

内容介绍
计数排序简介
我们知道目前排序速度最快的是时间复杂度为O(nlogn)的排序算法,如快速排序、归并排序和堆排序。其中O(logn)是利用了分治思想进行数据二分远距离比较和交换元素的位置。之前的算法都是基于元素比较的,有没有一种算法,它的时间复杂度小于O(nlogn)呢?这样的算法是存在的。计数排序就是一个非基于比较的排序算法,该算法于1954年由 Harold H. Seward提出。它的优势在于在对一定范围内的整数排序时,它的复杂度为Ο(n+k)(其中k是整数的范围),快于任何比较排序算法。 当然这是一种牺牲空间换取时间的做法。
计数排序适用于数据量很大,但是数据的范围比较小的情况。比如对一个公司20万人的年龄进行排序,要排序的数据量很大,但是年龄分布在0 ~ 134岁之间(最大年龄数据来源吉尼斯世界记录)。
计数排序的思想
使用一个辅助数组,遍历待排序的数据,待排序数据的值就是辅助数组的索引,辅助数组索引对应的位置保存这个待排序数据出现的次数。最后从辅助数组中取出待排序的数据,放到排序后的数组中。
计数排序动画演示
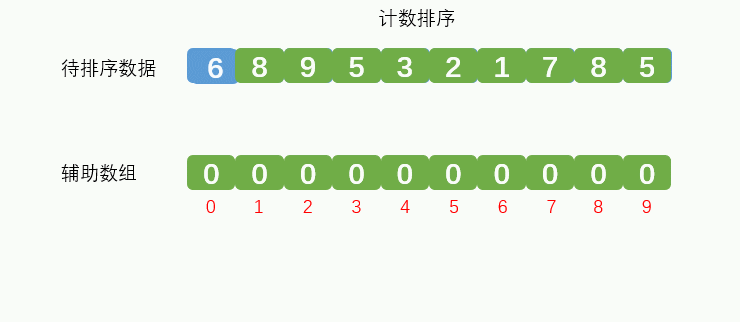
一般没有特殊要求排序算法都是升序排序,小的在前,大的在后。数组由{6, 8, 9, 5, 3, 2, 1, 7, 8, 5} 这10个无序元素组成。
计数排序分析
通过上面的动画演示,我们可以将计数排序分为两个过程:
- 统计过程
- 排序过程。
假设我们要排序的数据是10个0到9的随机数字,例如{6, 8, 9, 5, 3, 2, 1, 7, 8, 5} 这10个数据,如下图所示:

- 统计过程
取出元素6,放到辅助数组索引6的地方,辅助数组记录数据6出现1次,效果如下图: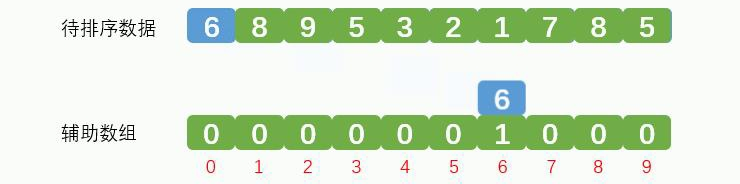
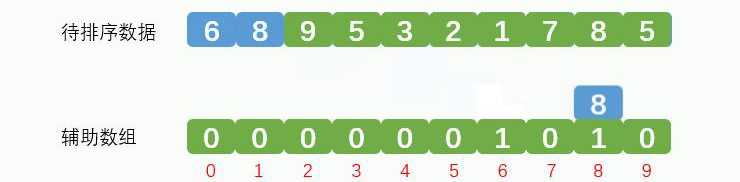
取出元素8,放到辅助数组索引8的地方,辅助数组记录数据8出现1次,效果如下图:
取出元素9,放到辅助数组索引9的地方,辅助数组记录数据9出现1次,效果如下图:
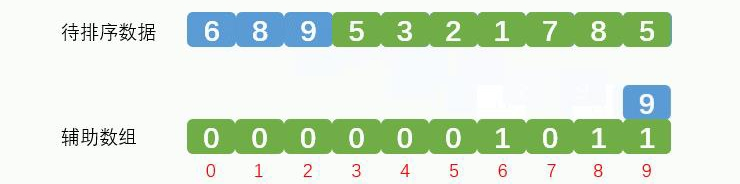
依次类推。中间省略一部分。
再次取出元素8,放到辅助数组索引8的地方,辅助数组记录数据8出现2次,效果如下图:
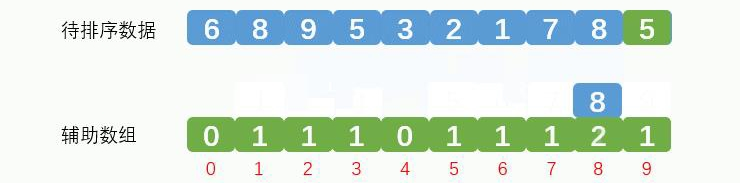
最终辅助数组效果如下:
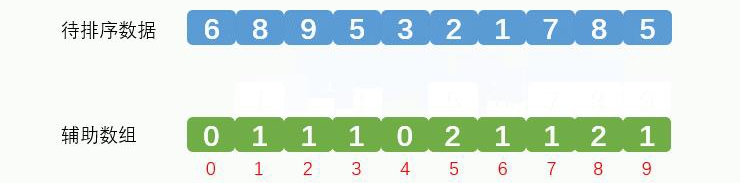
这个辅助数组统计了每个数据出现的次数,最后遍历这个辅助数组,辅助数组中的索引就是元素的值,辅助数组中索引对应的值就是这个数据出现的次数,放到排序后的数组中。
- 排序过程
辅助数组索引1的对应的数据1放到排序后数组中,效果如下: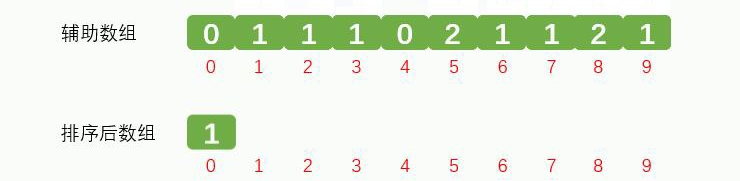
辅助数组索引2的对应的数据2放到排序后数组中,效果如下:
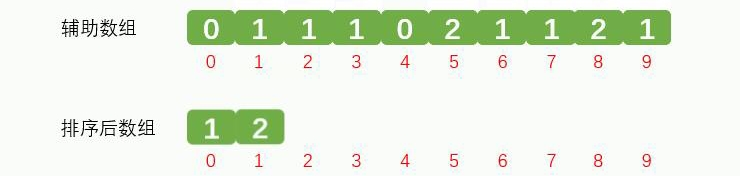
依次类推,取出统计数组中的数据放到排序后的数组中,中间省略部分。
辅助数组索引5的对应的数据5放到排序后数组中,效果如下:
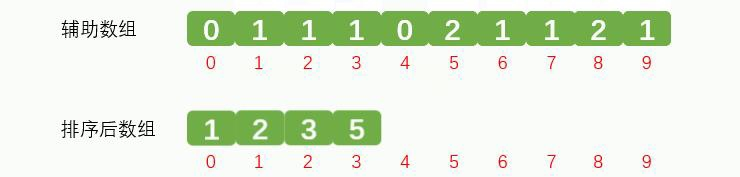
再次将辅助数组索引5的对应的数据5放到排序后数组中,效果如下:
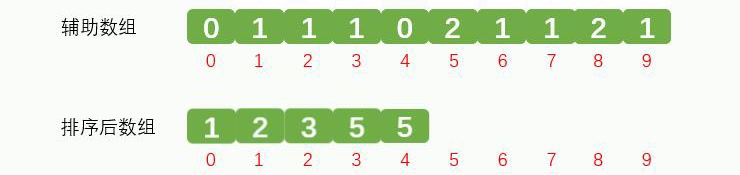
依次类推,中间省略部分。
最终排序后的效果如下:
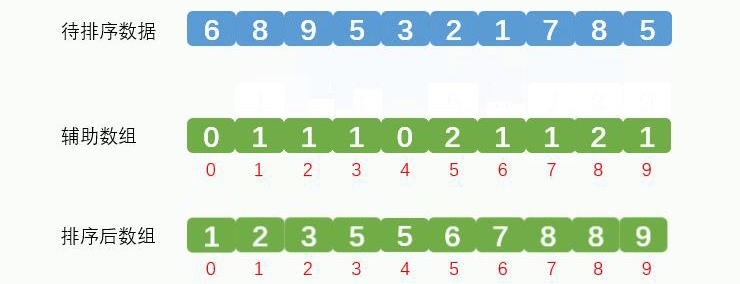
计数排序代码编写
public class CountSortTest {
public static void main(String[] args) {
int[] arr = new int[] {6, 8, 9, 5, 3, 2, 1, 7, 8, 5};
countSort(arr);
System.out.println("排序后:" + Arrays.toString(arr));
}
// 假设我们要排序的数据是10个0到9的随机数字
public static void countSort(int[] arr) {
// 1.得到待排序数据的最大值
int max = arr[0];
for (int i = 1; i < arr.length; i++) {
int num = arr[i];
if (num > max)
max = num;
}
// 2.创建一个辅助数组长度是最大值+1
int[] countArr = new int[max+1];
// 3.遍历待排序的数据,放到辅助数组中进行统计
for (int i = 0; i < arr.length; i++) {
// arr[i]取出待排序的数据,假设是5
// countArr[arr[i]] 就是 countArr[5]
// countArr[5]++;
countArr[arr[i]]++; // 取出待排序的数据,找到数据在辅助数组对应的索引,数量加1
}
// 4.遍历辅助数据,将统计到的待排序数据放到已排序的数组中
int index = 0; // 用于记录当前数据放到已排序数组的哪个位置
// 已排序数组和待排序数组一样长
int[] sortedArr = new int[arr.length];
for (int i = 0; i < countArr.length; i++) {
while (countArr[i] > 0) {
sortedArr[index++] = i;
countArr[i]--;
}
}
// 5.将已排序的数据放到待排序的数组中
for (int i = 0; i < sortedArr.length; i++) {
arr[i] = sortedArr[i];
}
}
}
计数排序优化1
对任意指定范围内的数字进行排序。
刚才我们的计数排序规定数据是 0 ~ 9这十个范围内的数字。有可能排序的数据不是从0开始,例如下面这个数{68, 65, 72, 74, 73, 72, 70, 71, 69, 70, 67, 70, 66}是65 ~ 74这十个范围内的数字。我们按照刚才的代码辅助数组的长度需要为75,其实这是没有必要的,我们可以看到0 ~ 64这个范围内根本没有数字。浪费了数组上0 ~ 63索引位置上的存储空间。我们可以把65放到索引0,66放到索引1,依次类推,效果如下图:
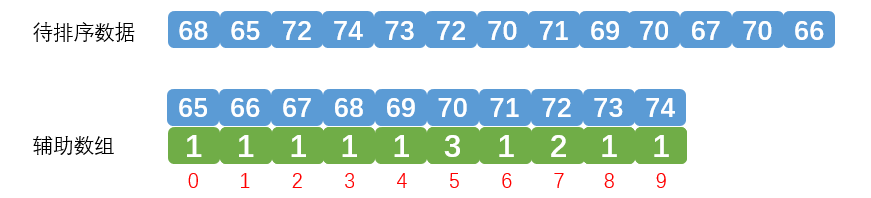
通过上图可以看到,我们需要找到待排数据中的最小值和最大值,使用(最大值-最小值+1)来作为辅助数组的长度。最小值放到辅助数组0索引的位置,依次往后推。
辅助数组的长度=10 (74-65+1)
69元素在辅助数组的位置=4 (69-65)
优化后代码:
public class CountSortTest2 {
public static void main(String[] args) {
int[] arr = new int[] {68, 65, 72, 74, 73, 72, 70, 71, 69, 70, 67, 70, 66};
countSort(arr);
System.out.println("排序后:" + Arrays.toString(arr));
}
// 假设我们要排序的数据是10个65到74的随机数字
public static void countSort(int[] arr) {
// 1.得到待排序数据的最大/最小值
int max = arr[0];
int min = arr[0];
for (int i = 1; i < arr.length; i++) {
int num = arr[i];
if (num > max)
max = num;
else if (num < min)
min = num;
}
// 2.创建一个辅助数组长度是最大值+1
int[] countArr = new int[max-min+1];
// 3.遍历待排序的数据,放到辅助数组中进行统计
for (int i = 0; i < arr.length; i++) {
// arr[i]取出待排序的数据,假设是69
// countArr[arr[i]-min] 就是 countArr[69-65]
// countArr[4]++;
countArr[arr[i]-min]++; // 取出待排序的数据,找到数据在辅助数组对应的索引,数量加1
}
// 4.遍历辅助数据,将统计到的待排序数据放到已排序的数组中
int index = 0; // 用于记录当前数据放到已排序数组的哪个位置
// 已排序数组和待排序数组一样长
int[] sortedArr = new int[arr.length];
for (int i = 0; i < countArr.length; i++) {
while (countArr[i] > 0) {
sortedArr[index++] = min + i;
countArr[i]--;
}
}
// 5.将已排序的数据放到待排序的数组中
for (int i = 0; i < sortedArr.length; i++) {
arr[i] = sortedArr[i];
}
}
}
计数排序优化2
保证计数排序的稳定性。
到目前为止,我们的计数排序可以实现一定范围内的排序,但是还存在一个问题,相同的数据我们排序时没有保证顺序,也就是说现在的计数排序时不稳定的排序,如下图所示:
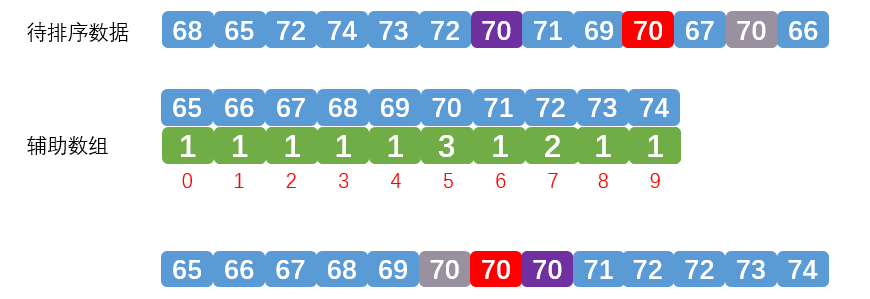
从上图可以看到待排序中有3个相同的数据70,通过计数排序后,这3个70的位置改变了。那么如何保证计数排序的稳定性呢?我要先分析一下为什么会造成不稳定,上面说过计数排序分成两个过程:1.统计过程,2.排序过程。问题就出现在这两个过程中。
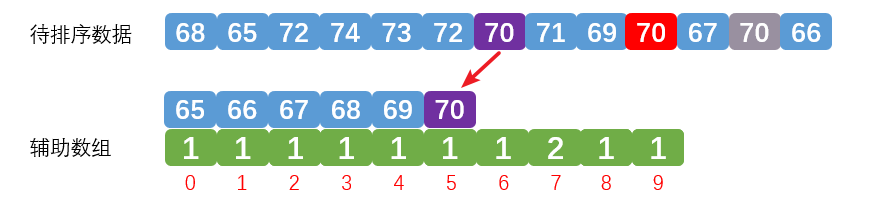
我们先来看一下统计的过程:
第一次统计紫色数字70,效果如下:
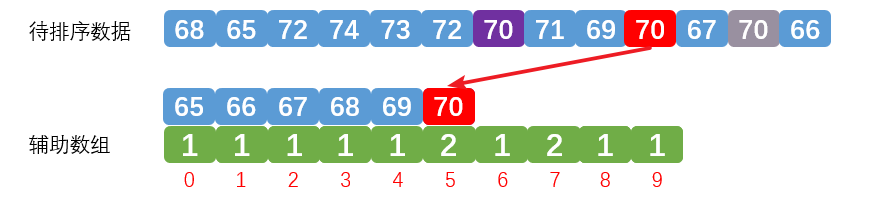
第二次统红色计数字70,效果如下:
第三次统计灰色数字70,效果如下:
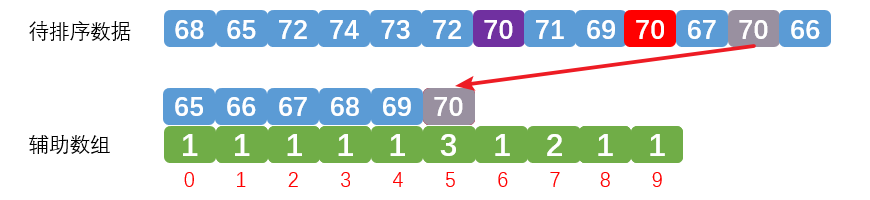
我们再来看一下排序的过程:
第一次排序,排序的是第三个灰色数字70,效果如下:
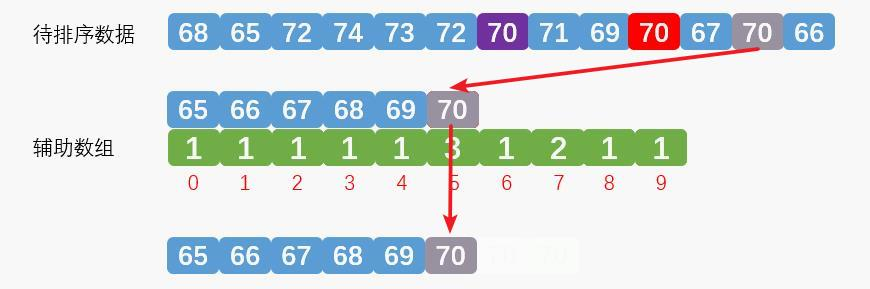
第二次排序,排序的是第二个红色数字70,效果如下:
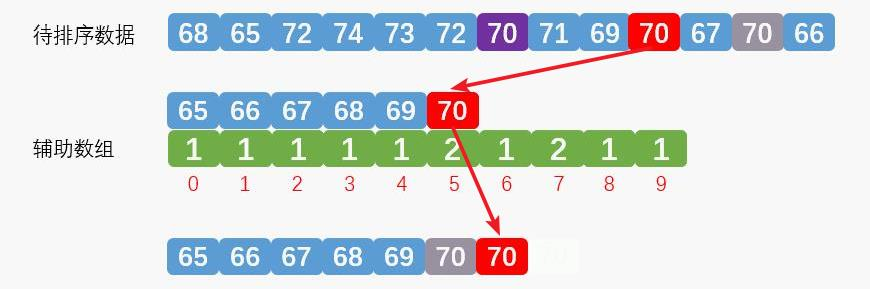
第三次排序,排序的是第一个紫色色数字70,效果如下:
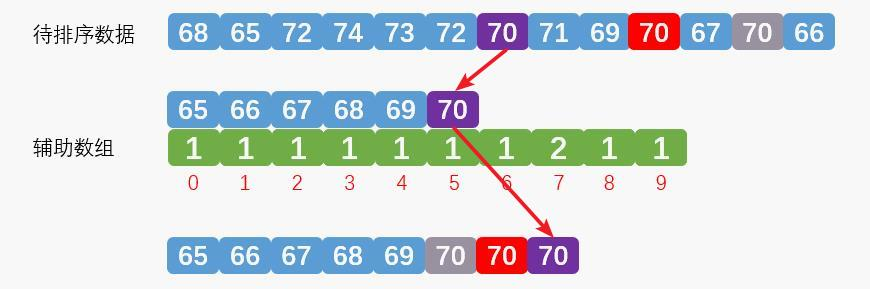
通过上面的分析我们就知道导致计数排序是不稳定排序的原因了,统计时最后一个灰色的数字70在排序时被第一个取出排序,第一个紫色的70被最后一次取出排序。总结就是统计时的顺序和排序时的顺序不对应。知道原因了解决就好办了。
要让计数排序是稳定排序,只要保证统计时和排序时操作相同数字的顺序是对应的(后统计的先参与排序)。如下图所示:
统计时第三个灰色的数字70第一次取出放到合适的地方,如下图:
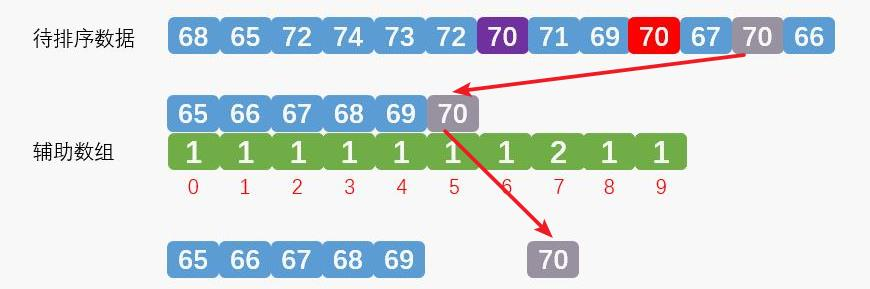
统计时第二个红色的数字70第二次取出放到合适的地方,如下图:
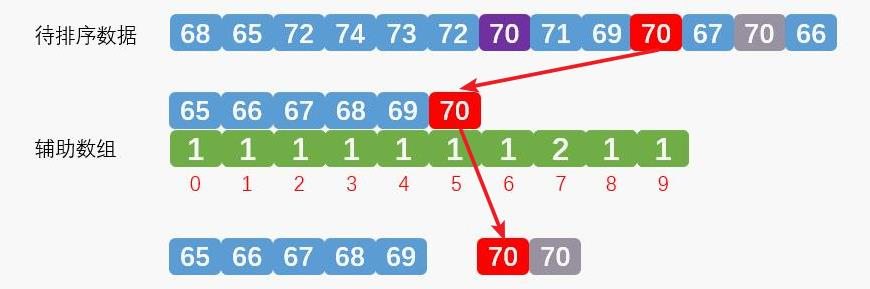
统计时第一个紫色的数字70第三次取出放到合适的地方,如下图:
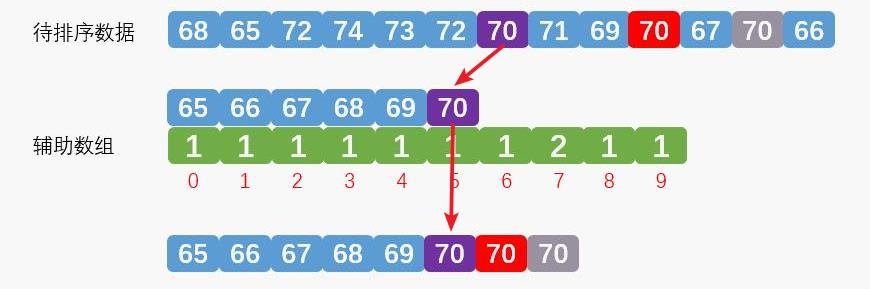
如何做到上图中的相同数据后统计的先参与排序,这个地方有点绕,要注意啦!我们需要保证两点:
- 统计时,计算相同数据具体保存的位置。
- 排序时,从待排序数组倒序遍历,从后往前获取数据。
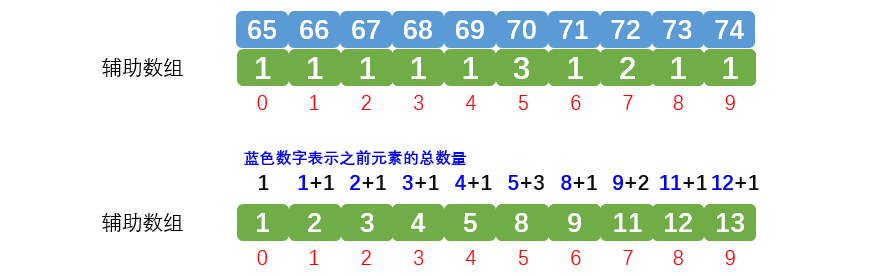
我们先看第一点:统计时,计算相同数据具体保存的位置。
辅助数组在统计当前元素数量时加上之前元素的数量,就可以确定当前元素所在的位置,效果如下:
我们再看第二点:排序时,从待排序数组倒序遍历,从后往前获取数据,可以保证后统计的数据先参与排序。动画效果如下:
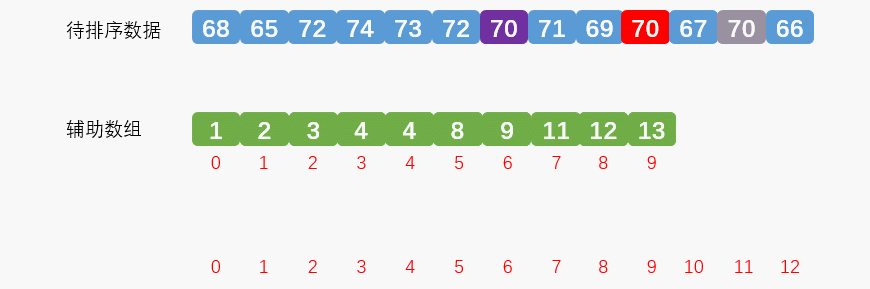
优化后代码如下:
public class CountSortTest3 {
public static void main(String[] args) {
int[] arr = new int[] {68, 65, 72, 74, 73, 72, 70, 71, 69, 70, 67, 70, 66};
countSort(arr);
System.out.println("排序后:" + Arrays.toString(arr));
}
// 假设我们要排序的数据是10个65到74的随机数字
public static void countSort(int[] arr) {
// 1.得到待排序数据的最大/最小值
int max = arr[0];
int min = arr[0];
for (int i = 1; i < arr.length; i++) {
int num = arr[i];
if (num > max)
max = num;
else if (num < min)
min = num;
}
// 2.创建一个辅助数组长度是最大值+1
int[] countArr = new int[max-min+1];
// 3.遍历待排序的数据,放到辅助数组中进行统计
for (int i = 0; i < arr.length; i++) {
// arr[i]取出待排序的数据,假设是69
// countArr[arr[i]-min] 就是 countArr[69-65]
// countArr[4]++;
countArr[arr[i]-min]++; // 取出待排序的数据,找到数据在辅助数组对应的索引,数量加1
}
// 4.对辅助数组进行加工处理
for (int i = 1; i < countArr.length; i++) {
countArr[i] += countArr[i-1];
}
System.out.println("Arrays.toString() = " + Arrays.toString(countArr));
// 5.倒序遍历源数组
// 已排序数组和待排序数组一样长
int[] sortedArr = new int[arr.length];
for (int i = arr.length-1; i >= 0; i--) {
// 得到这个待排序的数据`arr[i]`,去辅助数组中找到合适的位置`arr[i]-min`,放到已排序数组中`countArr[arr[i]-min]`
// arr[i]: 待排序的数据
// arr[i]-min: 待排序的数据在辅助数组中的位置
// countArr[arr[i]-min-1]: 待排序数据再已排序数组的位置
sortedArr[countArr[arr[i]-min]-1] = arr[i];
// 辅助数组中该数据的数量减一,也就是后续相同数据放到前面一个位置
countArr[arr[i]-min]--;
}
// 6.将已排序的数据放到待排序的数组中
for (int i = 0; i < sortedArr.length; i++) {
arr[i] = sortedArr[i];
}
}
}
计数排序的复杂度
假设数据规模为n,数据范围为k。
计数排序的空间复杂度:辅助数组需要m个空间,排序后的数组和待排序数组是一样长的,所以总的空间复杂度是O(n+m)。
计数排序的时间复杂度:1.得到待排序数据的最大/最小值遍历一次源数组操作次数为n,3.遍历待排序的数据,放到辅助数组中进行统计操作次数为n,4.对辅助数组进行加工处理操作次数为k,5.倒序遍历源数组操作次数为n,6.将已排序的数据放到待排序的数组中操作次数为n,总操作次数为:4n+m。所以总的时间复杂度为O(n+k)。
计数排序的局限性
待排序数据范围过大不适用于计数排序。假设有100个整数,他们的范围是0到两千万,如果使用计数排序需要一个长度为一千万零一的数组,其中只有100位置存储了数据,剩余都是没有存储数据,浪费空间。如果有负整数,可以加上一个固定的常数使得待排序列的最小值为0。
待排序数据不是整数不适用于计数排序。假设有100个小数,他们的范围是0到1,但是0到1之间的小数有无数个,无法使用计数排序进行排序,因为连开辟多大的辅助数组都不能确定。
总结
计数排序就是一个非基于比较的排序算法,它的优势在于在对一定范围内的整数排序时,它的复杂度为Ο(n+k)(其中k是整数的范围),快于任何比较排序算法。
计数排序适用于数据量很大,但是数据的范围比较小的情况。比如对一个公司20万人的年龄进行排序,要排序的数据量很大,但是年龄分布在0 ~ 134岁之间(最大年龄数据来源吉尼斯世界记录)。
计数排序的思想:使用一个辅助数组,遍历待排序的数据,待排序数据的值就是辅助数组的索引,辅助数组索引对应的位置保存这个待排序数据出现的次数。最后从辅助数组中取出待排序的数据,放到排序后的数组中。

---------- End ----------
原创文章和动画制作真心不易,您的点赞就是最大的支持!
想了解更多文章请关注微信公众号:表哥动画学编程
