

前言
上周我刚把和小姐姐关于JVM的愉快探讨过程整理成文字发出来,就惨遭蛋哥的diss。
对了,还没看过上篇文章的小可爱请先移步这里: 那天我和小姐姐扯了半天的JVM
蛋哥:关于JVM小姐姐理解的挺不错的,为什么你不整理完整!
我:因为文章字数有限,浓缩的都是精华嘛~

蛋哥:懒就懒嘛,还把懒说的那么清新脱俗~(并扔给我一个白眼)
我:嘻嘻~那我再补充补充...
蛋哥没再搭理我,扔给我一个文件,就开始闷头写代码。
过了一会儿,微信上弹出蛋哥发的两行消息:看了你的文章之后我大致围绕以下几点进行了简单的补充:
- JVM内存区域的转变
- Java代码运行过程
- 运行时栈帧结构
- JVM堆内存分配方法
- JVM是如何对对象的访问进行定位的?
正文
JVM内存区域的转变
在上篇文章中我们知道,方法区主要存储类的相关信息,且被所有线程共享,采用永久代的方式实现了方法区。
不过方法区和永久代又有着本质的区别。方法区是JVM的规范,而永久代则是JVM规范的一种实现,并且只有HotSpot才有永久代,而对于其他类型的虚拟机,如 JRockit(Oracle)、J9(IBM) 并没有永久代一说。
本文我们主要以HotSpot为例展开探讨,我们先看一下jdk1.6及以前的JVM运行区域,如下图:
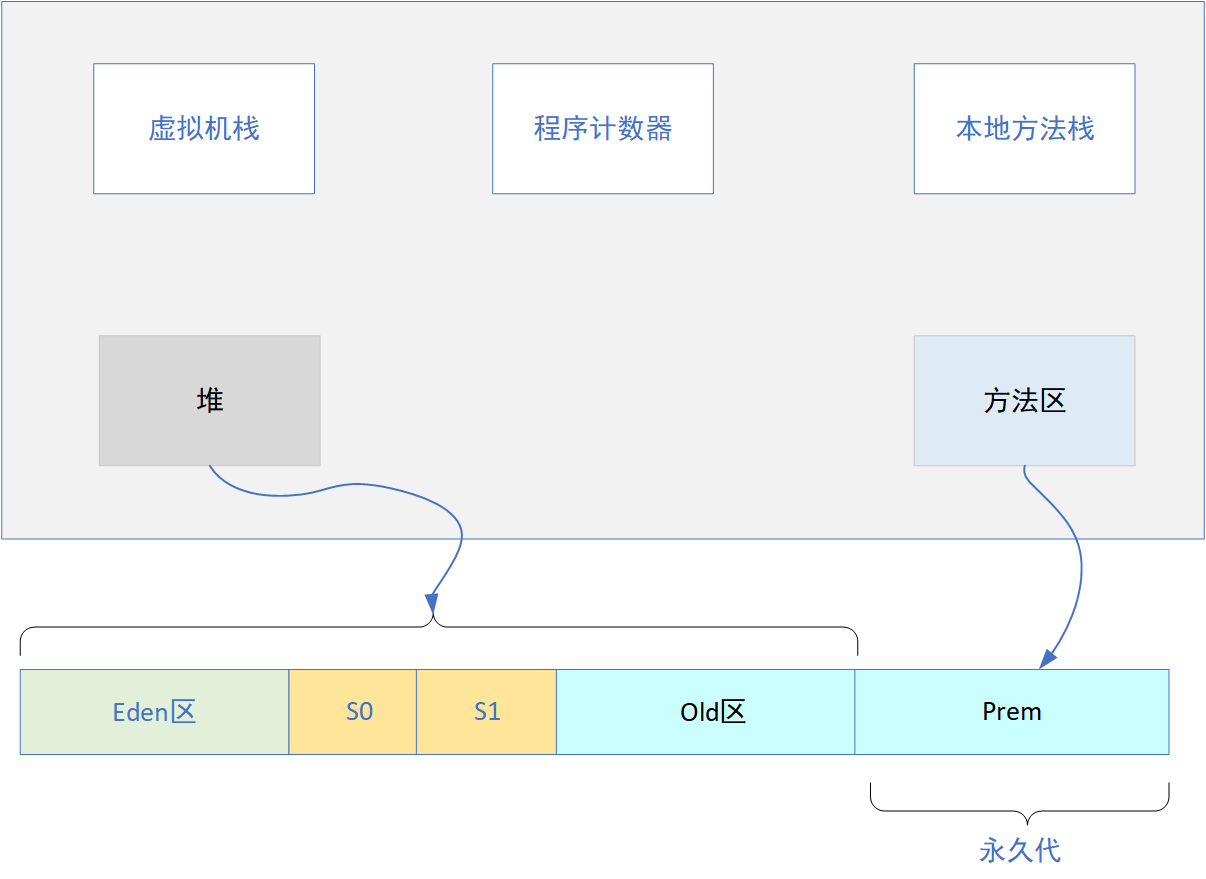
但在jdk1.8以后,永久代被移除,改为了元空间。具体演变过程是酱紫的:
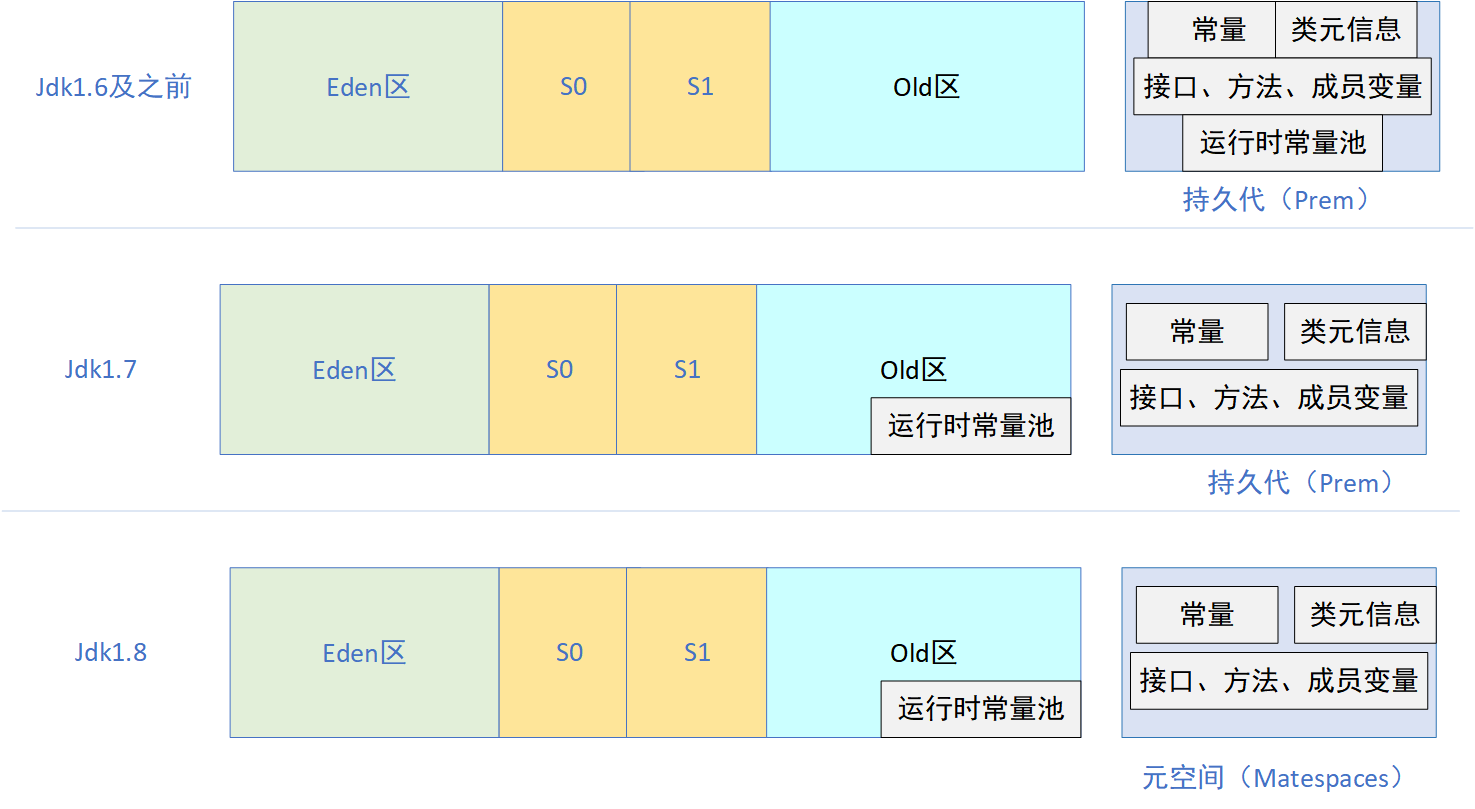
但是为什么在jdk1.8以后永久代被移除,改为了元空间呢?这样做有什么好处呢?
在讨论这个问题之前我们要先明白元空间这个概念:
元空间:简单来说就是存储类的元数据信息的一个空间区域,元空间并不在虚拟机中,而是使用本地内存。
那什么又是元数据呢?
元数据,关于数据的数据或者叫做用来描述数据的数据或者叫做信息的信息。
听起来是不是很抽象???

这么说吧,我们可以把元数据简单的理解成,最小的数据单位。元数据可以为数据说明其元素或属性,比如名称、大小、数据类型、等,或其结构像长度、字段、数据列之类,或其相关数据,位于何处、如何联系、拥有者等等。
明白了元空间和元数据这两个概念之后,那么我们就来说说他的好处。
本质上来讲,元空间和永久代类似,都是对JVM规范中方法区的实现。我们知道,类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出;而元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小不受JVM控制,也不会再进行GC了,它仅受本地内存的限制,因此不会出现OOM异常。
Java代码运行过程
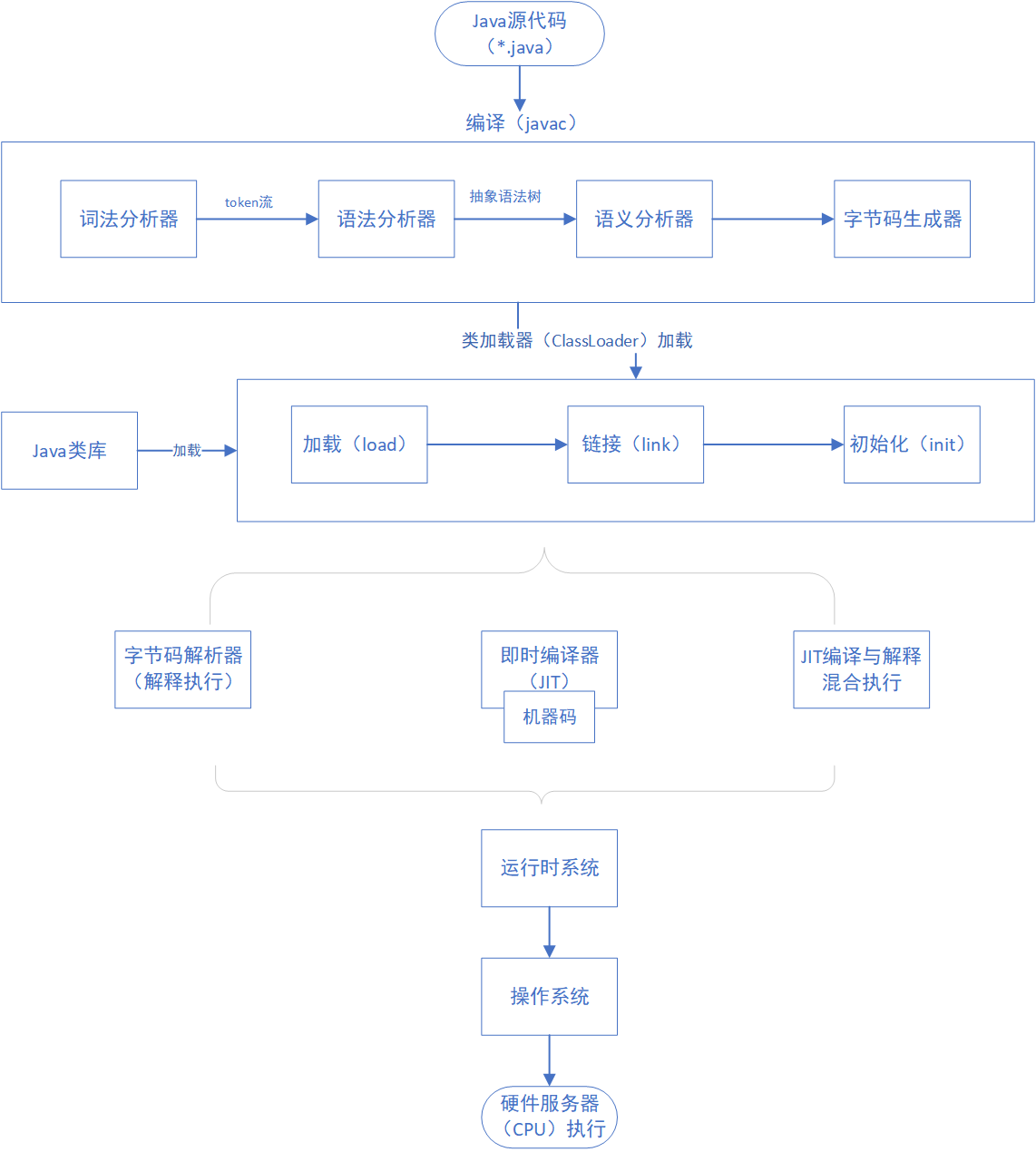
Java代码的整个运行过程可以分为编译阶段和加载阶段。
我们先来看下在编译阶段Java源代码经历了些什么:
1. 编译阶段
Java源代码通过词法解析、语法解析、语义解析等一系列执行过程,生成字节码。
很抽象有木有?啥是词法解析、啥是语法解析、啥是语义解析???别急,下面我们一一解释:
词法解析:即通过空格分隔出单词、操作符、控制符等信息,将其形成token信息流,传递给语法解析器。
语法解析:把词法解析获得的token信息流按照Java语法规则组装成语法树。
语义解析:检查关键字的使用是否合理、类型是否匹配、作用域是否正确等。
明白了这些,下面我们一起来看看加载阶段都做了什么:
2. 加载阶段
加载阶段类加载器对字节码经过Load阶段、Link阶段、Init阶段等一系列动作,将其加载到JVM,才可以执行。执行模式有三种:解释执行,JIT编译执行,JIT编译与解释混合执行。
啥啥啥???啥Load阶段?啥Link阶段?啥Init阶段?可不可以具体一点???

具体来说是酱紫的:
Load阶段读取类文件,产生二进制流,并转化为特定的数据结构,初步通过cafe babe魔法数来校验是否为Java类文件或文件是否受损、常量池、文件长度、是否有父类等等,然后创建对应的java.lang.Class实例。
Link阶段包括验证、准备、解析三个步骤。验证是更详细的校验,比如final是否合规、类型是否正确、静态变量是否合理等;准备阶段是为静态变量分配内存,并设定默认值;解析类和方法确保类与类之间相互引用的正确性,完成内存结构布局。
Init阶段执行类构造器clinit方法,如果赋值运算是通过其他类的静态方法完成的,那么会马上解析另外一个类,在虚拟机中执行完毕后通过返回值进行赋值。
它的整个过程如下图:
运行时栈帧结构
运行时栈帧结构是酱紫的:
虚拟机栈的内部结构是栈帧,每个方法在执行的时候都会创建一个栈帧,用于存储局部变量表,操作数栈,动态链接,方法返回地址等信息;
局部变量表用来完成方法参数以及局部变量列表的传递过程,如果是实例方法,那么局部变量表中的每0位索引的Slot默认是用于传递方法所属对象实例的引用;
在方法执行的过程中,会有各种字节码指向操作数栈中写入和提取值;
某方法通过动态链接在常量池中查询方法的引用来调用另一个方法,进而完成方法调用;
方法返回地址即在方法退出之前,都需要返回到方法被调用的位置,程序才能继续执行;
某方法在调用另一个方法的过程,即是一个栈帧在虚拟机中的入栈到出栈的过程。
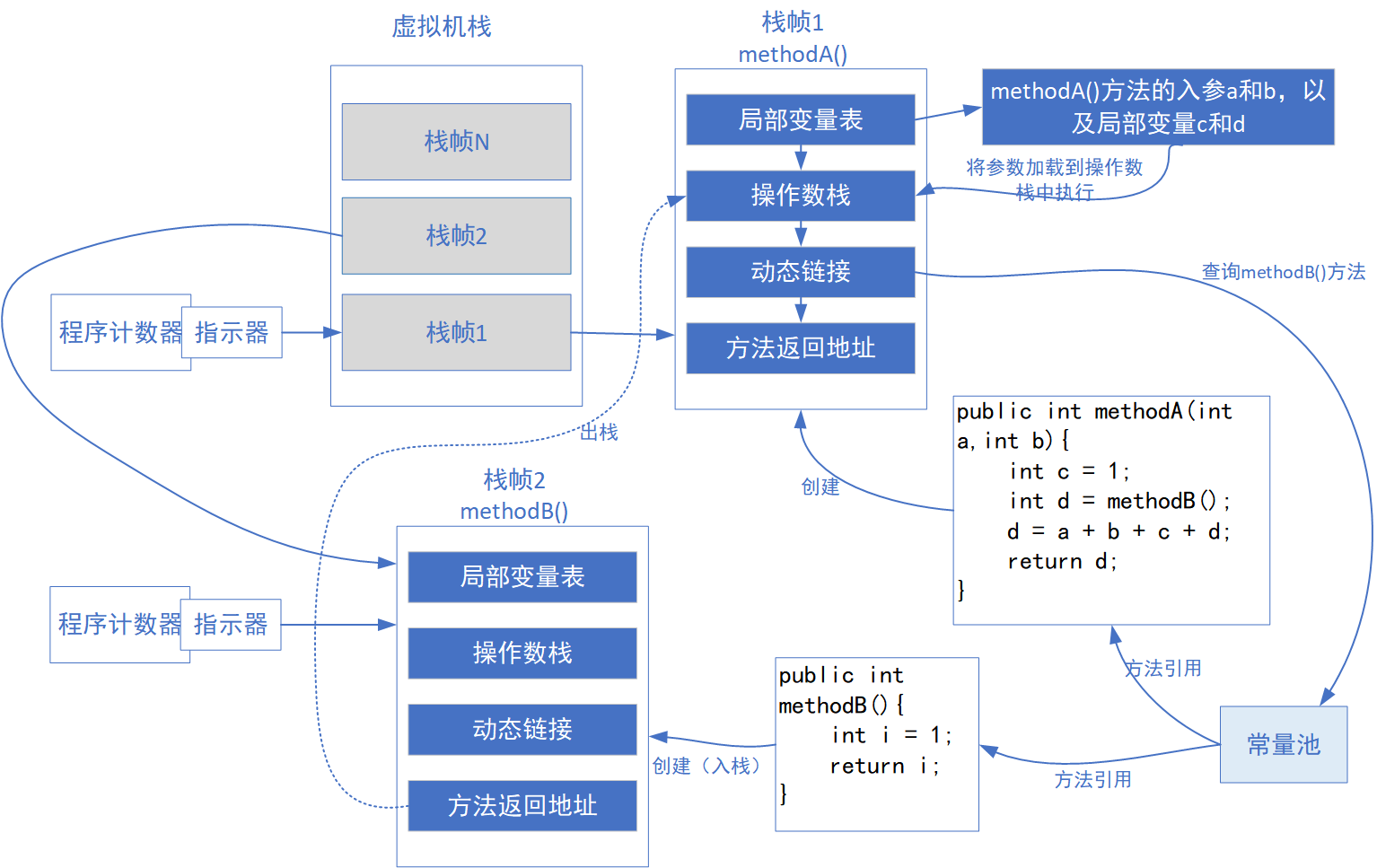
最后,虚拟机中的方法入栈的顺序和方法的调用顺序是一致的,先入栈的方法后出栈,后入栈的方法先出栈。
JVM堆内存分配方法
目前内存分配方法主要有指针碰撞法和空闲列表法。
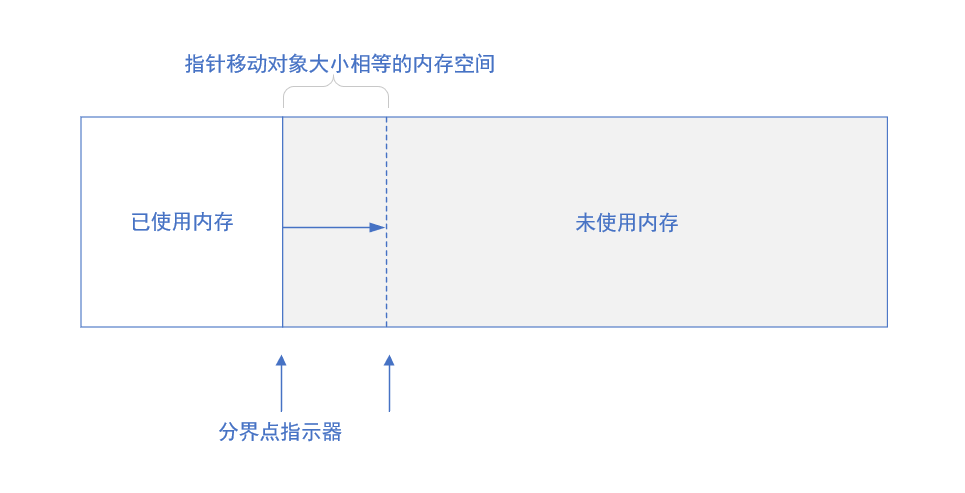
指针碰撞法:假设堆中内存是绝对规整的,所有用过的内存放一边,未使用过的放一边,中间有一个指针作为临界点,如果新创建了一个对象则是把指针往未分配的内存挪动与对象内存大小相同距离,这个称为指针碰撞。如下图所示:
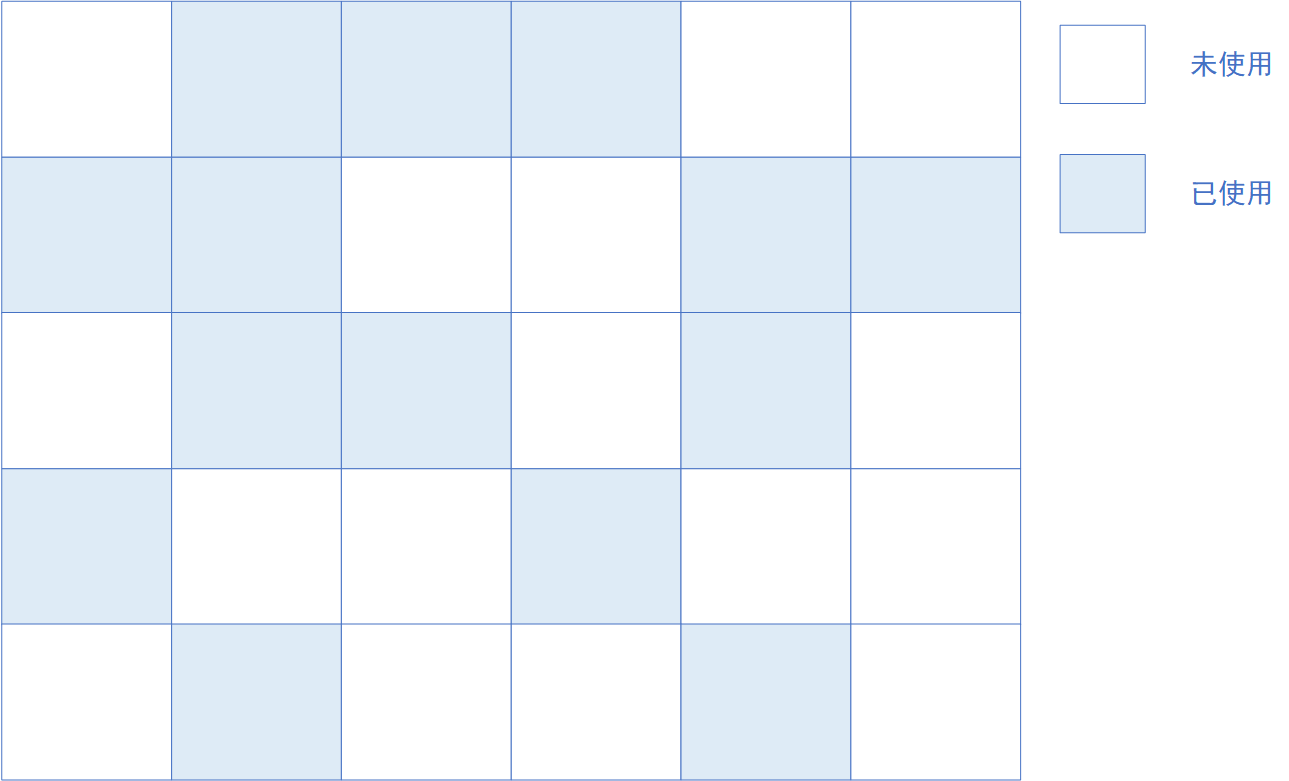
空闲列表法:其基于标记清除算法,内存划分成网格区,内存分配不规整,即已使用的和未使用的内存随机分布。JVM 会维护一个记录表,用于记录那些内存可用于分配,当需要给对象分配内存区域时,寻找一块足够大的内存空间分配给对象,并更新记录表,这种分配内存的方法叫做空闲列表法。如下图所示:
JVM是如何对对象的访问进行定位的?
我们创建对象自然是为了后续使用该对象,Java程序会通过栈上的reference数据来操作堆上的具体对象。
可是在《Java虚拟机规范》里面,只规定了reference类型是一个指向对象的引用,并没有定义这个引用应该通过什么方式去定位、访问到堆中对象的具体位置,所以对象访问方式也是由虚拟机实现而定的。

不过,目前主流的访问方式有句柄和直接指针两种方式。
指针: 指向对象,代表一个对象在内存中的起始地址。
句柄: 可以理解为指向指针的指针,维护着对象的指针。句柄不直接指向对象,而是指向对象的指针(句柄不发生变化,指向固定内存地址),再由对象的指针指向对象的真实内存地址。
了解了指针和句柄的概念,我们就来看看他们具体是怎么对对象的访问进行定位的。
1. 句柄访问
Java堆中划分出一块内存来作为句柄池,引用中存储对象的句柄地址,而句柄中包含了对象实例数据与对象类型数据各自的具体地址信息,具体构造如下图所示:
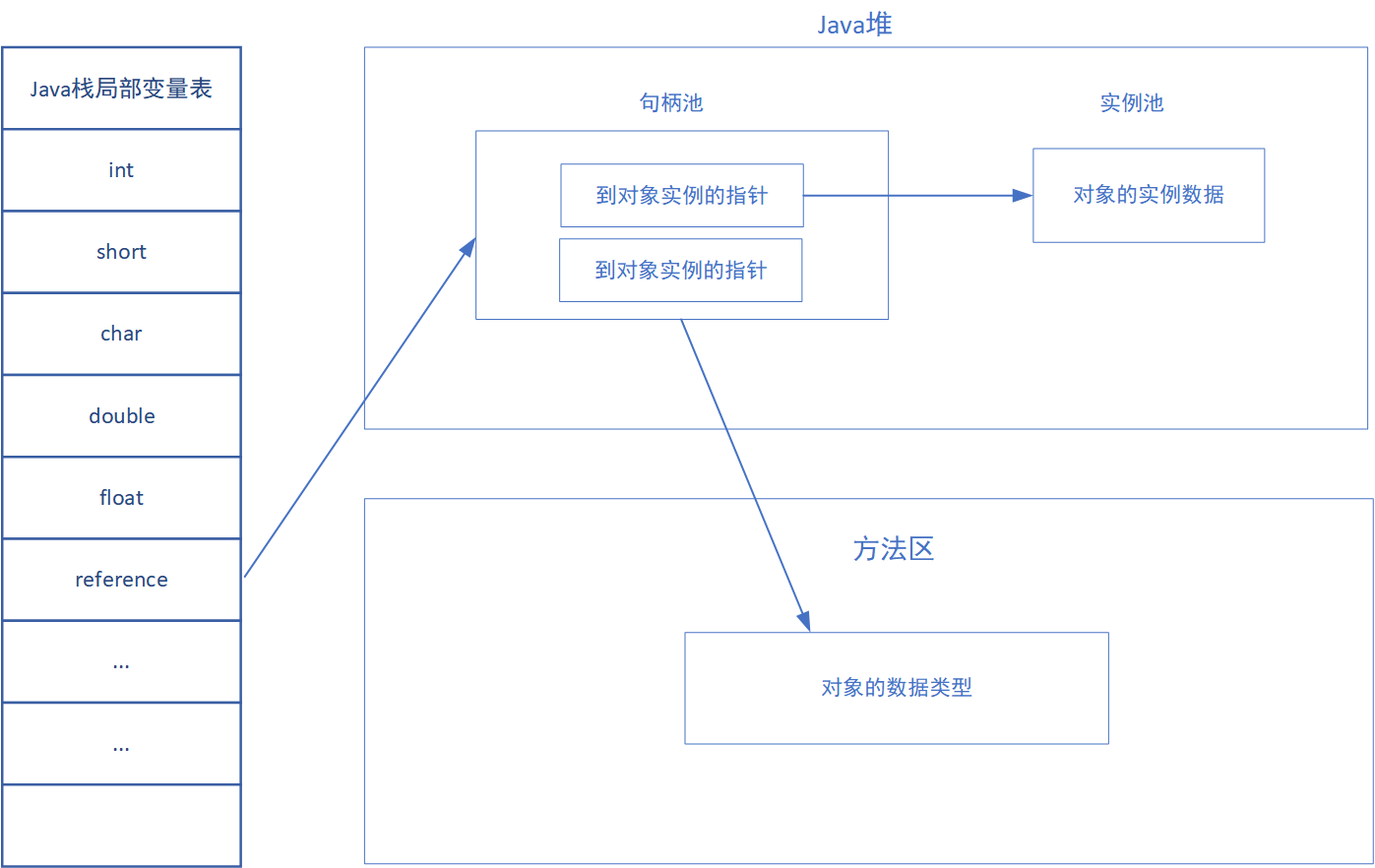
其优点是,引用中存储的是稳定的句柄地址,在对象被移动。比如:垃圾收集时移动对象是非常普遍的行为时,只会改变句柄中的实例数据指针,而引用本身不需要修改。
2. 直接指针
如果使用直接指针访问,引用中存储的直接就是对象地址,那么Java堆对象内部的布局中就必须考虑如何放置访问类型数据的相关信息。
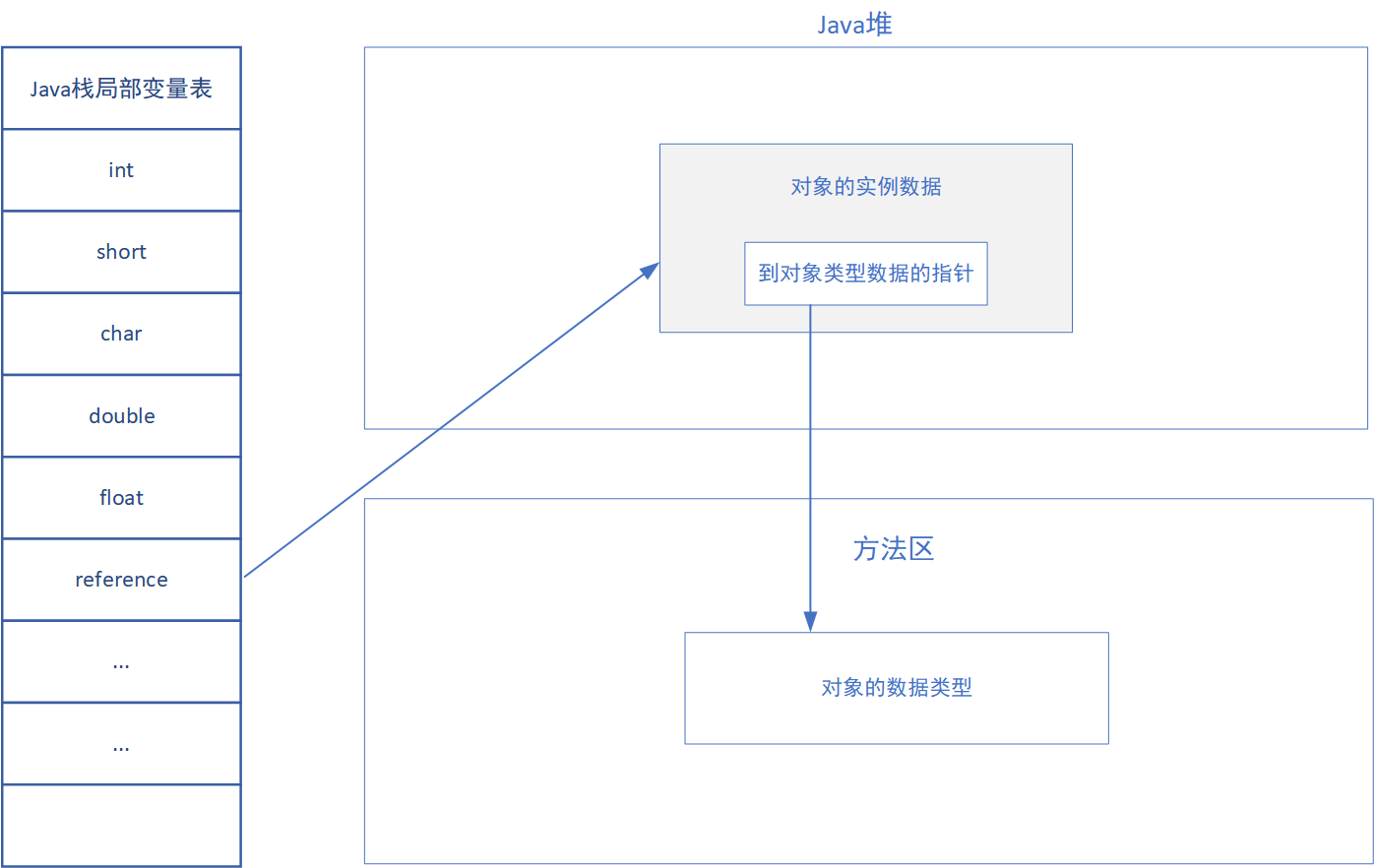
速度更快,节省了一次指针定位的时间开销。由于对象的访问在Java中非常频繁,因此这类开销积少成多后也是非常可观的执行成本。HotSpot中采用的就是这种方式。
最后
非常感谢小可爱们能看到这里,JVM内容复杂繁多,小码仔不可能在仅仅两篇文章中分析的面面俱到。最近这两篇文章整理的是我们面试中最为常见的一些问题,问题基本上比较常规,但也正是面试中的高频问题。
越是常规,我们越更要领悟、理解、掌握。但是这些相对常规的知识点你说你还不知道,那么我还能说什么~自裁吧。哦不,是关注我吧~
如果本篇文章有任何错误,请批评指教,不胜感激 !
如果你喜欢本文,那就点个赞吧~
欢迎关注我的微信公众号【小码仔】,我们一起探讨代码与人生。

文章参考:
- 《深入理解Java虚拟机》
- https://blog.csdn.net/u011531613/article/details/62971713
- https://blog.csdn.net/qq_38905818/article/details/10458235
- https://www.zhihu.com/topic/19566470/hot
- https://blog.csdn.net/u010588262/article/details/81365547
