

一.章节目录
1.数据结构核心名词解析
2.逻辑结构与物理结构区别
3.算法设计要求
4.算法效率衡量方法
5.算法时间复杂度
6.常见的时间复杂度
7.算法控件复杂度计算
8.线性表-关于顺序存储的实现(增删查改)
9线性表-关于链式(单链表)存储的设计(增删查改与头插法/尾插法)
1.数据结构核心名词解析
1.1 数据结构起源 早期人们都把计算机理解为数值计算工具,感觉计算机就是为了解决复杂计算问题.所以计算机解决问题,应该是先从具体问题中抽象出一个适当的数据模型,设计出一个解决此数据模型的算法,然后才开始编写程序,从而实现一个解决问题的软件. 但是,现实开发中,我们不单纯的只是解决数值计算问题,而是需要更加一些高效的手段来解决问题.例如需要更合适的数据结构,树,表,图等数据结构来更好的处理问题. 数据结构是一门研究非数值计算的程序设计问题中操作对象. 数据结构是一门独立的学科, 也可以看出它在计算机专业的地位. 它不是算法的附属品. 好的程序设计 = 数据结构 + 算法. 数据结构和算法是不可分割的. 在你前往高级开发者的路上,数据结构和算法一定是必须啃下来的硬骨头.
1.2 基本概念与术语 在谈数据结构之前,我们先来谈谈数据. 正所谓"巧妇难为无米之炊",再强大的计算机,如果没有数据. 也是毫无作用. 数据结构中最基本的5个概念: 数据,数据元素,数据项,数据对象,数据结构;
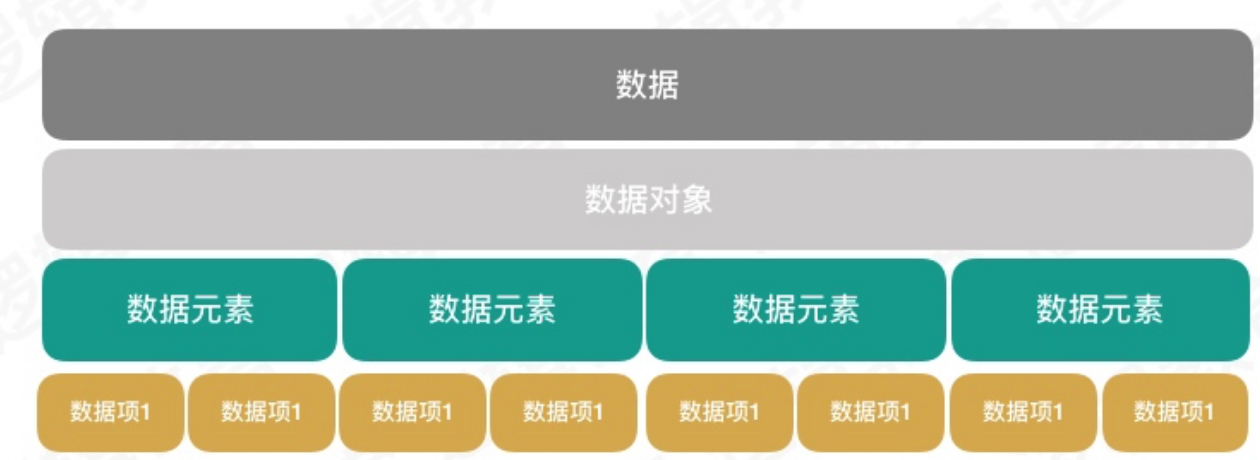
1.2.1 数据 数据: “是描述客观事物的符号,是计算机中可以操作的对象,是能被计算机识别,并输入给计算机处理的符号集合。数据不仅仅包括整型、实型等数值类型,还包括字符及声音、图像、视频等非数值类型。” 例如,Mp3就是声音数据,图片就是图像数据. 而这些数据,其实只不过是"符号". 这些符号有2个前提:
可以输入到计算机中 能被计算机程序处理.
对于从后端返回的整型,浮点型数据,可以直接进行数值计算. 对于字符串类型的数据,我们就需要进行非数值的处理. 而对于声音,图像,视频这样的数据,我们需要通过编码的手段将其变成二进制数据进行处理.
1.2.2 数据元素 数据元素: 是组成数据的,且有一定意义的基本单位,在计算机中通常作为整体处理. 也被称作"记录" 例如,我们生活的圈子里.什么叫数据元素了? 人Person ,汽车Car 等.
1.2.3 数据项 数据项: 一个数据元素可以由若干数据项组成. 比如,Person 数据元素,可以为分解为眼睛,耳朵,鼻子,嘴巴,手臂这些基本的数据项,也可以从另外的角度拆解成姓名,年龄,性别,出生地址,出生日期,联系电话等数据项. 那么你如何拆解数据项, 要看你的项目来定. 数据项是数据不可分割的最小单位. 在我们的课程中,我们把数据定位为最小单位.这样有助于我们更好理解以及解决问题.
1.2.4 数据对象 数据对象: 是性质相同的数据元素的集合,是数据的子集. 那么什么叫性质相同? 是指数据元素具有相同数量和类型的数项. 类似数组中的元素保持性质一致.
1.2.5 数据结构 结构,简单理解就是关系. 比如分子结构,就是说组成分子原子的排列方式. 不同数据元素之间不是独立的,而是存在特定的关系.我们将这些关系成为结构. 那么数据结构是什么? 数据结构是相互之间存在一种或多种特定关系的数据元素的集合.
代码理解
//
// main.c
// 001--数据结构基本术语
//
// Created by CC老师 on 2019/8/12.
// Copyright © 2019年 CC老师. All rights reserved.
//
/*
数据: 程序的操作对象,用于描述客观事物.
数据的特点: 1️⃣ 可以输入到计算机 2️⃣ 可以被计算机处理
数据项: 一个数据元素由若干数据项组成
数据元素: 组成数据的对象的基本单位
数据对象: 性质相同的数据元素的集合(类似于数组)
结构: 数据元素之间不是独立的,存在特定的关系.这些关系即是结构;
数据结构:指的数据对象中的数据元素之间的关系
*/
#include <stdio.h>
//声明一个结构体类型
struct Teacher{ //一种数据结构
char *name; //数据项--名字
char *title; //数据项--职称
int age; //数据项--年龄
};
int main(int argc, const char * argv[]) {
struct Teacher t1; //数据元素;
struct Teacher tArray; //数据对象;
t1.age = 18; //数据项
t1.name = "CC"; //数据项
t1.title = "讲师"; //数据项
printf("老师姓名:%s\n",t1.name);
printf("老师年龄:%d\n",t1.age);
printf("老师职称:%s\n",t1.title);
return 0;
}
1.3 抽象数据类型 1.3.1 数据类型 数据类型: 是指一组性质相同值的集合以及定义在此集合的一些操作的总称. 在C语言中,按照取值不同,数据类型可以分为2类:
原子类型: 是不可以在分解的基本数据类型,包含整型,浮点型,字符型等; 结构类型: 由若干类型组合而成,是可以再分解的.例如,整型数组就是由若干整型数据组成的.
1.3.2 抽象数据类型 抽象,是抽取出事物具有的普遍性的本质. 它是抽出问题的特征而忽略非本质的细节,是对具体事物的一个概括. 抽象是一种思考问题的方式,它隐藏繁杂的细节,只保留实现目标所必需的信息. 抽象数据类型: 是指一个数学模型以及定义在该模型上的一组操作; 例如,我们在编写计算机绘图软件系统时,经常会使用到坐标. 也就是说,会经常使用x,y来描述横纵坐标. 而在3D系统中,Z深度就会出现. 既然这3个整型数字是始终出现在一起. 那就可以定义成一个Point的抽象数据类型. 它有x,y,z三个整型变量. 这样开发者就非常方便操作Point 数据变量. 抽象数据类型可以理解成实际开发里经常使用的结构体和类; 根据业务需求定义合适的数据类型以及动作.
2.逻辑结构与物理结构
2.1 根据视角不同,我们将数据结构分为2种: 逻辑结构与物理结构;
2.1.1 逻辑结构
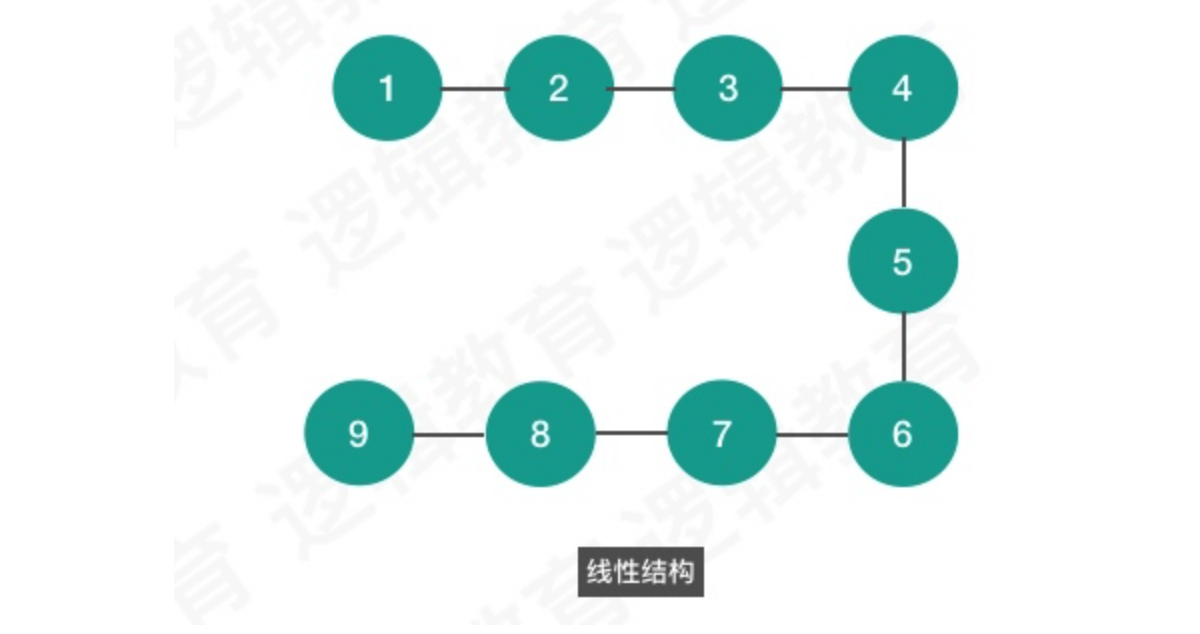
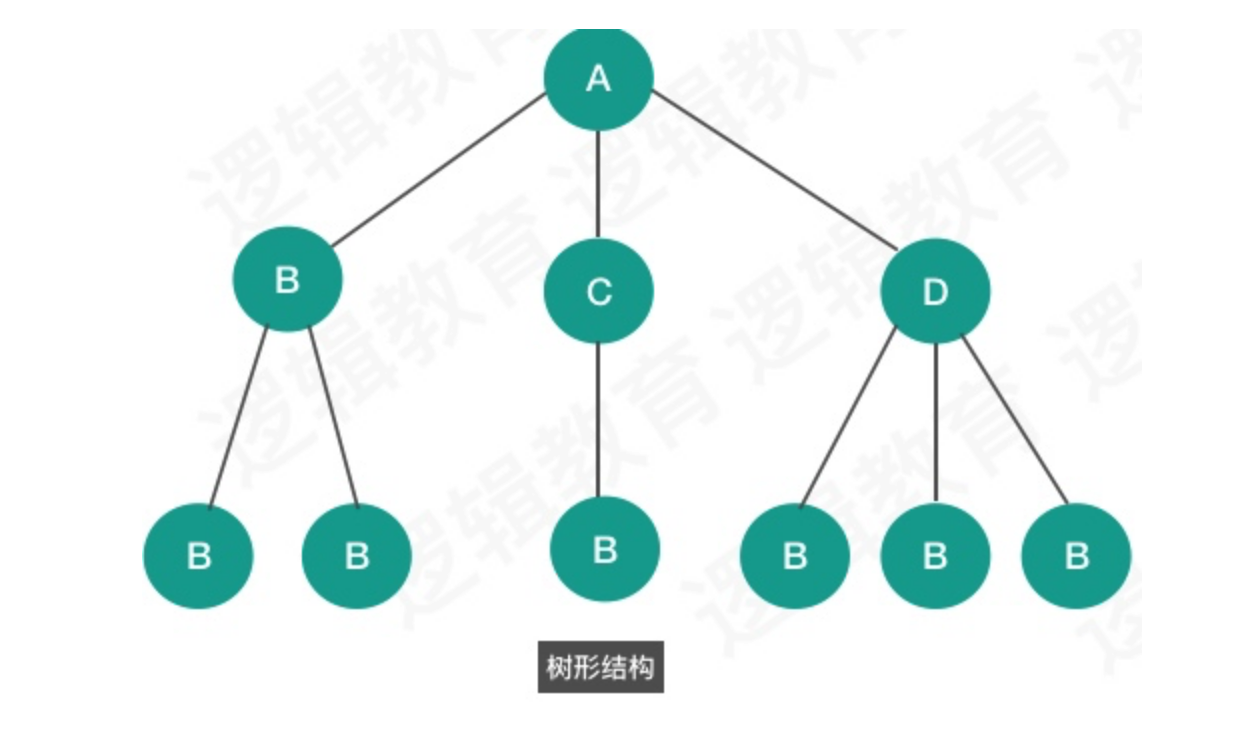
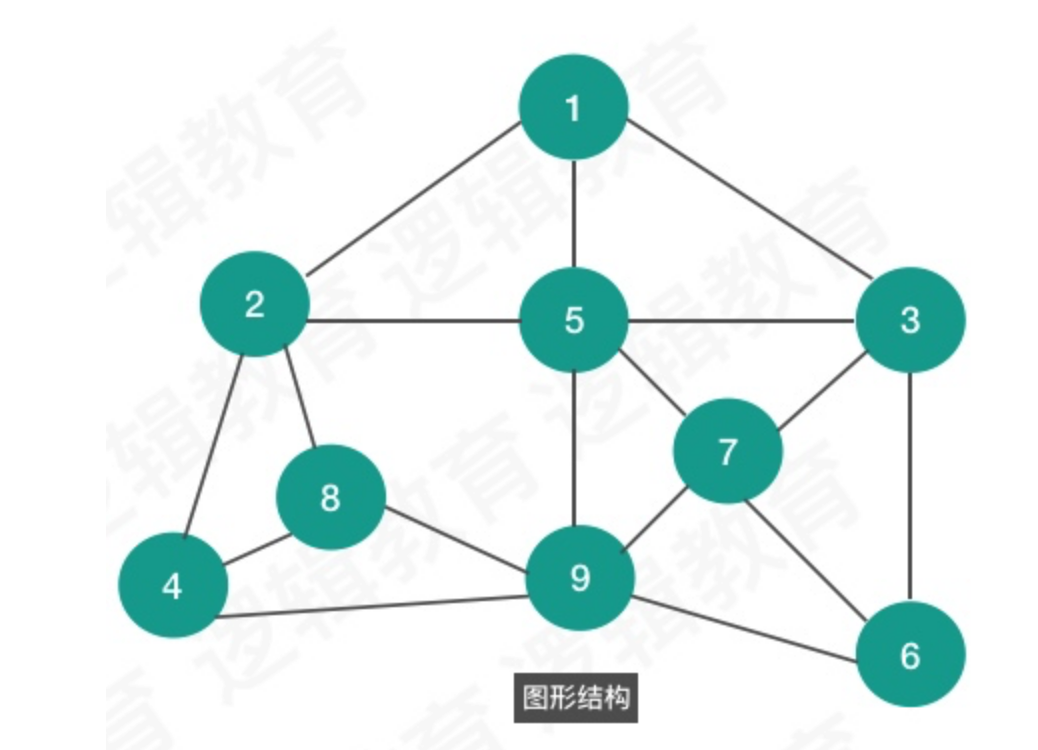
指的是数据对象中的数据元素之间的相互关系. 逻辑结构分为四种: 集合结构,线性结构,树形结构,图形结构. 具体采用什么的数据结构,是需要根据实际业务需求来进行合理的设计.
2.1.2 逻辑结构图形表示
- 线性结构

- 线性结构
- 树型结构
*图形结构
2.2.2 物理结构
物理结构,别称"存储结构". 顾名思义,指的是数据的逻辑结构在计算机的存储形式. 设计好逻辑数据结构之后,数据的存储也是非常重要的. 数据存储结构应该正确反映数据元素之间的逻辑关系.这才是关键! 如何存储数据元素之间的逻辑关系,是实现物理结构的重点和难点. 数据元素的存储结构形式有2种: 顺序存储和链式存储;
- 顺序存储结构
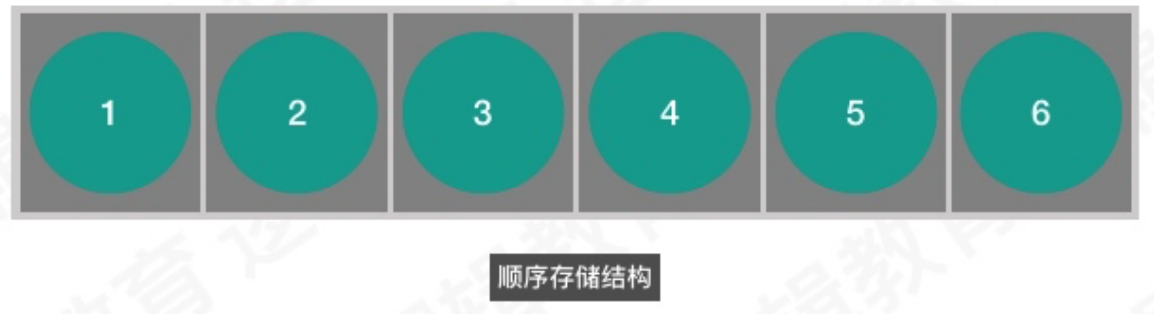
解读: 这样的存储方式,实际非常简单. 可以理解为排队占位. 按照顺序,每个一段空间. 我们所学习且使用的数组就是典型顺序存储结构. 当你在计算机建立一个有6个整型数据的数组时,计算机便在内存中找到一片空地.按照一个整型所占空间大小乘以6.开辟一段连续的内存空间. 然后将数据依顺序放在位置上,依次排放.
问题1;了解到顺序存储结构,如果一切数据都有规律且简单使用顺序存储结构当然是最合适不过的. 但是实际上,总是有复杂的情况发生. 对于经常且时差发生变化的数据结构,使用顺序存储就会非常不科学. 那该如何解决了?
- 链式存储结构
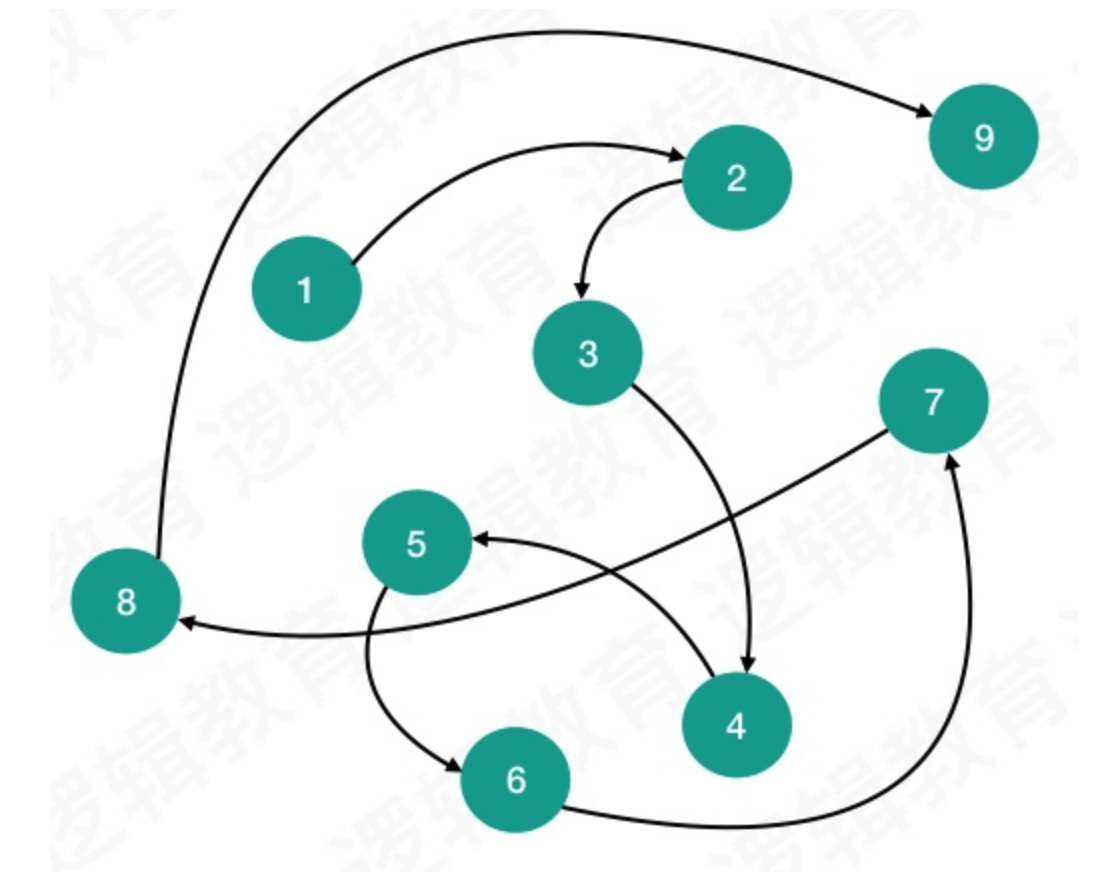
链式存储结构: 是把数据元素放在任意的存储单元里,这组存储单元可以是连续的,也可以是不连续的. 数据元素的存储关系并不能反映逻辑关系,因此需要用一个指针存放数据元素的地址,这样通过地址就可以找到相关关联数据元素的位置.
解决:显然,链式存储就灵活多了. 数据存储在哪里不重要的,只要有一个指针存放了相应的地址就能找到它了.
总结 逻辑结构是面向问题的,而物理结构就是面向计算机的. 其基本的目标就是将数据以及逻辑关系存储到计算机的内存中.
3.算法设计要求
算法: 是解决特定问题求解步骤的描述,在计算机中表现为指令的有限序列,并且每条指令表示一个或多个操作.
3.1 算法与数据结构的关系
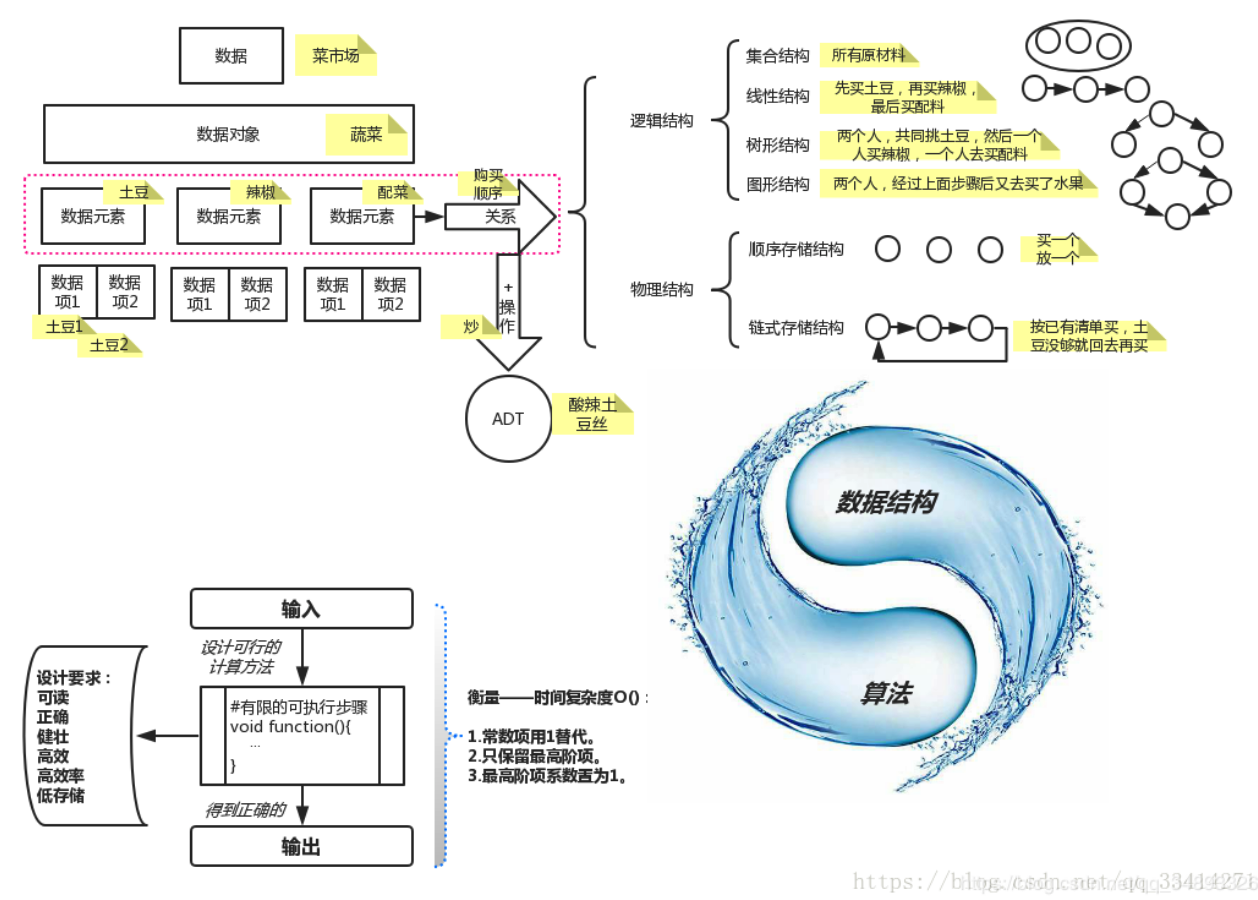
什么是算法: 解决特定问题的求解步骤的描述; 而数据结构如果脱离算法,或者算法脱离数据结构都是无法进行的. 所以在大学课程里,即便单独算法课程里也涵盖了数据结构的内容.
程序设计 = 数据结构 + 算法
3.2 两种算法比较
大家在大学期间,学习C语言; 大多数遇到的第一个算法问题便是: 求解从1-N相加的结果; 而最简单的办法则是使用C语言模拟从1累积到N这个过程,从而得到结果;

这就是算法

对比以上2种方式,如果不仅仅是累积到100,而是一千. 第一种方式,显然需要计算机循环1千次来模拟数学计算,而第二种方式肯定要比第一种来的快.
到底如何评价一个算法优劣了? 接下来我们花时间来探讨.
3.3 算法定义
什么是算法? 算法就是描述解决问题的方法; 通过刚刚的例子,我们可以知道对于一个给定的问题,是可以有多种算法来解决; 那我想问问,有没有通用算法? 换过头来,有没有包治百病的药? 现实开发中会有成千上万的问题,算法也是千变万化,没有通用的算法可以解决所有问题. 甚至解决一个小问题,很优秀的算法却不一定非常适合它; 每个人对问题的解决方案是不一样的,但是我们可以根据一些参考来评估算法的优劣;
3.4 算法的特性
算法必须具备几个基本特性: 输入,输出,有穷性,确定性和可行性;
- 输入输出
输入输出,很好理解. 在解决问题时必须有已知条件,当然有些算法可能没有输入. 但是算法至少有一个或多个输出.否则没有输出,没有结果.你用这个算法干吗?
- 有穷性
有穷性: 指的是算法在执行有限的步骤之后,自动结束而不会出现无限循环,且每一个步骤在可接受的时间内完成.
- 确定性
确定性: 算法的每一个步骤都具有确定的含义,不能出现二义性; 算法在一定条件下,只有一条执行路径,相同的输入只能有唯一的输出结果.
- 可行性
可行性: 算法的每一步都必须是可行的,换句话说,每一步都能通过执行有限次数完成.
3.5 算法设计要求
- 正确性
算法的正确性是指算法至少应该具有输入,输出和加工处理无歧义性,能正确反映问题的需求,能够得到问题的正确答案; 正确分为4个层次: (1).算法程序没有语法错误; (2).算法程序对于合法的输入数据能够产生满足要求的输出结果; (3).算法程序对于非法的输入数据能够得出满足规格说明的结果;(4).算法程序对于精心选择的,甚至刁钻的测试数据都有满足要求的输出结果;
- 可读性
可读性: 算法设计的另一个目的是为了便于阅读,理解和交流; 可读性高有助于人们理解算法,晦涩难懂的算法往往隐含错误,且不容易发现并且难于调试和修改; 注意, 不要犯初学者的错误; 认为代码越少,就越牛逼! 如果有这样的想法, 在团队协作的今天.不再是个人英雄主义的时代! 可读性是算法好坏的很重要的标志!
- 健壮性
一个好的算法还应该能对输入数据的不合法的情况做出合适的处理.考虑边界性,也是在写代码经常要做的一个处理; 比如,输入时间或者距离不应该是负数; 健壮性: 当输入数据不合法时,算法也能做出相关处理,而不是产生异常和莫名其妙的结果;
- 时间效率高和存储量低
生活中,人们希望花最少的钱,用最短的时间,办最大的事. 算法也是一样的思想. 用最少的存储空间,花最少的时间,办成同样的事.就是好算法!
4.算法效率的度量方法
使用高级程序语言编写的程序在计算机上运行时所消耗的时间取决于下列的因素:
- 算法采用的策略,方法;
- 编译产生的代码质量;
- 问题的输入规模;
- 机器执行指令的速度.
第一条,肯定是算法好坏的根本; 但是第2条以及第4条.都是要看编译器的支持以及硬件性能. 也就是说,抛开这些与计算机硬件,软件有关的因素,一个程序运行时间,依赖于算法的好坏和问题的输入规模. 所谓问题输入规模是指输入量的多少. 一个算法在执行过程中所消耗的时间取决于以下的因素:
- 算法所需数据输入时间
- 算法编译为可执行程序的时间
- 计算机执行每条指令所需的时间
- 算法语句中重复执行的次数
1)依赖于输入设备的性能,若是脱机输入,则输入数据的时间可以忽略不计。(2)(3)取决于计算机本身执行的速度和编译程序的性能 习惯上将算法语句重复执行的次数作为算法的时间量度
- 习惯上将算法语句重复执行的次数作为算法的时间量度
//x=x+1; 执行1次
void add(int x){
x = x+1;
}
//x=x+1; 执行n次
void add2(int x,int n){
for (int i = 0; i < n; i++) {
x = x+1;
}
}
//x=x+1; 执行n*n次
void add3(int x,int n){
for (int i = 0; i< n; i++) {
for (int j = 0; j < n ; j++) {
x=x+1;
}
}
}
我们在分析一个算法的运行时,重要的是把基本操作的数量与输入规模关联起来,即是基本操作的数量必须表示成输入规模的函数;
随着n值的越来越大,算法在时间效率上的差异会越来越大;
5.算法时间复杂度
5.1 算法时间复杂度定义
在进行算法分析时,语句的总执行次数T(n)是关于问题规模n的函数. 进而分析T(n)随着n变化情况并确定T(n)的数量级. 算法的时间复杂度,也就是算法的时间量度. T(n) = O(f(n)). “它表示随问题规模n的增大,算法执行时间的增长率和f(n)的增长率相同,称作算法的渐近时间复杂度,简称为时间复杂度。其中f(n)是问题规模n的某个函数。” 大写O( )来体现算法时间复杂度的记法,我们称之为大O记法。 刚刚的3个求和算法时间复杂度分别为O(1),O(n),O(n^2);
5.2 推导大O阶方法
- 用常数1取代运行时间中所有加法常数;
- 在修改后的运行次数函数中,只保留最高阶项;
- 如果在最高阶项存在且不是1,则去除与这个项相乘的常数;
6.常见的时间复杂度
6.1 常数阶
//1+1+1 = 3
void testSum1(int n){
int sum = 0; //执行1次
sum = (1+n)*n/2; //执行1次
printf("testSum2:%d\n",sum);//执行1次
}
这个算法的运行次数函数是f(n) = 3;根据我们大O时间复杂度表示,第一步先把常数项改成1. 在保留最高阶时发现,它根本没有最高阶. 所以这个算法的视觉复杂度为O(1);
//1+1+1+1+1+1+1 = 7
void testSum2(int n){
int sum = 0; //执行1次
sum = (1+n)*n/2; //执行1次
sum = (1+n)*n/2; //执行1次
sum = (1+n)*n/2; //执行1次
sum = (1+n)*n/2; //执行1次
sum = (1+n)*n/2; //执行1次
printf("testSum2:%d\n",sum);//执行1次
}
事实上,无论常数n是多少.以上的代码执行3次还是7次的差异,执行时间恒定.我们的都称之为具有O(1)的时间复杂度.又称为"常数阶";
6.2 线性阶
线性阶的循环结构会复杂很多. 要确定某个算法的阶次,我们常常需要先确定某个特定语句或某个语句集的运行次数. 因此,我们要分析算法的复杂度,关键就是要分析循环结构的运行情况.
void add2(int x,int n){
for (int i = 0; i < n; i++) {
x = x+1;
}
}
这段代码的循环的视觉复杂度为O(n)
6.3 对数阶
int count = 1;
while(count < n){
count = count * 2;
}
count = count * 2 ; 每次执行这句代码,就会距离n更近一步; 也就是说, 有多少个2相乘后大于n,则会退出循环.

6.4 平方阶
/x=x+1; 执行n*n次
void add3(int x,int n){
for (int i = 0; i< n; i++) { //执行n次
for (int j = 0; j < n ; j++) {// 执行 n * n次
x=x+1;
}
}
}
总共执行 n + n^2 次;取最大数,所以以上代码的循环次数为O(n^2);
6.5 立方阶
void testB(int n){
int sum = 1; //执行1次
for (int i = 0; i < n; i++) { //执行n次
for (int j = 0 ; j < n; j++) { //执行n*n次
for (int k = 0; k < n; k++) {//执行n*n*n次
sum = sum * 2; //执行n*n*n次
}
}
}
}
总共执行:1 + n + n * n + n * n * n + n * n * n 次, 取最大数,所以以上代码的循环次数为O(n^3);
6.6 指数阶
void testC(int n){
int sum = 1; //执行1次
for (int i = 0; i < n; i++) { //执行n次
for (int j = 0 ; j < n; j++) { //执行n*n次
for (int k = 0; k < n; k++) {//执行n*n*n次
for ...{ //执行n*n*n * n * ...... n次
sum = sum * 2; //执行n*n*n次
}
}
}
}
}
由于指数阶太大,一般不这样设计算法,表示法:O(n!);
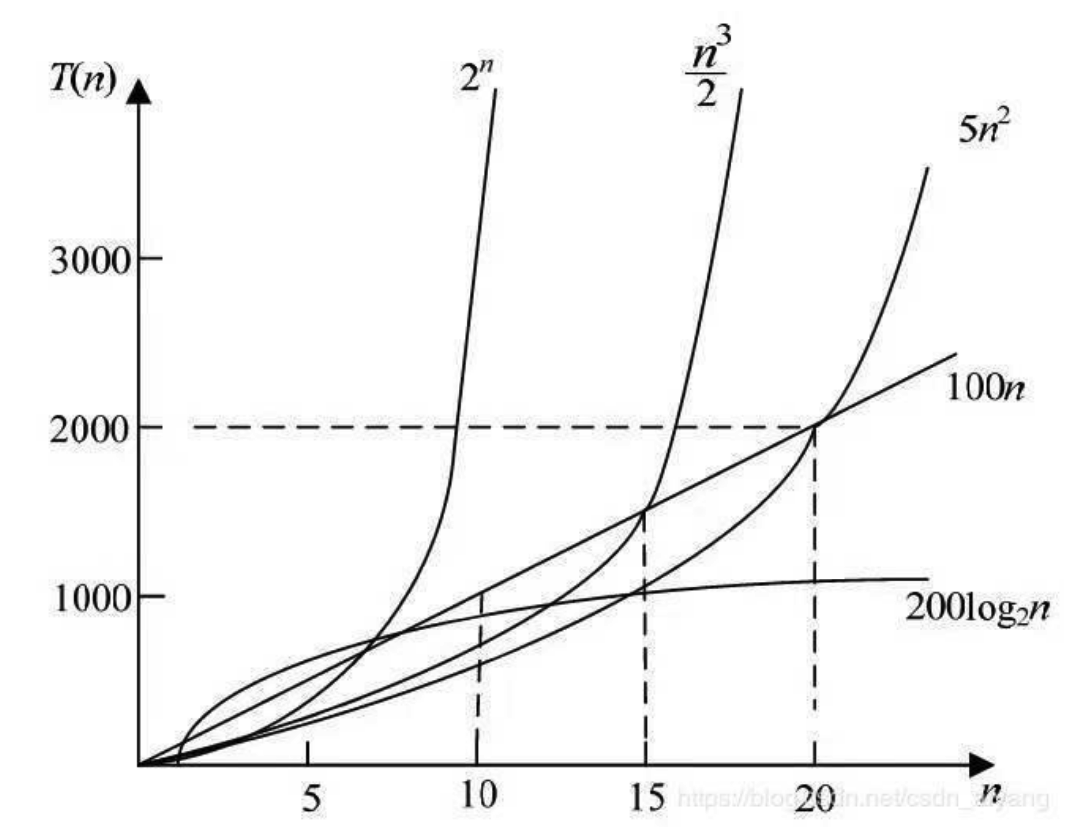
算法的时间复杂度是衡量一个算法好坏的重要指标。一般情况下,随着规模n的增大,次数T(n)的增长较慢的算法为最优算法。常见时间复杂度从小到大依次排列:O(1) < O(log2n) < O(n) < O(n²)<O(n³) ····<O(n!)
7.算法空间复杂度计算
空间复杂度(space complexity)作为算法所需存储空间的量度,记做S(n) = O (f(n))。其中,n为问题的规模;f(n)为语句关于n的所占存储空间的函数。
一般情况下,一个程序在机器上运行时,除了需要存储程序本身的指令、常数、变量和输入数据外,还需要存储对数据操作的存储单位。若输入数据所占空间只取决于问题本身,和算法无关,这样只需要分析该算法在实现时所需的辅助单元即可。若算法执行时所需的辅助空间相对于输入数据量而言是个常量,则称此算法为原地工作,空间复杂度为O(1)。 举个例子:
int n = 5;
int a[10] = {1,2,3,4,5,6,7,8,9,10}; //算法实现(1)
int temp; // temp 为辅助空间
for(int i = 0; i < n/2 ; i++){
temp = a[i];
a[i] = a[n-i-1];
a[n-i-1] = temp;
}
以上例子只需要用到辅助空间temp,所以空间复杂度为O(1)
int n = 5;
int a[10] = {1,2,3,4,5,6,7,8,9,10}; //算法实现(2)
int b[10] = {0};
for(int i = 0; i < n;i++){
b[i] = a[n-i-1];
}
for(int i = 0; i < n; i++){
a[i] = b[i];
}
例子中需要用到b(n)的辅助空间(辅助空间 的长度要比n的长度大),所以空间复杂度为O(n)
