts with a symmetric multiprocessor system, where the access time for all of the memory is the same for all CPUs.) Normally, each CPU on a NUMA system has a local memory node whose contents can be accessed faster than the memory in the node local to another CPU or the memory on a bus shared by all CPUs.
简言之,这是一种内存架构,对于计算机的每个CPU,有一个local memory node,对于自身的local memory node的访存速度要快于non-local memory node。
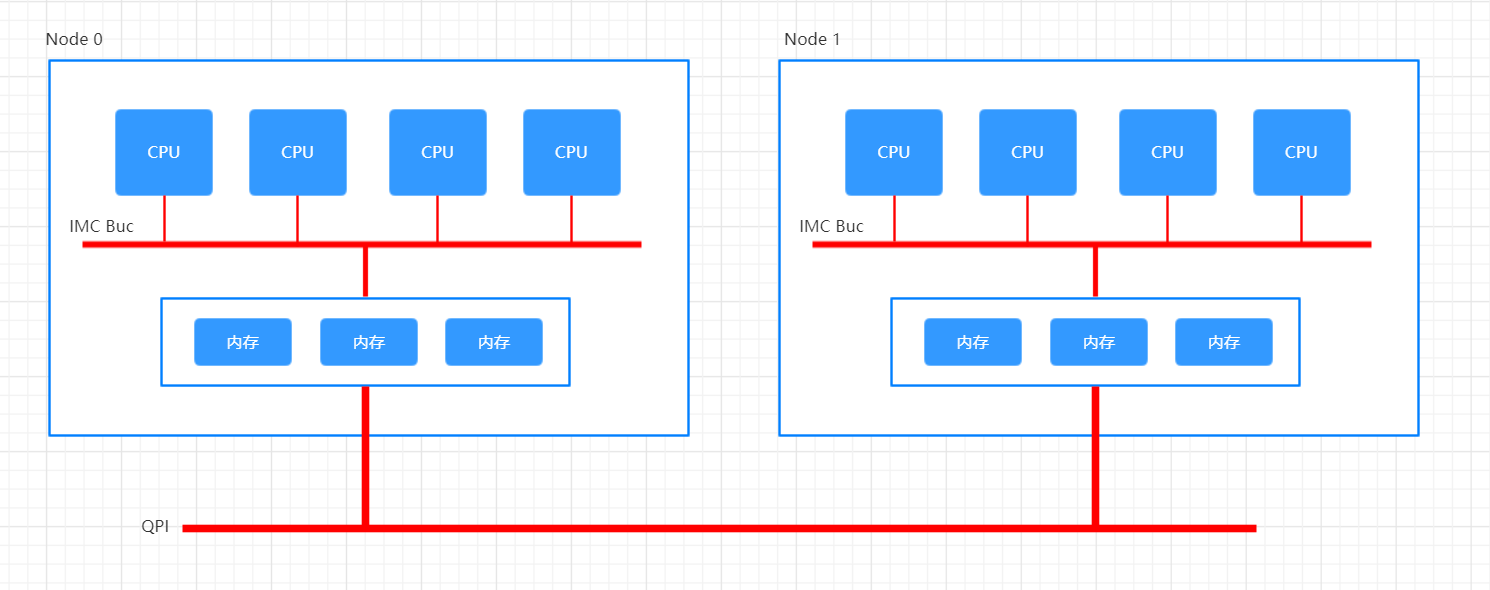
remote memory的速度远低于节点通过IMC Bus访问自的local memory。故设置“距离”的概念,称为numa distance,距离越大,则node对于memory的访问速度越慢。
我们可以看一下本机NUMA架构信息:
ethan@Ethan-Laptop:~$ numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1 2 3
node 0 size: 7856 MB
node 0 free: 288 MB
node distances:
node 0
0: 10
然后发现我的电脑并没有配置多个NUMA节点……
函数主体
下面分析NUMA模块中的函数。在machine_run_board_init中,若支持NUMA,则进入NUMA配置,函数如下:
/*qemu-4.2.0/hw/core/numa.c*/
void numa_complete_configuration(MachineState *ms)
{
int i;
MachineClass *mc = MACHINE_GET_CLASS(ms);
NodeInfo *numa_info = ms->numa_state->nodes;
if (ms->numa_state->num_nodes == 0 &&
((ms->ram_slots > 0 &&
mc->auto_enable_numa_with_memhp) ||
mc->auto_enable_numa)) {
NumaNodeOptions node = { };
parse_numa_node(ms, &node, &error_abort);
numa_info[0].node_mem = ram_size;
}
assert(max_numa_nodeid <= MAX_NODES);
for (i = max_numa_nodeid - 1; i >= 0; i--) {
if (!numa_info[i].present) {
error_report("numa: Node ID missing: %d", i);
exit(1);
}
}
assert(ms->numa_state->num_nodes == max_numa_nodeid);
if (ms->numa_state->num_nodes > 0) {
uint64_t numa_total;
if (ms->numa_state->num_nodes > MAX_NODES) {
ms->numa_state->num_nodes = MAX_NODES;
}
for (i = 0; i < ms->numa_state->num_nodes; i++) {
if (numa_info[i].node_mem != 0) {
break;
}
}
if (i == ms->numa_state->num_nodes) {
assert(mc->numa_auto_assign_ram);
mc->numa_auto_assign_ram(mc, numa_info,
ms->numa_state->num_nodes, ram_size);
if (!qtest_enabled()) {
warn_report("Default splitting of RAM between nodes is deprecated,"
" Use '-numa node,memdev' to explictly define RAM"
" allocation per node");
}
}
numa_total = 0;
for (i = 0; i < ms->numa_state->num_nodes; i++) {
numa_total += numa_info[i].node_mem;
}
if (numa_total != ram_size) {
error_report("total memory for NUMA nodes (0x%" PRIx64 ")"
" should equal RAM size (0x" RAM_ADDR_FMT ")",
numa_total, ram_size);
exit(1);
}
if (ms->numa_state->have_numa_distance) {
validate_numa_distance(ms);
complete_init_numa_distance(ms);
}
}
}
获得NUMA信息
接收参数为一个MachineState结构体ms,前面说过,该结构体保存了目标虚拟机的状态信息。
之后获得MachineClass,由mc指针指向。之后获取ms->numa_state,我们看一下numa_state的结构体定义:
/*qemu-4.2.0/include/sysemu/numa.h*/
struct NumaState {
/* Number of NUMA nodes */
int num_nodes;
/* Allow setting NUMA distance for different NUMA nodes */
bool have_numa_distance;
/* NUMA nodes information */
NodeInfo nodes[MAX_NODES];
};
num_nodes:NUMA节点个数
have_numa_distance:是否为多个节点之间的内存访问设置numa distance
nodes[]:存储每个节点的信息,NodeInfo结构如下:
struct NodeInfo {
uint64_t node_mem;
struct HostMemoryBackend *node_memdev;
bool present;
uint8_t distance[MAX_NODES];
};
保存了节点的内存大小,在主机上内存映射关系,该节点是否启用,以及该节点其它各个节点之间的距离。
默认节点配置
回到numa_complete_configuration函数中,numa_info指向了目标虚拟机中保存节点信息的数组。
之后判断,当目标机器没有设置numa node并且开启了auto enable numa的时候,进行对numa的配置。这里的“开启了auto enable numa”包括两种情况:
- 支持热插拔并且设置了在热插拔情况下
auto enable numa with memory hotplug - 设置了
auto enable numa
其中,对于是否支持热插拔,判断标准是ms->ram_slots > 0,slot的含义是DIMM上插槽的数量。
DIMM全称Dual-Inline-Memory-Modules,中文名叫双列直插式存储模块,是指奔腾CPU推出后出现的新型内存条,它提供了64位的数据通道。
这部分代码如下:
if (ms->numa_state->num_nodes == 0 &&
((ms->ram_slots > 0 &&
mc->auto_enable_numa_with_memhp) ||
mc->auto_enable_numa)) {
NumaNodeOptions node = { };
parse_numa_node(ms, &node, &error_abort);
numa_info[0].node_mem = ram_size;
}
其中,ram_size在qemu-4.2.0/tests/fw_cfg-test.c中定义:
static uint64_t ram_size = 128 << 20;
默认情况下是bit, 在我的调试信息中设置的是1024MiB,即
bit。
鲁棒性检查
之后判断numa node数量是否大于最大支持的节点数量,若是,停止程序运行。
assert(max_numa_nodeid <= MAX_NODES);
这里注意一下assert函数的用法,是C提供的标准库函数,用于判断传递的条件是否成立,若不成立则直接终止程序运行。
QEMU暂时不支持sparse NUMA node id,即对于N个node来说,其node id需要从1到N,表现在numa_info数组中下标为0到N-1,QEMU不支持除此之外的情况(稀疏节点ID)。故要对此进行判断,若是sparse NUMA node id,需要报错。如下:
/* No support for sparse NUMA node IDs yet: */
for (i = max_numa_nodeid - 1; i >= 0; i--) {
/* Report large node IDs first, to make mistakes easier to spot */
if (!numa_info[i].present) {
error_report("numa: Node ID missing: %d", i);
exit(1);
}
}
这里或许是我们可以对QEMU开源社区做贡献的点。
确保所有节点都已激活(状态为present):
/* This must be always true if all nodes are present: */
assert(ms->numa_state->num_nodes == max_numa_nodeid);
可以发现,QEMU的鲁棒性非常好。
完成节点属性配置
接下来是对于numa node数量大于0的情况做处理。
其中,以下的判断或可以省略:
if (ms->numa_state->num_nodes > MAX_NODES) {
ms->numa_state->num_nodes = MAX_NODES;
}
因为在前面为保证鲁棒性,已经确保了:
- max_numa_nodeid <= MAX_NODES
- ms->numa_state->num_nodes == max_numa_nodeid
可以得到:ms->numa_state->num_nodes == max_numa_nodeid <= MAX_NODES
这与判断条件中的ms->numa_state->num_nodes > MAX_NODES相矛盾,即此分支条件永远不会成立。我认为此处代码存在冗余,并且分支中的做法将num_nodes设为max_numa_nodeid也没有道理。
内存分配
下面对每个numa node进行内存的分配:
for (i = 0; i < ms->numa_state->num_nodes; i++) {
if (numa_info[i].node_mem != 0) {
break;
}
}
if (i == ms->numa_state->num_nodes) {
assert(mc->numa_auto_assign_ram);
mc->numa_auto_assign_ram(mc, numa_info,
ms->numa_state->num_nodes, ram_size);
if (!qtest_enabled()) {
warn_report("Default splitting of RAM between nodes is deprecated,"
" Use '-numa node,memdev' to explictly define RAM"
" allocation per node");
}
}
可以看到,如果用户的参数中对于所有的节点都没有制定内存分配的大小,则使用默认的均分策略。
在我的调试参数中,没有指定节点内存分配策略,故会进入这种情况并给出warning:

启动QEMU时给的总内存是1024MiB,即bit,并且分了两个节点,按照上面的策略分配之后,每个节点应该有
bit,转换为十进制即
536870912,观察调试信息,与推测相同:

之后通过配置好的各个节点的memory大小计算出总NUMA 内大小,和用户设置的ram_size比较,若不一致,则报错。
numa_total = 0;
for (i = 0; i < ms->numa_state->num_nodes; i++) {
numa_total += numa_info[i].node_mem;
}
if (numa_total != ram_size) {
error_report("total memory for NUMA nodes (0x%" PRIx64 ")"
" should equal RAM size (0x" RAM_ADDR_FMT ")",
numa_total, ram_size);
exit(1);
}
配置NUMA distance table
最后,当启用了NUMA distance这一特性时,需要配置其distance table。QEMU使用的规则如下:
- 节点访问自身的
distance恒为10,故用户可不提供节点到自身的距离值 - 在默认情况下,
distance table是一个symmetric matrix,即A->B == B->A,此时,对于一对节点来说,用户只需要提供一个值即可 - 若用户同时提供了一对节点相互访问内存的距离,且两距离不等,则QEMU认为
distance table是非对称的,此时用户需要提供完整的distance table
代码如下:
if (ms->numa_state->have_numa_distance) {
/* Validate enough NUMA distance information was provided. */
validate_numa_distance(ms);
/* Validation succeeded, now fill in any missing distances. */
complete_init_numa_distance(ms);
}
即当目标虚拟机需要设置numa distance时(默认为否),先验证用户是否提供了足够的初始化信息,若是,则完成对distance table的配置。
最后,将numa_complete_configuration函数总结如下:
-
获得目标机器的NUMA配置信息
-
判断目标虚拟机是否设置了
auto enable numa,若是,进行预设配置节点参数 -
保证鲁棒性(节点数量、非稀疏节点ID、节点激活状态判断)
-
对
numa node> 0 的情况进行配置- 若用户没有指定分配策略,使用默认分配策略进行节点的内存分配
- 内存配置正确性检验
- 配置节点间的
distance table
总结
- 本周分析了
machine模块的第一部分,完成对于NUMA的配置,下周将继续分析如何通过节点信息完成numa cpu初始化 - 通过对于NUMA配置的分析我们可以看到,一个成熟的项目需要有很强的鲁棒性,需要随时做边界检查,防止出现未知错误
- 在分析的过程中我们看到,QEMU有一些尚未支持的特性,这为我们参与到开源社区中提供了思路
- 下周将继续深入分析
machine_run_board_init函数的行为
