语法格式:row_number() over(partition by 分组列 order by 排序列 desc);
在使用 row_number() over()函数时候,over()里头的分组以及排序的执行晚于 where 、group by、 order by 的执行。
创建数据表:
create table TEST_ROW_NUMBER_OVER(
id varchar(10) not null,
name varchar(10) null,
age varchar(10) null,
salary int null
);
select * from TEST_ROW_NUMBER_OVER t;
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(1,'a',10,8000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(1,'a2',11,6500);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(2,'b',12,13000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(2,'b2',13,4500);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(3,'c',14,3000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(3,'c2',15,20000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(4,'d',16,30000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(5,'d2',17,1800);
对查询结果进行排序
select id,name,age,salary,row_number()over(order by salary DESC) rn
from `TEST_ROW_NUMBER_OVER`
Lag和Lead分析函数可以在同一次查询中取出同一字段的前N行的数据(Lag)和后N行的数据(Lead)作为独立的列
在实际应用当中,若要用到取今天和昨天的某字段差值时,Lag和Lead函数的应用就显得尤为重要。当然,这种操作可以用表的自连接实现,但是LAG和LEAD与left join、rightjoin等自连接相比,效率更高,SQL更简洁。下面我就对这两个函数做一个简单的介绍。
函数语法如下:
lag(exp_str,offset,defval) over(partion by …order by …)
lead(exp_str,offset,defval) over(partion by …order by …)
参数说明:
exp_str是字段名
Offset是偏移量,即是上1个或上N个的值,假设当前行在表中排在第10行,则offset 为3,则表示我们所要找的数据行就是表中的第7行(即10-3=7)。
Defval默认值,当两个函数取上N/下N个值,当在表中从当前行位置向前数N行已经超出了表的范围时,lag()函数将defval这个参数值作为函数的返回值,若没有指定默认值,则返回NULL,那么在数学运算中,总要给一个默认值才不会出错
对salary列:取上一个salary列作为单独的列,若不指定默认值,则默认值为NULL
select id,name,age,salary,rank()over(order by salary DESC) rn
from `TEST_ROW_NUMBER_OVER`
对salary列:取上一个salary列作为单独的列,指定默认值为0
select id,name,age,salary,lag(salary,1,0)over(order by salary DESC) rn
from `TEST_ROW_NUMBER_OVER`
3. 对salary列:取下一个salaryL列作为单独的列,指定默认值为0
select id,name,age,salary,lead(salary,1,0)over(order by salary DESC) rn
from `TEST_ROW_NUMBER_OVER`
运算:薪水跟上次相比涨了多少
select id,name,age,salary,p,salary-p as addsalary from
(select id,name,age,salary,lag(salary,1,0)over(order by salary DESC) p
from `TEST_ROW_NUMBER_OVER`) tt
FIRST_VALUE()、LAST_VALUE()
select id,name,age,salary,
first_value(salary)over(partition by id order by salary DESC) first_salary,
last_value(salary)over(partition by id order by salary DESC) last_salary
from `TEST_ROW_NUMBER_OVER`
first_value()的结果容易理解,直接在结果的所有行记录中输出同一个满足条件的首个记录;
last_value()默认统计范围是 rows between unbounded preceding and current row,也就是取当前行数据与当前行之前的数据的比较
那么如果我们直接在每行数据中显示最后的那个数据,需在order by 条件的后面加上语句:rows between unbounded preceding and unbounded following , 也就是前面无界和后面无界之间的行比较
select id,name,age,salary,
first_value(salary)over(partition by id order by salary DESC) first_salary,
last_value(salary)over(partition by id order by salary DESC rows between unbounded preceding and unbounded following) last_salary
from `TEST_ROW_NUMBER_OVER`
NTH_VALUE()
select id,name,age,salary,
nth_value(salary,3)over(order by id ASC) nth
from `TEST_ROW_NUMBER_OVER`
其中NTH_VALUE()中的第二个参数是指这个函数取排名第几的记录
NTILE()
SELECT id, name,age,salary, CASE NTILE (3) OVER (ORDER BY salary DESC) WHEN 1 THEN '高' WHEN 2 THEN '中' WHEN 3 THEN '低' END AS '级别'
FROM TEST_ROW_NUMBER_OVER ORDER BY salary;
语法:
WITH cte_name (column_list) AS (
query
)
SELECT * FROM cte_name
生成一个cte_name的派生表,然后再操作派生表
🌰
WITH age_list AS(
select id,age,salary from `TEST_ROW_NUMBER_OVER` where salary > 10000
)
select * from age_list
🌰🌰
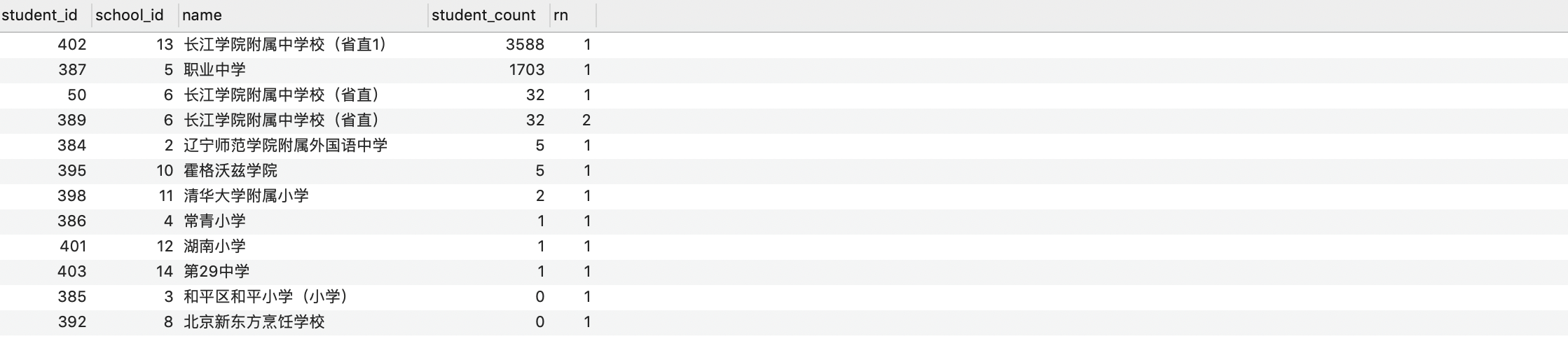
新建一个学生表 和 学校表 进行关联
WITH student AS(
select id,username,school_id
from st_students
where username like '%浩南%'
),
school AS(
select student.id student_id,op_schools.id as school_id,`name`,address,student_count
from `op_schools`
right join student on school_id = op_schools.id
)
select student_id,school_id,`name`,student_count,row_number()over(partition by school_id order by student_count DESC) rn
from school
order by student_count DESC
CREATE TABLE emp(
id INT PRIMARY KEY NOT NULL,
name VARCHAR(100) NOT NULL,
manager_id INT NULL,
INDEX (manager_id)
)
----------------------------------------------
INSERT INTO emp VALUES
(333, "总经理", NULL),
(198, "副总1", 333),
(692, "副总2", 333),
(29, "主任1", 198),
(4610, "职员1", 29),
(72, "职员2", 29),
(123, "主任2", 692);
----------------------------------------------
WITH RECURSIVE test(id, name, path)
AS
(
SELECT id, name, CAST(id AS CHAR(200))
FROM emp WHERE manager_id IS NULL
UNION ALL
SELECT e.id, e.name, CONCAT(ep.path, ',', e.id)
FROM test AS ep JOIN emp AS e ON ep.id = e.manager_id
)SELECT * FROM test ORDER BY path;