

前言
面经
Q1、请按自己的理解简述http 2与http 1.0、http 1.1的区别
HTTP1.0:浏览器与web服务器的连接过程是短暂的,每次连接只处理一个请求和响应,客户端与web服务器建立连接后,只能获得一个web资源。
HTTP1.1:在一个tcp连接上可以传送多个http请求和响应,多个请求和响应过程可以重叠进行,增加了更多的请求头和响应头;允许客户端与web服务器建立连接后,在一个连接上获取多个web资源。HTTP/1.1 中增加了持久连接的方法,它的特点是在一个 TCP 连接上可以传输多个 HTTP 请求,只要浏览器或者服务器没有明确断开连接,那么该 TCP 连接会一直保持。
关于HTTP2,因为浏览器会有并发请求限制,在 HTTP / 1.1 时代,每个请求都需要建立和断开, 消耗了好几个 RTT 时间,并且由于 TCP 慢启动的原因,加载体积大的文件会需要更多 的时间。 在 HTTP / 2.0 中引入了多路复用,能够让多个请求使用同一个 TCP 链接,极大 的加快了网页的加载速度。并且还支持 Header 压缩,进一步的减少了请求的数据大小。
Q2、除了 Etag,还有哪些缓存手段,哪些是 HTTP1.0 的?
Expires、Cache-Control、Last-Modified、Etag这是前端缓存常用4种手段。 Expires首部主要是针对HTTP
1.0版本,是响应头里的一个头部,是以日期时间的形式返回给客户端,指示可以缓存这个资源(响应实体)直到指定的日期时间。
Cache-Control首部是在HTTP 1.1版本以后加入的,提供了细粒度的缓存策略。
Last-Modified 在HTTP1.0推出的,指服务器文件的最后修改时间,浏览器会带上If-Modified-Since向服务器发送请求,与服务器文件修改时间Last-Modified做对比,如果时间不同,则获取数据返回200,否则返回304后调用浏览器本地硬盘的缓存。
ETag 类似于文件指纹,在HTTP1.1推出,该版本号是由服务端随机生成的,浏览器会带上If-None-Match向服务器发送请求,与服务器文件修改版本ETag做对比,如果版本号不同,则获取数据返回200,否则返回304后调用浏览器本地硬盘的缓存,这种方式比Last-Modified靠谱。
Q3、常用检测数据的方法有哪些,为什么typeof null 输出object,如何正确输出Null的类型?
instanceof 可以正确的判断对象的类型,因为内部机制是通过判断对象的原型链 中是不是能找到类型的 prototype。此外还有typeof。 typeof null 输出object是因为在JS 的最初版本中,使用的是32位系统。为了性能考虑使用低位存储了变量的类型信息,000开头代表是对象,然而null 表示为全零,所以将它错误的判断为object。 如果我们想获得一个变量的正确类型,可以通过0bject. prototype. toString.call(xx)。这样我们就可以获得类似[object Type]的字符串。
Q4、如何解决js编译速度太慢的问题?
将编译产物缓存并提供随机访问。首先,把安全相关的js文件从静态服务中剥离出来,由一个后端的webserver输出js内容。该server上维护着一个长度一定的数组,构建工具编译好一个js文件后,将该文件的内容发送给web server,web server将接收到的内容顺序填充到数组中;当有用户页面时,浏览器向web server请求该js内容,web server从数组中随机挑选一个,返回给浏览器。除了可以保证安全js的随机性,还能将signature的生成放到web server中完成。构建工具在编译js时将编译的元信息发送给web server,此时并不生成出signature。用户需要请求该js时再根据元信息实时生成一个signature,填充到js文件内容中。这样生成的signature每次都是独立的,通过检测signature的使用次数,可以很容易标识并拦截重放的请求。
Q5、作为前端,你是如何处理前端动态化代码保护的
代码安全,一般是指前端JavaScript代码的安全。通常,如果一段JavaScript代码只能在正常的浏览器中运行,无法或尚未在非正常浏览器的运行环境执行得到结果、无法被等价翻译成其他编程语言的代码,则认为这段代码是安全的。前端代码保护主要一个是以语法树变换为基础的混淆保护,另一个是以构建私有执行环境为思路的虚拟机保护,谷歌则属于后者。代码混淆的效果因混淆器的负责程度而不同,基础级别的混淆器混淆出来的代码也很容易被逆向,而虚拟机保护的抗逆向效果好,其原理是在JS的执行环境之上再设计构建一个虚拟机,所有原有业务逻辑的JS代码均转换为该虚拟机可识别的字节码,这样复杂度较高效果好。
Q6、如何权衡页面性能?
前端页面性能一直是前端同学绕不开的话题,关于页面性能,一种通用而有效的性能优化方式是合理地为页面中的资源文件设置缓存。通常对于一个模块化良好且使用成熟打包工具打包的项目,入口html的缓存策略会被配置为Cache-Control: no-cache,而js/css/image等资源文件会设置一个比较长的缓存时间。但负责数据保护的js文件如果含有动态生成的逻辑,该js文件将不能再使用缓存,否则一旦缓存时间控制不当,将会引发各类数据解密失败的问题。在考虑前端安全的前提下,将数据保护相关的逻辑从整个工程的JavaScript代码中剥离出来,直接inline编译到html页面中,或者编译到一个独立的js文件中,为该js文件单独设置Cache-Control:no-cache的response头部。该js与其他js之间可以使用全局变量、postMessage等方式通信。
Q7、手写一个常用混淆方法?
function foo(x) {
x = String.fromCharCode.apply(null, x.split('').map(i => i.charCodeAt(0) + 23); return btoa(x)
}function bar(y) {
y = String.fromCharCode.apply(null, y.split('').reverse().map(i => i.charCodeAt(0) + 13); return btoa(y);
}
Q8、两个浏览器标签页如何实现通信?
对于同源页面,常见的方式包括: 广播模式:Broadcast Channe / Service Worker / LocalStorage + StorageEvent共享存储模式:Shared Worker / IndexedDB / cookie口口相传模式:window.open + window.opener基于服务端:Websocket / Comet / SSE 等。
而对于非同源页面,则可以通过嵌入同源 iframe 作为“桥”,将非同源页面通信转换为同源页面
Q9、什么是进程、线程;浏览器为什么有时会因为单个页面卡死最终崩溃导致所有页面崩溃的情况?
虽然现在的谷歌浏览器是多进程浏览器架构,但是Chrome的默认策略是,每个标签对应一个渲染进程。但是如果从一个页面打开了新页面,而新页面和当前页面属于同一站点时,那么新页面会复用父页面的渲染进程。官方把这个默认策略叫process-per-site-instance。简单来说如果几个页面符合同一站点,那么他们将被分配到一个渲染进程里面去,这种情况下,一个页面崩溃了,会导致同一站点的页面同时崩溃,因为他们使用了同一个渲染进程。
Q10、什么是XSS,如何避免XSS攻击?
XSS解释略。1.利用模板引擎 2.避免内联事件 3.避免拼接 HTML 4.通过 CSP、输入长度配置、接口安全措施等方法,增加攻击的难度,降低攻击的后果 5.可使用 XSS 攻击字符串和自动扫描工具寻找潜在的 XSS 漏洞
Q11、CSRF了解多少,针对web安全,如果让你负责指定一个转义库,你需要考虑哪些规则?
针对CSRF,需要至少从3个方面去考虑。CSRF自动防御策略:同源检测(Origin 和 Referer 验证); CSRF主动防御措施:Token验证 或者 双重Cookie验证 以及配合Samesite Cookie; 保证页面的幂等性,后端接口不要在GET页面中做用户操作。 针对转义库,至少需要考虑HTML 属性、HTML 文字内容、HTML 注释、跳转链接、内联 JavaScript 字符串、内联 CSS 样式表等等
Q12、浏览器的宏任务、微任务分别有哪些,执行顺序是什么?
微任务和宏任务是绑定的,每个宏任务在执行时,会创建自己的微任务队列。 微任务的执行时长会影响到当前宏任务的时长。比如一个宏任务在执行过程中,产生了 100 个微任务,执行每个微任务的时间是 10 毫秒,那么执行这 100 个微任务的时间就是 1000 毫秒,也可以说这 100 个微任务让宏任务的执行时间延长了 1000 毫秒。所以你在写代码的时候一定要注意控制微任务的执行时长。 在一个宏任务中,分别创建一个用于回调的宏任务和微任务,无论什么情况下,微任务都早于宏任务执行。
微任务包括 process.nextTick ,promise ,Object.observe ,MutationObserver。宏任务包括 script , setTimeout ,setInterval ,setImmediate ,I/O ,UI rendering。 1. 执行同步代码,这属于宏任务 2. 执行栈为空,查询是否有微任务需要执行 3. 执行所有微任务 4. 必要的话渲染 UI 5. 然后开始下一轮 Event loop,执行宏任务中的异步代码
Q13、谈一下V8 下的垃圾回收机制?
V8 实现了准确式 GC,GC 算法采用了分代式垃圾回收机制。新生代中的对象一般存活时间较短,使用 Scavenge GC 算法。 在新生代空间中,内存空间分为两部分,分别为 From 空间和 To 空间。在这两 个空间中,必定有一个空间是使用的,另一个空间是空闲的。新分配的对象会被放入 From 空间中,当 From 空间被占满时,新生代 GC 就会启动了。算法会检查 From 空 间中存活的对象并复制到 To 空间中,如果有失活的对象就会销毁。当复制完成后将 From 空间和 To 空间互换,这样 GC 就结束了。
Q14、在V8GC的老生代中,哪些情况会先启动标记清除算法?
某一个空间没有分块的时候、空间中被对象超过一定限制、 空间不能保证新生代中的对象移动到老生代中。并且新生区和老生区标记过程是同一个过程,之后新生代把存活的数据移动到空闲区,老生代把死去的对象加到空闲列表中。
Q15、js是基于寄存器的,V8是基于栈的,能不能说一下这两者有什么一样吗?
解析器是parser,而解释器是interpreter。之所以存在编译器和解释器,是因为机器不能直接理解我们所写的代码,所以在执行程序之前,需要将我们所写的代码“翻译”成机器能读懂的机器语言。按语言的执行流程,可以把语言划分为编译型语言和解释型语言。 JavaScriptCore从SquirrelFish版开始是“基于寄存器”的,V8则不适合用“基于栈”或者“基于寄存器”的说法来描述。很多资料会说,Python、Ruby、JavaScript都是“解释型语言”,是通过解释器来实现的。这么说其实很容易引起误解:语言一般只会定义其抽象语义,而不会强制性要求采用某种实现方式。 例如说C一般被认为是“编译型语言”,但C的解释器也是存在的,例如Ch。同样,C++也有解释器版本的实现,例如Cint。 一般被称为“解释型语言”的是主流实现为解释器的语言,但并不是说它就无法编译。例如说经常被认为是“解释型语言”的Scheme就有好几种编译器实现,其中率先支持R6RS规范的大部分内容的是Ikarus,支持在x86上编译Scheme;它最终不是生成某种虚拟机的字节码,而是直接生成x86机器码。实际上很多解释器内部是以“编译器+虚拟机”的方式来实现的,先通过编译器将源码转换为AST或者字节码,然后由虚拟机去完成实际的执行。所谓“解释型语言”并不是不用编译,而只是不需要用户显式去使用编译器得到可执行代码而已。
V8是可以直接编译JavaScript生成机器码,而不通过中间的字节码的中间表示的JavaScript引擎,它内部有虚拟寄存器的概念,但那只是普通native编译器的正常组成部分。我觉得也不应该用“基于栈”或“基于寄存器”去描述它。 V8在内部也用了“求值栈”(在V8里具体叫“表达式栈”)的概念来简化生成代码的过程,在编译过程中进行“抽象解释”,使用所谓“虚拟栈帧”来记录局部变量与求值栈的状态;但在真正生成代码的时候会做窥孔优化,消除冗余的push/pop,将许多对求值栈的操作转变为对寄存器的操作,以此提高代码质量。于是最终生成出来的代码看起来就不像是基于栈的代码了。
至于面试官所说的基于栈与基于寄存器的架构,谁更快?看看现在的实际处理器,大多都是基于寄存器的架构,从侧面反映出它比基于栈的架构更优秀。
而对于VM来说,源架构的求值栈或者寄存器都可能是用实际机器的内存来模拟的,所以性能特性与实际硬件又有点不同。一般认为基于寄存器的架构对VM来说也是更快的,原因是:虽然零地址指令更紧凑,但完成操作需要更多的load/store指令,也意味着更多的指令分派(instruction dispatch)次数与内存访问次数;访问内存是执行速度的一个重要瓶颈,二地址或三地址指令虽然每条指令占的空间较多,但总体来说可以用更少的指令完成操作,指令分派与内存访问次数都较少。
Q16、在平常工作种,你是如何判断 JavaScript 中内存泄漏的?
1. 一般是感官上的长时间运行页面卡顿,猜可能会有内存泄漏。通过DynaTrace(IE)profiles等工具一段时间收集数据,观察对象的使用情况。然后判断是否存在内存泄漏。 2. 工作中避免内存泄漏方法:确定不使用的临时变量置为null,当前es6普及场景下少使用闭包也是一种方法。
Q17、如何理解JS是单线程的?
整个JS代码是执行在一条线程里的,它并不像我们使用的OC、Java等语言,在自己的执行环境里就能申请多条线程去处理一些耗时任务来防止阻塞主线程。JS代码本身并不存在多线程处理任务的能力。但是为什么JS也存在多线程异步呢?强大的事件驱动机制,是让JS也可以进行多线程处理的关键。
Q18、你认为安全沙箱能防止 XSS 或者 CSRF一类的攻击的吗?为什么?
将渲染进程和操作系统隔离的这道墙就是我们要聊的安全沙箱。安全沙箱是不能防止 XSS 或者 CSRF 一类的攻击, 安全沙箱的目的是隔离渲染进程和操作系统,让渲染进行没有访问操作系统的权利 XSS 或者 CSRF 主要是利用网络资源获取用户的信息,这和操作系统没有关系的。
Q19、instanceof 是如何判断对象的类型的?手写一个instanceof方法
instanceof 可以正确的判断对象的类型,因为内部机制是通过判断对象的原型链 中是不是能找到类型的 prototype。
function instanceof(left, right) {
// 获得类型的原型
let prototype = right.prototype
// 获得对象的原型
left = left.__proto__
// 判断对象的类型是否等于类型的原型
while (true) {
if (left === null)
return false
if (prototype === left)
return true
left = left.__proto__
}
}
Q20、谈一谈vue的数据劫持?手写一个简易的数据劫持。
简单来说数据劫持就是利用Object.defineProperty()来劫持对象属性的setter和getter操作。vue2利用Object.defineProperty来劫持data数据的getter和setter操作。这使得data在被访问或赋值时,动态更新绑定的template模块。Vue采用了Proxy,Proxy不需要各种hack技术就可以无压力监听数组变化;甚至有比hack更强大的功能——自动检测length。
let onWatch = (obj, setBind, getLogger) => {
let handler = {
get(target, property, receiver) {
getLogger(target, property)
return Reflect.get(target, property, receiver);
},
set(target, property, value, receiver) {
setBind(value);
return Reflect.set(target, property, value);
}
};
return new Proxy(obj, handler);
};
let obj = { a: 1 }
let value let p = onWatch(obj, (v) => {
value = v
}, (target, property) => {
console.log(`Get '${property}' = ${target[property]}`);
})
Q21、Service Worker是什么,平常用过吗?
Service workers 本质上充当 Web 应用程序与浏览器之间的代理服务器,也可以在 网络可用时作为浏览器和网络间的代理。它们旨在(除其他之外)使得能够创建有效的 离线体验,拦截网络请求并基于网络是否可用以及更新的资源是否驻留在服务器上来采 取适当的动作。他们还允许访问推送通知和后台同步 API。 Service workers可以用来做缓存文件,提高首屏速度
Q22、如何理解 Redux 异步流中间件,它是干什么的?
Redux核心理念很清晰明了,单一数据源,不可变数据源(单一)state以及纯函数修改state。它的主要流程就是:旧Store -> 用户触发action(from view) -> reducer -> 新State -> view。Redux有一个全局仓库store来保存整个应用程序的state,并且修改store的唯一方式就是通过用户触发action 然后dispatch出去(action), dispatch 函数内部会调用 reducer 并且返回创建一个全新的state(并且销毁旧的state)来更新我们的store。当store发生更新,view就会触发render函数进行更新。
不过Redux本身只能处理同步事件,Redux 作者(@dan_abramov)将异步流的处理通过提供中间件的方式让开发者自行选择,常用的异步流中间件有redux-thunk,还有redux-saga。
Q23、redux-thunk 中间件的作用是什么,平常使用需要注意哪些地方?
中间件 redux-thunk 中间件,它的机制主要通过判断 action 是否为一个函数(内部返回一个promise)。如果是则会立即调用,action 在函数内部可以进行异步流处理(本质还是同步),然后继续通过dispatch(action)进行同步数据的处理;如果不是函数,则通过next(action)调用下一个中间件或者是进入reducer。redux-thunk的核心思想是扩展action,使得action从一个对象变成一个函数。redux-thunk处理异步便捷,配合asyvc/await更可以使得action同步化。不过redux-thunk中action会因此变的复杂,后期可维护性下降;同时若多人协作,当自己的action调用了别人的action,别人action发生改动,则需要自己主动修改。
// 简化后的核心部分
function createThunkMiddleware(extraArgument) {
return ({ dispatch, getState }) => next => action => {
if (typeof action === 'function') {
return action(dispatch, getState, extraArgument);
}
return next(action);
};
}
const thunk = createThunkMiddleware();
thunk.withExtraArgument = createThunkMiddleware;
export default thunk;
Q24、Redux-saga中间件是用来做什么的?
Redux-saga是一个用于管理redux应用异步操作的中间件之一,redux-saga通过创建sagas将所有异步操作逻辑收集在一个地方集中处理,可以用来代替redux-thunk中间件。Redux-saga相对于其他异步流中间件,将异步处理单独放在一起,不需要修改action,action还是同步。同时redux-saga的异步控制流程也很强大,比如对于竞态的处理就通过takeLatest()来处理。 redux-saga 是一个用于管理应用程序 Side Effect(副作用,例如异步获取数据,访问浏览器缓存等)的 library,它的目标是让副作用管理更容易,执行更高效,测试更简单,在处理故障时更容易。可以想像为,一个 saga 就像是应用程序中一个单独的线程,它独自负责处理副作用。 redux-saga 是一个 redux 中间件,意味着这个线程可以通过正常的 redux action 从主应用程序启动,暂停和取消,它能访问完整的 redux state,也可以 dispatch redux action。
Q25、redux是如何进行数据更新的?
redux不可以像jquery一样直接更改组件的数据,如果我们要更新某个节点上的值,首先要产生一个完全全新的对象,比如图中的节点,在路径上所有的对象都处理更新过的状态,其他节点没有更新变化,由上至下,逐层比较。react节点的数据是不能直接修改的,若想修改就必须先进行复制,无论是浅复制还是深复制,然后去包含你要修改的部分。
Q26、React redux为何需要不可变数据?
为了性能优化。因为当一个store发生变化,我们需要通知所有的组件需要更新了。所有的变化都是由action触发,触发在原来旧的state上,形成一个新的state,新旧state是两个完全不同的对象,所以当新旧state不是同一个对象的时候,我们就知道store发生了变化,我们不需要比较它其中的值是否发生变化,我们只需要比较两个引用的状态是不是一样即可,这样就可以达到一个性能优化的目的。
同时也表明了redux中的store都是不可变数据,每个节点都是不可变数据。这样当一个组件绑定在一个节点上,这样我只要判断一个组件前后的引用状态是否相等,就可以知道当前的store有没有变,从而决定是否要更新你的组件,省去了深层次的遍历每个值是否相等,只比较引用即可。同时便于调试和跟踪
Q27、用户在浏览器URL输入并回车后,浏览器是如何渲染的?
①.处理 HTML 并构建 DOM 树;②.处理 CSS 构建 CSSOM 树;③.将 DOM 与 CSSOM 合并成一个渲染树;④.根据渲染树来布局,计算每个节点的位置;⑤.调用 GPU 绘制,合成图层,再经过布局与具体WebKit Ports的渲染接口,把渲染树渲染输出到屏幕上,成为了最终呈现在用户面前的Web页面。
Q28、什么是防抖与节流,手写一个简易的函数防抖?
防抖:把触发非常频繁的事件(比如按键)合并成一次执行;节流:保证每 X 毫秒恒定的执行次数,间断执行。函数防抖,在一段连续操作结束后,处理回调,利用 clearTimeout 和 setTimeout 实现;函数节流,在一段连续操作中,每一段时间只执行一次,频率较高的事件中使用来提高性能。函数防抖关注一定时间连续触发,只在最后执行一次,而函数节流侧重于一段时间内只执行一次。
_.debounce = function(func, wait, immediate) {
var timeout, args, context, timestamp, result;
var later = function() {
// 据上一次触发时间间隔
var last = _.now() - timestamp;
// 上次被包装函数被调用时间间隔last小于设定时间间隔wait
if (last < wait && last > 0) {
timeout = setTimeout(later, wait - last);
} else {
timeout = null;
// 如果设定为immediate===true,因为开始边界已经调用过了此处无需调用
if (!immediate) {
result = func.apply(context, args);
if (!timeout) context = args = null;
}
}
};
return function() {
context = this;
args = arguments;
timestamp = _.now();
var callNow = immediate && !timeout;
// 如果延时不存在,重新设定延时
if (!timeout) timeout = setTimeout(later, wait);
if (callNow) {
result = func.apply(context, args);
context = args = null;
}
return result;
};
};
Q29、函数柯里化的面试题,实现add(1)(2)(3) = 6; add(1, 2, 3)(4) = 10?
柯里化(Currying),又译为卡瑞化或加里化,是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术。
function add(){
var args = [].slice.call(arguments);
var fn = function(){
var newArgs = args.concat([].slice.call(arguments));
return add.apply(null,newArgs);
}
fn.toString = function(){
return args.reduce(function(a, b) {
return a + b;
})
}
return fn ;
}
// 可以接受任意个数的参数
add(1)(2,3) //6
add(1)(2)(3)(4)(5) //15
Q30、CommonJS 和 ES6 中的模块化的两者区别有哪些?
前者支持动态导入,也就是 require(${path}/xx.js),后者目前不支持,但是 已有提案;
前者是同步导入,因为用于服务端,文件都在本地,同步导入即使卡住主线程 影响也不大。而后者是异步导入,因为用于浏览器,需要下载文件,如果也采 用导入会对渲染有很大影响;
前者在导出时都是值拷贝,就算导出的值变了,导入的值也不会改变,所以如 果想更新值,必须重新导入一次。但是后者采用实时绑定的方式,导入导出的 值都指向同一个内存地址,所以导入值会跟随导出值变化;
后者会编译成 require/exports 来执行的;
Q31、谈一谈MVVM模式?
MVVM 由以下三个内容组成
View:界面;
Model:数据模型;
ViewModel:作为桥梁负责沟通 View 和 Model;
在 JQuery 时期,如果需要刷新 UI 时,需要先取到对应的 DOM 再更新 UI,这样数据和业务的逻辑就和页面有强耦合。在 MVVM 中,UI 是通过数据驱动的,数据一旦改变就会相应的刷新对应的 UI,UI如果改变,也会改变对应的数据。这种方式就可以在业务处理中只关心数据的流转,而无需直接和页面打交道。ViewModel 只关心数据和业务的处理,不关心 View 如何处理数据,在这种情况下,View 和 Model 都可以独立出来,任何一方改变了也不一定需要改变另一方,并且可以将一些可复用的逻辑放在一个 ViewModel 中,让多个 View 复用这个 ViewModel。在 MVVM 中,最核心的也就是数据双向绑定,例如 Angluar 的脏数据检测,Vue中的数据劫持。
Q32、你在负责H5页游、H5活动营销页开发的时候是如何设计和管理页面的?
在开发H5营销页的时候,可以使用引擎Egret,也可以使用canavs,或者帧动画、瓦片地图等等。在一些复杂or附带角色场景的页面,这些场景肯定有进入场景、退出场景、再次进入场景、退出场景、清理场景、更新场景的基本功能,大多游戏基本都是这样,场景有了,这个时候就需要手动创建一个管理器用于保障场景的复用性。
比较保守的做法就是,场景归场景管、UI归UI管,场景切换有管理类、UI应该也需要做一个LRU策略,在这里,UI需要根据使用频率来进行清理,比如15分钟一次都没用到,我们就可以认为该UI资源使用不频繁,这样我们就可以干掉图集和内存,这里只需要设置一个计时器,每次打开的时候记录上时间,并且我只针对关闭的面板遍历,因为已经打开的面板根本不需要去清理,亦不需要去检测,UI资源中最占内存的还是图集,如果可以清理掉低频使用的图集就可以剩下很多内存,减少游戏整体内存压力,而且大型游戏UI资源占游戏体积是最大的。
我们平常使用的H5游戏引擎,底层默认的操作是只要关闭UI就自动清理,这样会造成CPU发热上升,虽然这样积极地清理内存,但是用户体验就下降了。所以,我们在这里创建的UI管理器,不需要管理UI的释放,只需要给出一个UI面板名,负责调用管理器的开、关就好。
至于UI的释放,可以设计一个机制,除了当前场景,已启用的UI资源15分钟内没有再次启用就自动释放(有点模仿GC的感觉)。这里的15分钟计数器检测的是关闭面板的使用次数,面板打开一次就记一次使用次数,这里关闭的面板值得是曾开启的面板。在这里,我们不需要记录每个面板之前的开启次数、现在的开启次数,只需要在打开的时候递增次数,给出每个面板的总次数即可。15分钟检测的时候如果在你设定的频率,我们可以认为它使用的频繁,如果低于你设置的频率,就可以认为它是低频率使用的面板UI,15分钟后可以清理了。在以上的UI管理器设计思路中,最麻烦的是有些UI资源,它横跨几个面板,属于交叉复用资源,sceneMenu使用了sceneBoot里的资源sound,但是又来该面板的UI被清理掉了,玩家切换到sceneBoot的时候发现没有UI又要重新加载。
Q33、什么是MVP模式,MVVM 和 MVP 的关系?
这里的MVP,不是LOL里的全场最佳那个意思。View:对应于Activity,负责View的绘制以及与用户交互Model:依然是业务逻辑和实体模型Presenter:负责完成View与Model间的交互View不直接与Model交互,而是通过与Presenter交互来与Model间接交互。 Presenter与View的交互是通过接口来进行的。 而MVVM 模式是将 Presenter 改名为 ViewModel,基本上与 MVP 模式完全一致。唯一的区别是,它采用双向绑定(data-binding):View的变动,自动反映在 ViewModel,反之亦然。这样开发者就不用处理接收事件和View更新的工作,框架已经帮你做好了。
Q34、无论是小程序,还是vue都会经常遇到模板解析,手写一个简易的 htmlParse 解析器?
// 转化HTML至AST对象
function parse(template){
var currentParent; //当前父节点
var root; //最终生成的AST对象
var stack = []; //插入栈
var startStack = []; //开始标签栈
var endStack = []; //结束标签栈
//console.log(template);
parseHTML(template,{
start:function start(targetName,attrs,unary,start,end,type,text){//标签名 ,attrs,是否结束标签,文本开始位置,文本结束位置,type,文本,
var element = { //我们想要的对象
tag:targetName,
attrsList:attrs,
parent:currentParent, //需要记录父对象吧
type:type,
children:[]
}
if(!root){ //根节点哈
root = element;
}
if(currentParent && !unary){ //有父节点并且不是结束标签?
currentParent.children.push(element); //插入到父节点去
element.parent = currentParent; //记录父节点
}
if (!unary) { //不是结束标签?
if(type == 1){
currentParent = element;//不是结束标签,当前父节点就要切换到现在匹配到的这个开始标签哈,后面再匹配到
startStack.push(element); //推入开始标签栈
}
stack.push(element); //推入总栈
}else{
endStack.push(element); //推入结束标签栈
currentParent = startStack[endStack.length-1].parent; //结束啦吧当前父节点切到上一个开始标签,这能理解吧,当前这个已经结束啦
}
//console.log(stack,"currentstack")
},
end:function end(){
},
chars:function chars(){
}
});
console.log(root,"root");
return root;
};
// Regular Expressions for parsing tags and attributes
var singleAttrIdentifier = /([^\s"'<>/=]+)/;
var singleAttrAssign = /(?:=)/;
var singleAttrValues = [
// attr value double quotes
/"([^"]*)"+/.source,
// attr value, single quotes
/'([^']*)'+/.source,
// attr value, no quotes
/([^\s"'=<>`]+)/.source
];
var attribute = new RegExp(
'^\\s*' + singleAttrIdentifier.source +
'(?:\\s*(' + singleAttrAssign.source + ')' +
'\\s*(?:' + singleAttrValues.join('|') + '))?'
);
// could use https://www.w3.org/TR/1999/REC-xml-names-19990114/#NT-QName
// but for Vue templates we can enforce a simple charset
var ncname = '[a-zA-Z_][\\w\\-\\.]*';
var qnameCapture = '((?:' + ncname + '\\:)?' + ncname + ')';
var startTagOpen = new RegExp('^<' + qnameCapture);
var startTagClose = /^\s*(\/?)>/;
var endTag = new RegExp('^<\\/' + qnameCapture + '[^>]*>');
var doctype = /^<!DOCTYPE [^>]+>/i;
var comment = /^<!--/;
var conditionalComment = /^<!\[/;
//偷懒哈 上面的正则是我在vue上拿下来的,这个后期可以研究,下面的话简单的写两个用用,和vue原版的是有一些差别的
var varText = new RegExp('{{' + ncname + '}}');
//空格与换行符
var space = /^\s/;
var checline = /^[\r\n]/;
/**
type 1普通标签
type 2代码
type 3普通文本
*/
function parseHTML(html,options){
var stack = []; //内部也要有一个栈
var index = 0; //记录的是html当前找到那个索引啦
var last; //用来比对,当这些条件都走完后,如果last==html 说明匹配不到啦,结束while循环
var isUnaryTag = false;
while(html){
last = html;
var textEnd = html.indexOf('<');
if(textEnd === 0){ //这一步如果第一个字符是<那么就只有两种情况,1开始标签 2结束标签
//结束标签
var endTagMatch = html.match(endTag); //匹配
if(endTagMatch){
console.log(endTagMatch,"endTagMatch");
isUnaryTag = true;
var start = index;
advance(endTagMatch[0].length); //匹配完要删除匹配到的,并且更新index,给下一次匹配做工作
options.start(null,null,isUnaryTag,start,index,1);
continue;
}
//初始标签
var startMatch = parseStartTag();
if(startMatch){
parseStartHandler(startMatch);//封装处理下
console.log(stack,"startMatch");
continue;
}
}
if(html === last){
console.log(html,"html");
break;
}
}
function advance (n) {
index += n;
html = html.substring(n);
}
//处理起始标签 主要的作用是生成一个match 包含初始的attr标签
function parseStartTag(){
var start = html.match(startTagOpen);
if(start){
var match = {
tagName: start[1], // 标签名(div)
attrs: [], // 属性
start: index // 游标索引(初始为0)
};
advance(start[0].length);
var end, attr;
while (!(end = html.match(startTagClose)) && (attr = html.match(attribute))) {//在endClose之前寻找attribute
advance(attr[0].length);
match.attrs.push(attr);
}
if (end) {
advance(end[0].length); // 标记结束位置
match.end = index; //这里的index 是在 parseHTML就定义 在advance里面相加
return match // 返回匹配对象 起始位置 结束位置 tagName attrs
}
}
}
//对match进行二次处理,生成对象推入栈
function parseStartHandler(match){
var _attrs = new Array(match.attrs.length);
for(var i=0,len=_attrs.length;i<len;i++){ //这儿就是找attrs的代码哈
var args = match.attrs[i];
var value = args[3] || args[4] || args[5] || '';
_attrs[i] = {
name:args[1],
value:value
}
}
stack.push({tag: match.tagName,type:1, lowerCasedTag: match.tagName.toLowerCase(), attrs: _attrs}); //推栈
options.start(match.tagName, _attrs,false, match.start, match.end,1); //匹配开始标签结束啦。
}
}
Q35、什么是虚拟DOM,虚拟DOM与真实DOM的区别是什么?
虚拟 DOM 是同样操作 DOM,不过是把 DOM 树抽象成数据对象,Virtual Dom 它可以使我们操作这块的数据对象,用数据对象来呈现 DOM 树,在每次视图渲染的时候 patch 取得最优,这种做法使我们最小量地去修改 DOM,此外 Virtual DOM 还有一个很大的作用是简化 DOM 操作,让数据与 DOM 之间的关系更直观更简单。
虚拟DOM不会进行造成排版与重绘操作;
虚拟DOM进行频繁修改,然后一次性比较并修改真实DOM中需要改的部分(DIFF算法),最后并在真实DOM中进行排版与重绘,减少过多DOM节点排版与重绘损耗;
真实DOM频繁排版与重绘的效率是相当低的;
虚拟DOM有效降低大面积(真实DOM节点)的重绘与排版,因为最终与真实DOM比较差异,可以只渲染局部使用虚拟DOM的损耗计算。像JQuery这种是属于以选择器为导向的框架,Vue和React属于有明确分层架构的MV*框架,而虚拟DOM属于框架中的节点模块,也是核心模块,重中之重。
Q36、标准的Diff 算法复杂度是 O(n^3),FB团队做了什么操作得以将时间复杂度降到线性的有了解过吗?
①.两个相同组件产生类似的 DOM 结构,不同的组件产生不同的 DOM 结构;
②.对于同一层次的一组子节点,它们可以通过唯一的 id 进行区分。算法上的优化是 React 整个界面 Render 的基础,事实也证明这两个假设是合理而精确的,保证了整体界面构建的性能。
Q37、如何规避回流与重绘?
1.减少回流,避免频繁改动;2.避免逐条改变样式,使用类名去合并样式;3.常用优化小操作如下:
使用 translate 替代 top
使用 visibility 替换 display: none ,因为前者只会引起重绘,后者会引发回流(改变了布局)
把 DOM 离线后修改,比如:先把 DOM 给display:none (有一次 Reflow),然后你修改100次,然后再把它显示出来
不要把 DOM 结点的属性值放在一个循环里当成循环里的变量
不要使用 table 布局,可能很小的一个小改动会造成整个 table 的重新布局
动画实现的速度的选择,动画速度越快,回流次数越多,也可以选择使用requestAnimationFrame
CSS 选择符从右往左匹配查找,避免 DOM 深度过深
将频繁运行的动画变为图层,图层能够阻止该节点回流影响别的元素。比如对于 video 标签,浏览器会自动将该节点变为图层。
避免频繁读取会引发回流/重绘的属性,如果确实需要多次使用,就用一个变量缓存起来。
对具有复杂动画的元素使用绝对定位,使它脱离文档流,否则会引起父元素及后续元素频繁回流。
Q38、你这么喜欢造轮子,如何拓展和设计jQ?
首先,jQ是以选择器为导向的。
class jQuery {
constructor() {
const result = document.querySelectorAll(selector) const length = result.length
for (let i = 0; i < length; i++) {
this[i] = result[i]
}
this.length = length this.selector = selector
}
get(index) {
return this[index]
}
each(fn) {
for (let i = 0; i < this.length; i++) {
const elem = this[i] fn(elem)
}
}
on(type, fn) {
return this.each(elem => {
elem.addEventListener(type, fn, false)
})
}
style(data) {}
}
const $p = new jQuery('p') $p.get(1) $p.each((elem) => console.log(elem.nodeName))
Q39、React的Context两种方式childContectType、createContext,为什么前者后来被弃用了?
弃用的原因,就是中间哪些不需要这些数据的组件,也会因为接收到这些数据而去二次渲染
Q40、在webapp或混合开发中,让你优化性能和体验,你该怎么做?
①WebView初始化慢,可以在初始化同时先请求数据,让后端和网络不要闲着。
②后端处理慢,可以让服务器分trunk输出,在后端计算的同时前端也加载网络静态资源。③脚本执行慢,就让脚本在最后运行,不阻塞页面解析。
④同时,合理的预加载、预缓存可以让加载速度的瓶颈更小。
⑤WebView初始化慢,就随时初始化好一一个WebView待用。
⑥DNS和链接慢,想办法复用客户端使用的域名和链接。
⑦脚本执行慢,可以把框架代码拆分出来,在请求页面之前就执行好。
Q41、React中受控组件和非受控组件是什么?
React的核心组成之一就是能够维持内部状态的自治组件,不过当我们引入原生的HTMI.表单元素时
( input, select, textarea等),我们是否应该将所有的数据托管到React组件中还是将其仍然保留在DOM 元素中呢?这个问题的答案就是受控组件与非受控组件的定义分割。
受控组件(Controlled Component)代指那些交由React 控制并且所有的表单数据统一存放的组件。譬如下面这段代码中username变量值并没有存放到DOM元素中,而是存放在组件状态数据中。任何时候我们需要改变username变量值时,我们应当调用setState函数进行修改。
非受控组件(Uncontrol led Couponent )则是由DOM存放表单数据,并非存放在React 组件中。我们可以使用refs来操控DOM元素:
不过实际开发中我们并不提倡使用非受控组件,因为实际情况下我们需要更多的考虑表单验证、选择性的开启或者关闭按钮点击、强制输入格式等功能支持,而此时我们将数据托管到React中有助于我们更好地以声明式的方式完成这些功能。引入React 或者其他MWW框架最初的原因就是为了将我们从繁重的直接操作DOM中解放出来。
Q42、React中key的作用是什么?
Keys 是React用于追踪哪些列表中元素被修改、被添加或者被移除的辅助标识。
在开发过程中,我们需要保证某个元素的key 在其同级元素中具有唯-一性。 在React Diff算法中React 会借助元素的Key值来判断该元素是新近创建的还是被移动而来的元素,从而减少不必要的元素重渲染。此外,React还需要借助Key值来判断元素与本地状态的关联关系,因此我们绝不可忽视转换函数中Key的重要性。
Q43、看你做过flutter混合应用,说一下Flutter和原生代码的通信?
以网络请求为例可以在Dart中定义一个MethodChannel对象,然后在Java端实现相同名称的MethodChannel,在Flutter页面中注册后,调用post方法就可以调用对应的Java实现。
Q44、在小程序、APP里,针对WebView被运营商劫持、注入问题,你是如何处理的?
使用CSP拦截页面中的非白名单资源、使用HTTPS、让App将其转换为一个Socket请求,并代理WebView的访问、在内嵌的WebView中应该限制允许打开的WebView的域名,并设置运行访问的白名单。或者当用户打开外部链接前给用户强烈而明显的提示。
Q45、现在有个业务场景,在移动端广告业,我想实现一个小人 从顶部走到底部,走的是S曲线,或者是用户手指划过的路线,你将如何实现,你怎么保证它走的路线不会偏?
不会
Q46、现在有个场景,在淘宝APP广告页,有一个艺术字,福字,需要用户手描它,相似度非常高的情况(80%)下打开红包,用前端方法你将采用什么方式去实现,为什么算覆盖率,为什么算指定路径点,有什么区别,平常做过吗?
回答用覆盖率,具体实现方法不会。
Q47、针对大量echart数据、或者大量其他图标,你将如何优化?
瓦片地图
Q48、如果要你写一个混合app,你将如何技术选型,为什么选择flutter或者uniapp,理由是什么,你选择方案的依据是什么?
我选flutter,理由在下面。
Q49、Virtual DOM 真的比操作原生 DOM 快吗?
不一定,这是一个性能 vs. 可维护性的取舍。框架的意义在于为你掩盖底层的 DOM 操作,让你用更声明式的方式来描述你的目的,从而让你的代码更容易维护。没有任何框架可以比纯手动的优化 DOM 操作更快,因为框架的 DOM 操作层需要应对任何上层 API 可能产生的操作,它的实现必须是普适的。框架给你的保证是,你在不需要手动优化的情况下,我依然可以给你提供过得去的性能。
Q50、SameSite cookies有用过吗?
SameSite属性是cookie除了常用的path, domain, expire, HttpOnly, Secure的一个专门用于防止csrf漏洞的属性。在cookie上引入SameSite属性提供了三种不同的方法来控制CSRF漏洞。我们可以选择不指定属性,也可以使用Strict或Lax将cookie限制为同站点请求。1.设置SameSite = Strict,则表示您的cookie仅在第一方网站中发送使用;2.设置SameSite = Lax,当用户发送GET方法的同步请求时,将会发送cookie;3.当SameSite = None时,这意味着你可以在第三方环境中发送cookie。
前端方向
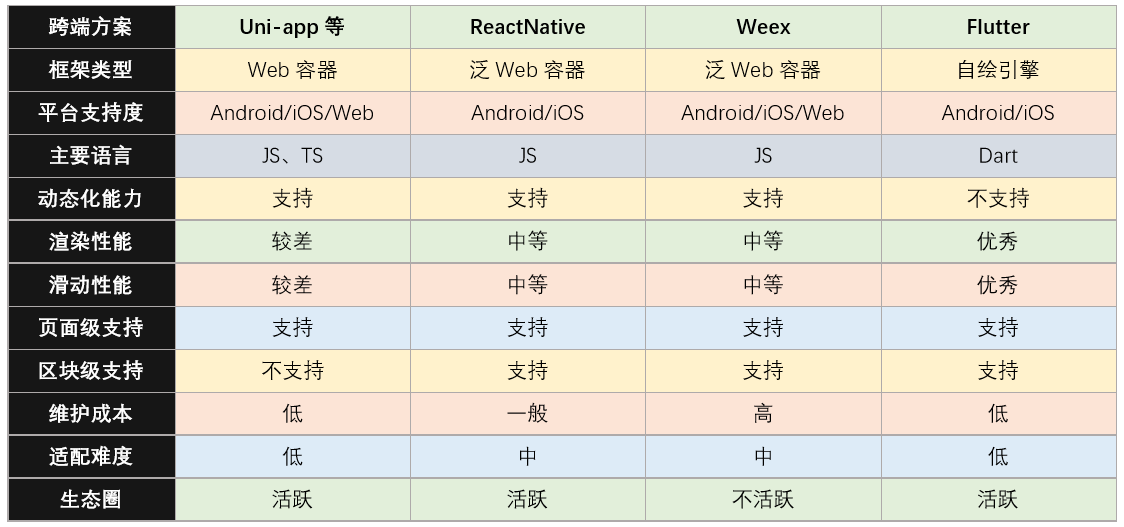
基于web容器即基于浏览器的跨平台也做得越来越好,自然管线也越来越短,与native的一些技术手段来实现性能上的相互补充。比如Egret、Cocos、Laya这些游戏引擎,它们在跨平台方面的做法多以Typescript编写,在iOS和安卓平台的各种浏览器中轻松的运行HTML5游戏,并在不同平台浏览器里提供近乎一致的用户体验,比如Egret还会提供高效的 JS-C Binding 编译机制,以满足游戏编译为原生格式的需求,不过大多数HTML游戏引擎(比如egret和laya)也属于web容器这个范畴内。web容器框架也有一个明显的致命(在对体验&性能有较高要求的情况下)的缺点,那就是WebView的渲染效率和JavaScript执行性能太差。再加上Android各个系统版本和设备厂商的定制,很难保证所在所有设备上都能提供一致的体验。 泛 Web 容器框架比如ReactNative和Weex,即上层通过面向前端友好的UI,下层通过native的渲染形式,虽然同样使用类HTML+JS的UI构建逻辑,但是最终会生成对应的自定义原生控件,以充分利用原生控件相对于WebView的较高的绘制效率,同时H5与native相互补充来达到更好的用户体验,这也是一种很好的解决方案。缺陷也很明显,随着系统版本变化和API的变化,开发者可能也需要处理不同平台的差异,甚至有些特性只能在部分平台上实现,这样框架的跨平台特性就会大打折扣。
自绘引擎框架这里专指Flutter框架,从底层就承担跨端的任务和渲染方式,就使用方面来看,就是写样式有点费劲,嵌套警告(根本原因是我菜)。
2020寒冬
小弟觉得,当下互联网就业环境并不是寒冬,只不过是更加理智,投资人再也不是拿张PPT随便说说就能搞到钱了,面试者再也不是背背面试题就能找到工作的,就业环境的严峻,提醒我们更加要注重自身能力的培养,而不是糊弄。更加注重自己的理论知识怎样能够为公司、产品带来更大的价值,曾有面试官这样问我,"你觉得公司招你来是做什么的,招你来是让你解决问题的",这同时也要求不仅仅要有足够的硬实力,从软实力方面来说,不仅要把事情做好,更要做好向上管理和向下管理。
大多数情况下,在面试过程中,面试官或者公司是主导方,节奏是跟着面试官走,但是我觉得面试其实就是一个相互探讨的过程,不仅是公司在选择你,你也在选择公司、以后工作的同事和leader。虽然我在面试蚂蚁金服的过程中失败了,但是我个人的面试风格就是,我会就是会说一堆,不会我就会说不会,我从来不会尝试搪塞、企图蒙混过关(在有些人看来可能有点傻),但是我就是我,我会就是会,我所能做的,顶多就是向面试官请教和探讨,尽可能尝试向面试官表达我的所知所学。所以我这次面试中,更多的是和面试官探讨,也会反问面试官一些问题,不仅仅是最后面试官说可以问他几个问题,在面试过程中就会询问一些,优秀的面试官会跟你探讨,并且讨论出一个合理的方案或者正确的答案,整个过程非常愉悦,比如,阿里的面试官们,面试官打开我的github针对里面的项目一个个询问,并鼓励我继续完善下去。
这次寒冬面试,学历、实力均受限,直接导致没有入职BAT TMD,不过最大的收获就是跟10+多位面试官的交流,再次更加让我认清我自己,认清自己的长处、短板和以后的规划,和对做人做事的看法,在这里真诚的感谢10多位面试官。
最后,我到底去了大公司、小公司还是外包,不便透露,我只是一个平凡的新手前端。对于一些同学对于求职去大公司还是小公司的咨询,我的态度是,在实力允许的情况下,建议本着"工作是为了更好的生活"这个宗旨去综合考虑,因为人生本就是一场不可重启的赌博。
