

背景
1、项目中需要使用到表情
2、不同设备字体不同,显示效果有差异,有些设备因为无法显示,而以豆腐块替代 “☐”
3、EmojiCompat 支持库,目前官方使用的是NotoColorEmojiCompat.ttf,提供两种方式,可下载的字体配置和本地绑定的字体配置,前者需要Google服务,后者会无形增加Apk包体积,大约7M左右;但缺陷仍然无法避免,那就是无法显示最新的Android表情。解决方案可以更改空间的typeface.
实际应用方案
因为项目中使用的Emoji有限,并且可以接受其他表情在不同设备显示的差异,所以我们将自定义表情的Drawable和表情编码做了映射。
知识点
1、字符编码 字符集为每个字符分配了一个唯一的编号,通过这个编号就能找到对应的字符。在编程过程中我们经常会使用字符,而使用字符的前提就是把字符放入内存中,毫无疑问,放入内存中的仅仅是字符的编号,而不是真正的字符实体。
对于 ASCII 字符集,这很容易。ASCII 总共包含 128 个字符,用 7 个比特位(Bit)恰好能够存储,不过考虑到计算机一般把字节(Byte)作为基本单元,为了操作方便,我们不妨用一个字节(也就是 8 个比特位)来存储 ASCII。这样虽然浪费了一个比特位,但是读写效率提高了。
但是对于 Unicode,问题就没有这么简单了。Unicode 目前已经包含了上百万的字符,位置靠前的字符用一个字节就能存储,位置靠后的字符用三个字节才能存储。我们可以为所有字符都分配三个字节的内存,也可以为编号小的字符分配一个字节或者两个字节的内存,而为编号大的字符分配三个字节的内存。
字符集和字符编码不是一个概念,字符集定义了文字和二进制的对应关系,为字符分配了唯一的编号,而字符编码规定了如何将文字的编号存储到内存中。有的字符集在制定时就考虑到了编码的问题,是和编码结合在一起的;有的字符集只管制定字符的编号,至于怎么编码,是其他人的事情。
方案1:为每个字符分配固定长度的内存
方案2:为每个字符分配尽量少的内存
有的编码方式采用 1~n 个字节存储,是变长的,例如 UTF-8、GB2312、GBK 等;如果一个字符使用了这种编码方式,我们就将它称为多字节字符,或者窄字符。
有的编码方式是固定长度的,不管字符编号大小,始终采用 n 个字节存储,例如 UTF-32、UTF-16 等;如果一个字符使用了这种编码方式,我们就将它称为宽字符。
Unicode 字符集可以使用窄字符的方式存储,也可以使用宽字符的方式存储;GB2312、GBK、Shift-JIS 等国家编码一般都使用窄字符的方式存储;ASCII 只有一个字节,无所谓窄字符和宽字符。
2、Unicode
unicode为每种语言中的每个字符设定了统一并且唯一的二进制编码 Unicode 是一个独立的字符集,它并不是和编码绑定的,可以为每个字符分配固定长度的内存,也可以,为每个字符分配尽量少的内存。需要注意的是,Unicode 只是一个字符集,在制定的时候并没有考虑编码的问题,但是采用后者,就不能从字符集本身下手了,只能从字符编号下手,这样在存储和读取时都要进行适当的转换。
Unicode 可以使用的编码有三种,分别是:
UFT-8:一种变长的编码方案,使用 1~6 个字节来存储; UFT-32:一种固定长度的编码方案,不管字符编号大小,始终使用 4 个字节来存储; UTF-16:介于 UTF-8 和 UTF-32 之间,使用 2 个或者 4 个字节来存储,长度既固定又可变。
UTF 是 Unicode Transformation Format 的缩写,意思是“Unicode转换格式”,后面的数字表明至少使用多少个比特位(Bit)来存储字符。
3、UTF-8编码规则
编码规则如下:
对于单个字节的字符,第一位设为 0,后面的 7 位对应这个字符的 Unicode 码点。因此,对于英文中的 0 - 127 号字符,与 ASCII 码完全相同。这意味着 ASCII 码那个年代的文档用 UTF-8 编码打开完全没有问题。
对于需要使用 N 个字节来表示的字符(N > 1),第一个字节的前 N 位都设为 1,第 N + 1 位设为0,剩余的 N - 1 个字节的前两位都设位 10,剩下的二进制位则使用这个字符的 Unicode 码点来填充。

举个例子:
Java中的String对象就是一个unicode编码的字符串。
java中想知道一个字符的unicode编码我们可以通过Integer.toHexString()方法
String str = "编";
StringBuffer sb = new StringBuffer();
char [] source_char = str.toCharArray();
String unicode = null;
for (int i=0;i<source_char.length;i++) {
unicode = Integer.toHexString(source_char[i]);
if (unicode.length() <= 2) {
unicode = "00" + unicode;
}
sb.append("\\u" + unicode);
}
System.out.println(sb);
输出\u7f16
7f16在0800-FFFF之间,所以要用3字节模板:1110xxxx 10xxxxxx 10xxxxxx。 7f16写成二进制是:0111 1111 0001 0110 按三字节模板分段方法分为0111 111100 010110,代替模板中的x,得到11100111 10111100 10010110,即“编”对应的utf-8的编码是e7 bc 96,占3个字节
4、UTF-16编码规则
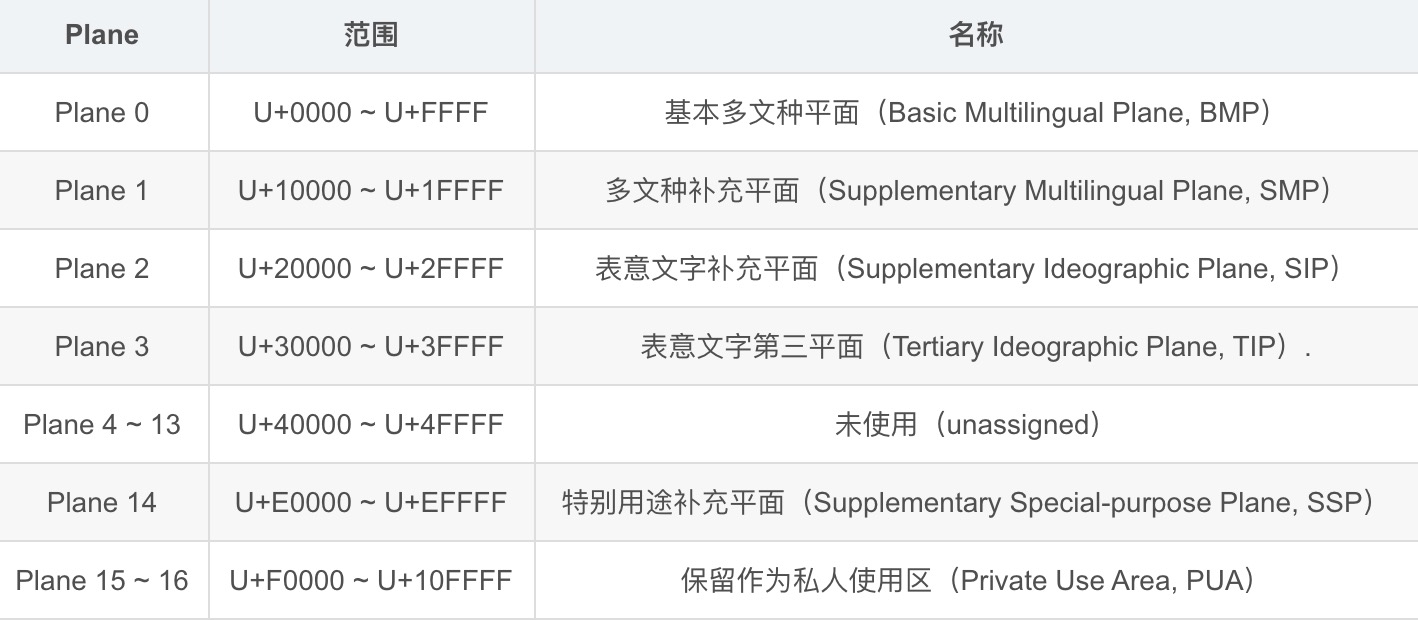
Unicode的编码范围为U+0000 ~ U+10FFFF,一共包含2^16∗17=1114112个码位。 整个编码空间划分为17个平面(plane),每个平面包含2^16=65536216=65536个码位(codepoint)。最前面的 65536 个字符位,称为基本平面(Basic Multilingual Plane简称 BMP ),它的码点范围是从 0 到 2^16-1,写成 16 进制就是从 U+0000 到 U+FFFF。所有最常见的字符都放在这个平面,这是 Unicode 最先定义和公布的一个平面。剩下的字符都放在辅助平面(简称 SMP ),码点范围从 U+010000 到 U+10FFFF。。
平面的概念来源于UTF-16的编码,双字符能编码16个平面2^16∗16=2^20=1048576216∗16=210∗210=220=1048576个码位,加上单字符BMP平面,一共17个平面。
基本平面的字符占用 2 个字节,辅助平面的字符占用 4 个字节。也就是说,UTF-16 的编码长度要么是 2 个字节(U+0000 到 U+FFFF),要么是 4 个字节(U+010000 到 U+10FFFF)。那么问题来了,当我们遇到两个字节时,到底是把这两个字节当作一个字符还是与后面的两个字节一起当作一个字符呢?
在基本平面内,从 U+D800 到 U+DFFF 是一个空段,即这些码点不对应任何字符。因此,这个空段可以用来映射辅助平面的字符。
辅助平面的字符位共有 2^20 个,因此表示这些字符至少需要 20 个二进制位。UTF-16 将这 20 个二进制位分成两半,前 10 位映射在 U+D800 到 U+DBFF,称为高位(H),后 10 位映射在 U+DC00 到 U+DFFF,称为低位(L)。这意味着,一个辅助平面的字符,被拆成两个基本平面的字符表示。
因此,当我们遇到两个字节,发现它的码点在 U+D800 到 U+DBFF 之间,就可以断定,紧跟在后面的两个字节的码点,应该在 U+DC00 到 U+DFFF 之间,这四个字节必须放在一起解读。
举个例子:
汉字"𠮷"的 Unicode 码点为 0x20BB7,该码点显然超出了基本平面的范围(0x0000 - 0xFFFF),因此需要使用四个字节表示。首先用 0x20BB7 - 0x10000 计算出超出的部分,然后将其用 20 个二进制位表示(不足前面补 0 ),结果为0001000010 1110110111。接着,将前 10 位映射到 U+D800 到 U+DBFF 之间,后 10 位映射到 U+DC00 到 U+DFFF 即可。U+D800 对应的二进制数为 1101100000000000,直接填充后面的 10 个二进制位即可,得到 1101100001000010,转成 16 进制数则为 0xD842。同理可得,低位为 0xDFB7。因此得出汉字"𠮷"的 UTF-16 编码为 0xD842 0xDFB7。
Unicode3.0 中给出了辅助平面字符的转换公式:
H = Math.floor((c-0x10000) / 0x400)+0xD800
L = (c - 0x10000) % 0x400 + 0xDC00
5、codePoint
unicode的范围从000000 -10FFFF,char的范围只能是在u0000-uffff,也就是标准的 2 字节形式通常称作 UCS-2,在Java中,char类型用UTF-16编码描述一个代码单元,但unicode大于0x10000的部分如何用char表示呢,比如一些emoji:😀
java的char类型占两个字节,想要表示😀这个表情就需要2个char,看如下代码
String testCode = "ab\uD83D\uDE03cd";
int length = testCode.length();
int count = testCode.codePointCount(0, testCode.length());
//length=6
//count=5
第三个和第四个字符合起来代表😀,是一个代码点, 如果我们想取到每个代码点做一些判断可以这么写
String testCode = "ab\uD83D\uDE03cd";
int cpCount = testCode.codePointCount(0, testCode.length());
for(int index = 0; index < cpCount; ++index) {
//这里的i是字符的位置
int i = testCode.offsetByCodePoints(0, index);
int codepoint = testCode.codePointAt(i);
}
//输出
i:0 index: 0 codePoint: 97
i:1 index: 1 codePoint: 98
i:2 index: 2 codePoint: 128515
i:4 index: 3 codePoint: 99
i:5 index: 4 codePoint: 100
也就是按照codePointindex取字符,0取到a,1取到b,2取到\uD83D\uDE03也就是😀,3取到c,4取到d; 按照String的index取字符,0取到a,1取到b,2取到\uD83D,3取到\uDE03,4取到c,5取到d。 这就是codePointIndex和char的index的区别。
取到codePoint就可以按照unicode值进行字符的过滤等操作。
如果有个需求是既可以按照unicode值过滤字符,也能按照正则表达式过滤字符,并且还有白名单,应该如何实现呢。
其实unicode过滤和正则表达式过滤并不冲突,自己实现自己的过滤就好了,如果需求加入了过滤白名单就会复杂一些,不能直接过滤,需要先检验是否是白名单的index。
我的思路是记录白名单char的index,正则表达式或其他过滤方式可以获得违规char的index,unicode黑名单的codepointIndex可以转换成char的index,在获取codePont的index时可以判断当前字符是单char字符还是双char字符,双char字符需要添加2个下标,方法如下
//取到unicode值
int codepoint = testCode.codePointAt(i);
//将unicode值转换成char数组
char[] chars = Character.toChars(codepoint);
charIndexs.add(pointIndex);
if (chars.length > 1) {
//表示不是单char字符,记录index时同时添加i+1
charIndexs.add(pointIndex + 1);
}
String str = "ab\uD83D\uDE03汉字"; 想处理emoji,那记录的下标就是2、3,最后和白名单下标比较后统一删除
如何区别char是一对还是单个 就之前的例子ab\uD83D\uDE03cd,换种写法\u0061\u0062\uD83D\uDE0\u0063\u0064 程序是如何将\uD83D\uDE03解析成一个字符的呢。这就需要Surrogate这个概念,来自UTF-16。
UTF-16是16bit最多编码65536,那大于65536如何编码?Unicode 标准制定组想出的办法是,从这65536个编码里,拿出2048个,规定他们是「Surrogates」,让他们两个为一组,来代表编号大于65536的那些字符。 编号为 U+D800 至 U+DBFF 的规定为「High Surrogates」,共1024个。 编号为 U+DC00 至 U+DFFF 的规定为「Low Surrogates」,也是1024个。 他们组合出现,就又可以多表示1048576中字符。
看一下String.codePointAt这个方法,
static int codePointAtImpl(char[] a, int index, int limit) {
char c1 = a[index];
if (isHighSurrogate(c1) && ++index < limit) {
char c2 = a[index];
if (isLowSurrogate(c2)) {
return toCodePoint(c1, c2);
}
}
return c1;
}
其中有两个方法isHighSurrogate、isLowSurrogate。 第一个方法判断是否为高代理项代码单元,即在'\uD800'与'\uDBFF'之间, 第二个方法判断是否为低代理项代码单元,即在'\uDC00'与'\uDFFF'之间。
codePointAtImpl方法判断当前char是高代理项代码单元,下一个是低代理项代码单元,则这两个char是一个codepoint。
6、实际用法:
int[] nextEmoji() {
while (start < str.length()) {
int cp = str.codePointAt(start);
int cc = Character.charCount(cp);
for (int[] e : emojiArray) {
if (e[0] == cp) {// found
start += cc;
return new int[]{e[1], start - cc, start};
}
}
start += cc;
}
return null;
}
项目中是字符串中的部分标准unicode编码的字符,替换成指定的Drawable,剩余的工作便是,利用ImageSpan做表情的替换。
