

内容介绍
树结构简介
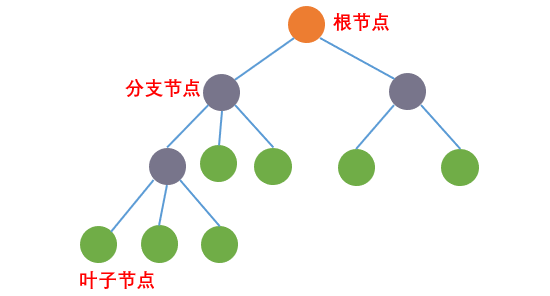
树结构是计算机中常用的一种数据结构。我们先来看一下生活中的树:

计算机中的树和生活中的树是类似的,只不过是倒着的,树根在上,树叶在下。树上的每个组成元素都是一个节点,树根称为根节点,树枝称为分支节点,树叶称为叶子节点,如下图所示:
二叉树结构简介
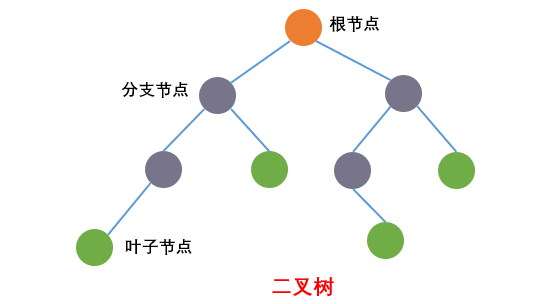
二叉树是:每个节点最多只能有两个子节点树。二叉树的子节点分为左节点和右节点,如下图:
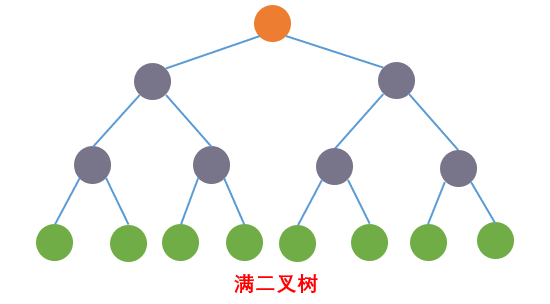
满二叉树:如果该二叉树的所有叶子节点都在最后一层,并且节点总数= 2^n -1 , n 为层数,则我们称为满二叉树,如下图:
完全二叉树:如果该二叉树的所有叶子节点都在最后一层或者倒数第二层,而且最后一层的叶子节点在左边连续,倒数第二
层的叶子节点在右边连续,我们称为完全二叉树,如下图:
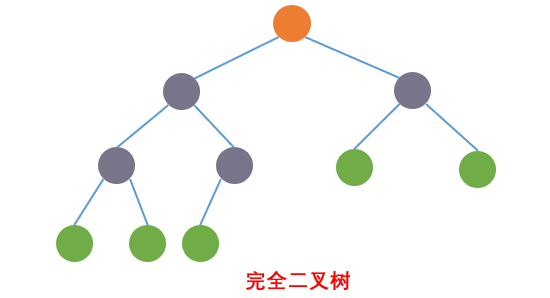
我们这里注意理解完全二叉树,因为堆结构是一种特殊的完全二叉树。关于树的结构,我们先简单介绍,以后会专门讲解树结构,我们这里主要是讲堆结构,所以先简单提及一下树结构。
堆结构简介
堆(Heap)是一种特殊的树形数据结构,每个结点都有一个值。常见的堆有二叉堆、斐波那契堆等,通常我们所说的堆的数据结构,是指二叉堆。如下图:
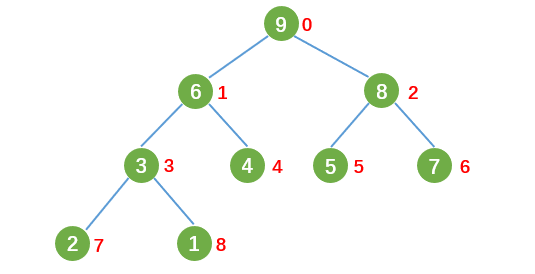
堆满足下列两个性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值。
- 堆总是一棵完全二叉树。
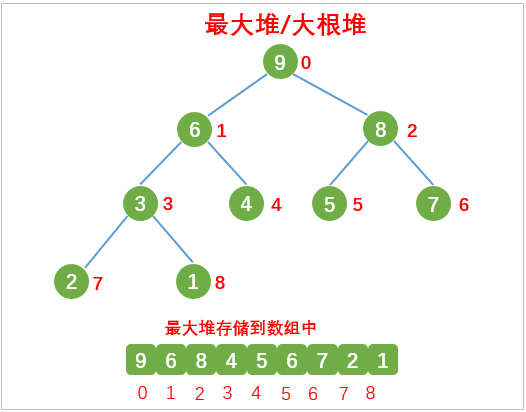
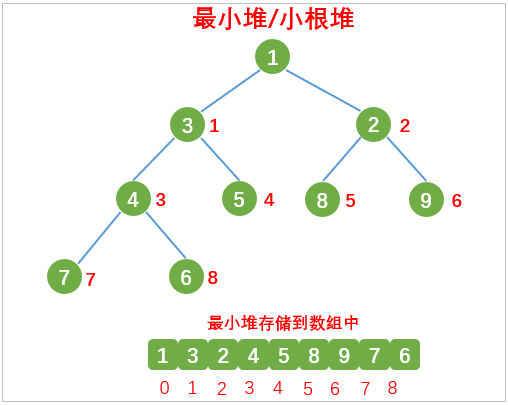
根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆,如下图所示: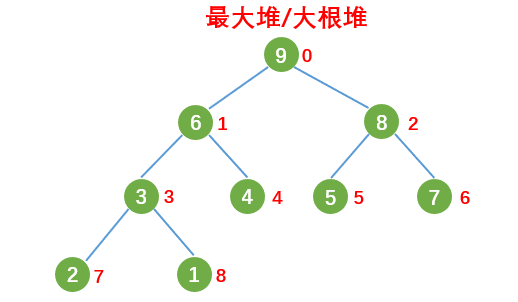
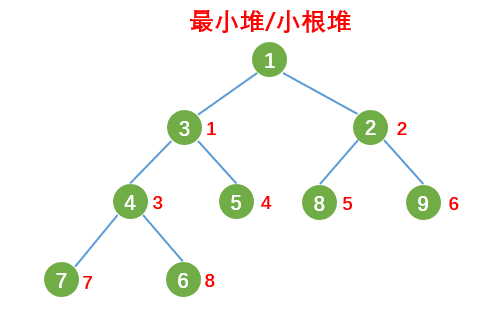
堆的存储
堆是非线性数据结构,可以使用一维数组来存储,将堆中序号对应的数据放到数组对应的索引中,如下图:
堆的一些概念和规律
概念:
- 某节点左边的子节点成为:左孩子。
- 某节点右边的子节点成为:右孩子。
- 某节点的上一个节点成为:父节点。

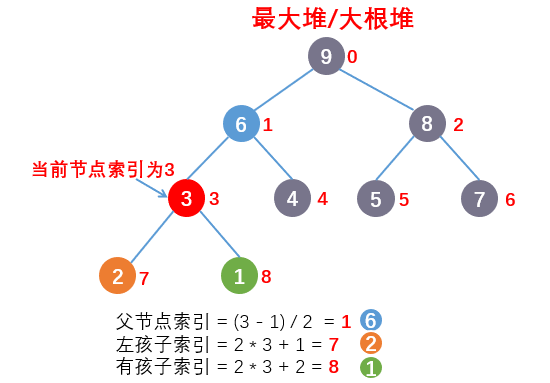
规律:假设当前节点的索引为i
- 父节点索引 = (i - 1) / 2 (Java中除以2取整数,比如7/2 = 3)
- 左孩子索引 = 2 * i + 1
- 右孩子索引 = 2 * i + 2
堆的定义性质:
- 最大堆节点的值大于左右孩子的值,也就是满足:
arr[i] > arr[2i+1] && arr[i] > arr[2i+2],如下图: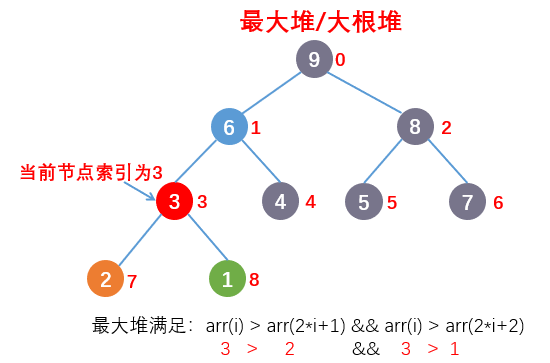
堆获取最大值
获取最大堆的最大值,其实就是获取堆中最前面一个元素。对于堆这种数据结构通常是将最前面的元素和最后面的元素换位置,最大值就到了最后一个位置,然后从堆中排除这个元素,当最后一个元素交换到最前面时,此时就不满足堆的性质了,我们需要将最前面这个元素通过ShiftDown(下沉)的手段让堆继续满足堆的规则。
堆获取最大值可以分成两个步骤:
- 将堆中最前面的最大值和最后一个元素交换位置。
- 使用
ShiftDown让最前面的元素下沉到合适的位置,依然满足堆的性质。
动画演示效果如下: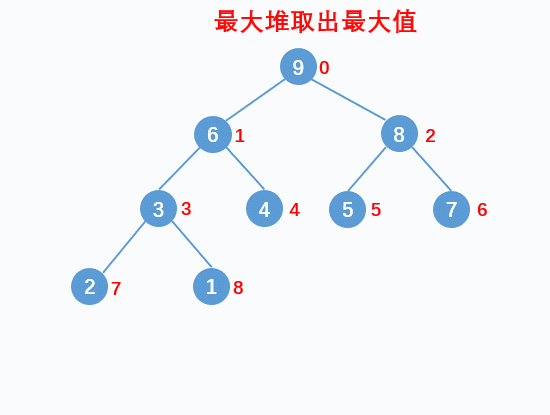
这里面重点注意,ShiftDown可以让堆中的一个元素下沉到合适的位置,并且满足堆的规则。后面我们构建堆就需要使用到ShiftDown操作。
ShiftDown详细图解:

最大堆的最后一个非叶子节点
- 我们构建堆时需要从最后一个非叶子节点开始按照规则构建堆,所以我们需要知道最后一个非叶子节点计算公式:(堆的最大索引-1) / 2。
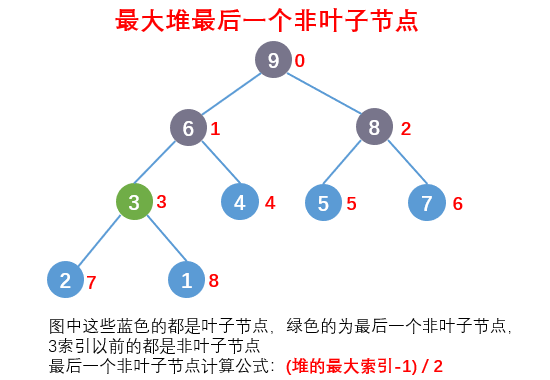
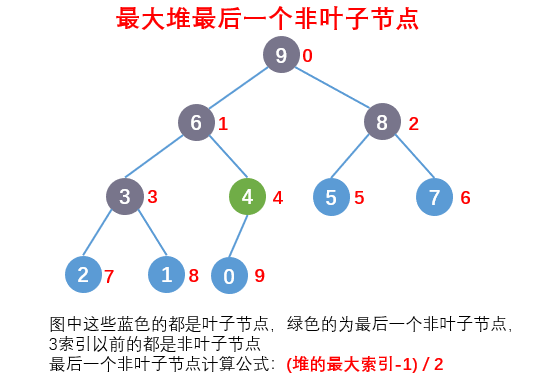
构建一个堆结构
构建堆其实是将无序的完全二叉树调整为二叉堆。非叶子节点没有子节点不需要重新构建,然后自底向上对每一个子树执行SiftDown操作,直到完成二叉堆化。
假设我们现在有一个数组,内容为:{6, 3, 7, 5, 8, 2, 1, 4, 9},它是不满足堆的规则,我们现在将这个数组构建成一个二叉堆,步骤为:
- 找到最后一个非叶子节点,使用
ShiftDown下沉,使这个颗树满足堆的规则。 - 找到倒数第二个非叶子节点,使用
ShiftDown下沉,使这个颗树满足堆的规则。 - 以此类推,直到找到最前面的一个元素使用
ShiftDown下沉,使这颗树满足堆的规则。
将无序的完全二叉树调整为二叉堆的过程称为heapify,动画如下:
堆添加数据
往堆中插入一个元素,是在数组的最末尾插入新的数据,此时可能不满足堆的特性,我们需要进行自下而上调整子节点和父节点,不满足堆性质则交换父子元素,直到当前子树满足堆的性质。动画效果如下:
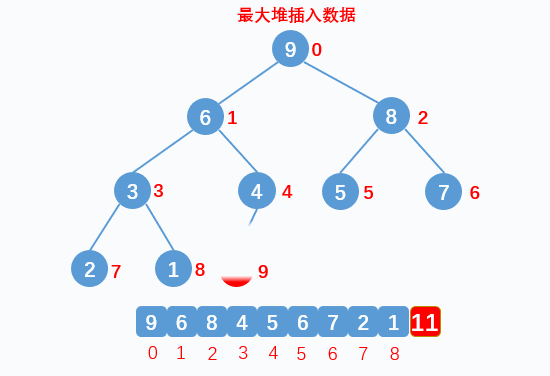
代码如下:
public class Heap {
public static void main(String[] args) {
int[] arr = {6, 3, 7, 5, 8, 2, 1, 4, 9};
heapify(arr);
System.out.println("构建堆后:" + Arrays.toString(arr));
arr = insert(arr, 11);
System.out.println("堆中插入数据后:" + Arrays.toString(arr));
}
// 往数组中添加一个数据
public static int[] insert(int[] arr, int element) {
arr = Arrays.copyOf(arr, arr.length + 1);
// 复制之前的数组数据到新数组中
arr[arr.length-1] = element;
shiftUp(arr, arr.length-1);
return arr;
}
// 上浮操作,将i索引元素上浮到合适位置,保证满足堆的两个特性
private static void shiftUp(int[] arr, int i) {
// (i-1) / 2: 是i的父节点
while ((i-1) / 2 >= 0 && arr[(i-1) / 2] < arr[i]) {
swap(arr, (i-1) / 2, i);
i = (i-1) / 2;
}
}
// heapify将无序的完全二叉树调整为二叉堆
private static void heapify(int[] arr) {
// 从非叶子节点开始,Shift Down将每个子树构建成最大堆
for (int i = (arr.length - 1 - 1) / 2; i >= 0; i--) {
shiftDown(arr, i);
}
}
// 下沉操作,将指定元素下沉到子树的合适位置,使这个颗树满足堆的规则。
private static void shiftDown(int[] arr, int i) {
// 循环找子孩子交换位置。左孩子不能越界
while (2*i + 1 < arr.length) {
// 假设要交换的是左孩子
int j = 2*i + 1;
// 判断是否有有孩子,并且右孩子是否大于左孩子
if (j+1 < arr.length && arr[j+1] > arr[j]) {
j++; // 如果是,和右孩子交换
}
// 如果当前节点大于两个孩子,就不需要交换
if (arr[i] > arr[j])
break;
// 当前节点小于子孩子,将当前节点和较大的子孩子交换
swap(arr, i, j);
// 在判断下一层
i = j;
}
}
public static void swap(int[] arr, int start, int end) {
if (start == end) return;
int temp = arr[start];
arr[start] = arr[end];
arr[end] = temp;
}
}
添加元素放在堆的最后面,使用ShiftUp让元素上浮,让添加的元素找到一个合适的位置,让堆中的数据依然满足堆的特性。
堆的作用
- 用作优先队列,我们知道堆的最前一个元素就是堆的最大值。我们可以依据优先级来构建堆,每次都取出堆中优先级最高的那个数据。
- 用作堆排序。
- 查找第N大(小)元素。
- 查找前N大(小)元素。
后续我们会选择合适的时间来完成上面这些功能。
总结
- 堆是一种特殊的完全二叉树,堆中某个节点的值总是不大于或不小于其父节点的值。堆是非线性数据结构,使用数组来存储,操作堆其实就是操作数组中的数据。
- 假设当前节点的索引为i,父节点索引 =
(i - 1) / 2(Java中除以2取整数,比如7/2 = 3),左孩子索引 =2 * i + 1,右孩子索引 =2 * i + 2。 - 使用
ShiftDown让堆中最前面的元素下沉到合适的位置,让堆依然满足堆的性质。 - 添加元素放在堆的最后面,使用
ShiftUp让元素上浮,让添加的元素找到一个合适的位置,让堆中的数据依然满足堆的特性。

---------- End ----------
原创文章和动画制作真心不易,您的点赞就是最大的支持!
想了解更多文章请关注微信公众号:表哥动画学编程
