

树
树是一个由根和子树构成的二维数据结构,满足以下几个特点:
- 每个节点都只有有限个子节点或无子节点;
- 没有父节点的节点称为根节点;
- 每一个非根节点有且只有一个父节点;
- 除了根节点外,每个子节点可以分为多个不相交的子树;
- 树里面没有环路(cycle)
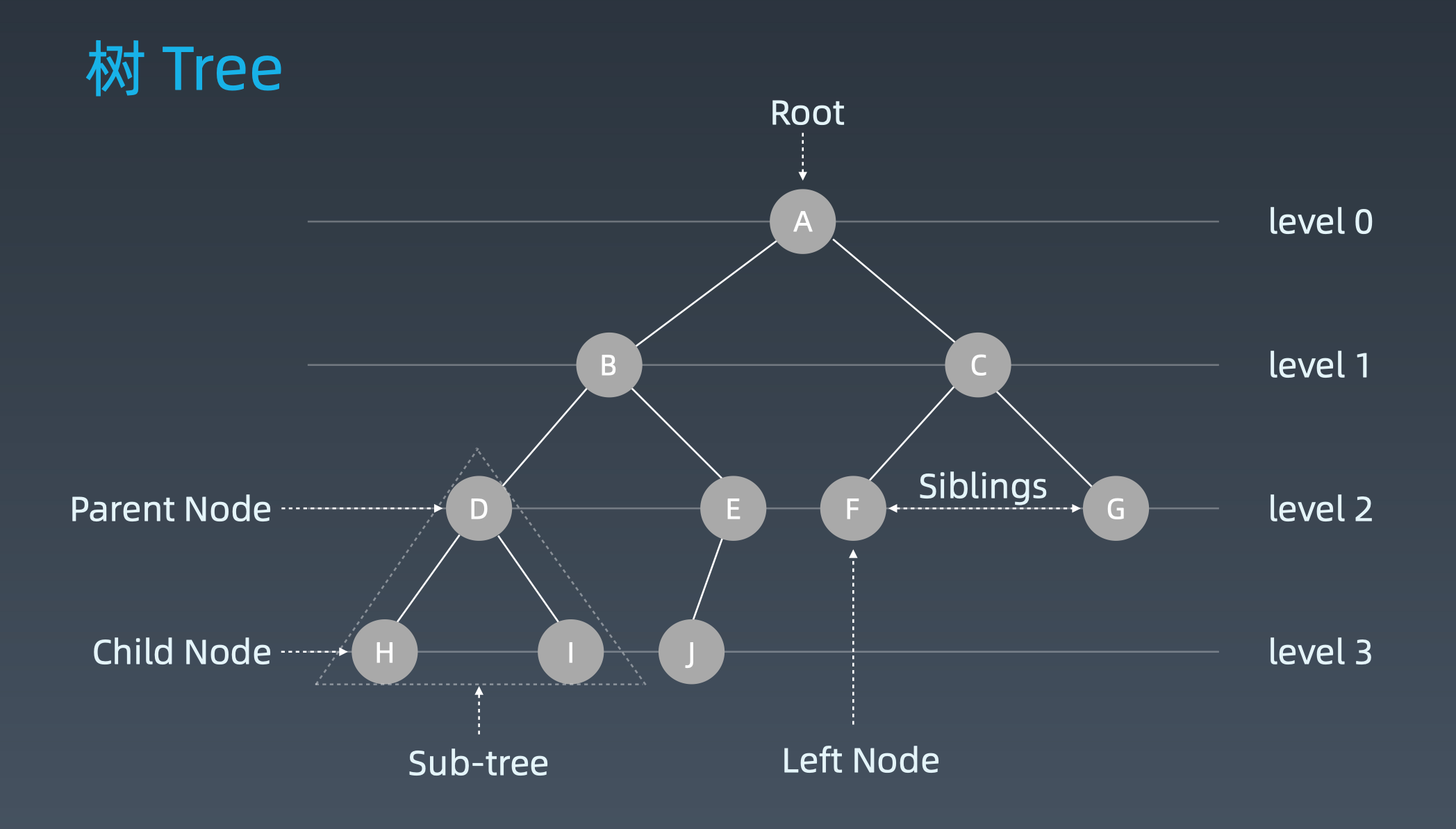
由于树的每个节点都具有相同的特点,所以跟树相关的问题几乎都能用递归来解决。
二叉树
每个节点最多只有两颗子树的树。
二叉树的遍历
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
dfs(res, root);
return res;
}
void dfs(List<Integer> res, TreeNode root){
if(root == null) return;
dfs(res, root.left);
res.add(root.val); // 根据访问根节点的顺序不同,可以分为前序、中序、后序遍历,这里是中序遍历
dfs(res, root.right);
}
}
二叉搜索树(Binary Search Tree)
二叉搜索树,也称二叉搜索树、有序二叉树(Ordered Binary Tree)、 排序二叉树(Sorted Binary Tree),是指一棵空树或者具有下列性质的二叉树:
- 左子树上的所有节点小于根节点
- 右子树上的所有节点大于根节点
- 根节点的左右子树也为二叉搜索树
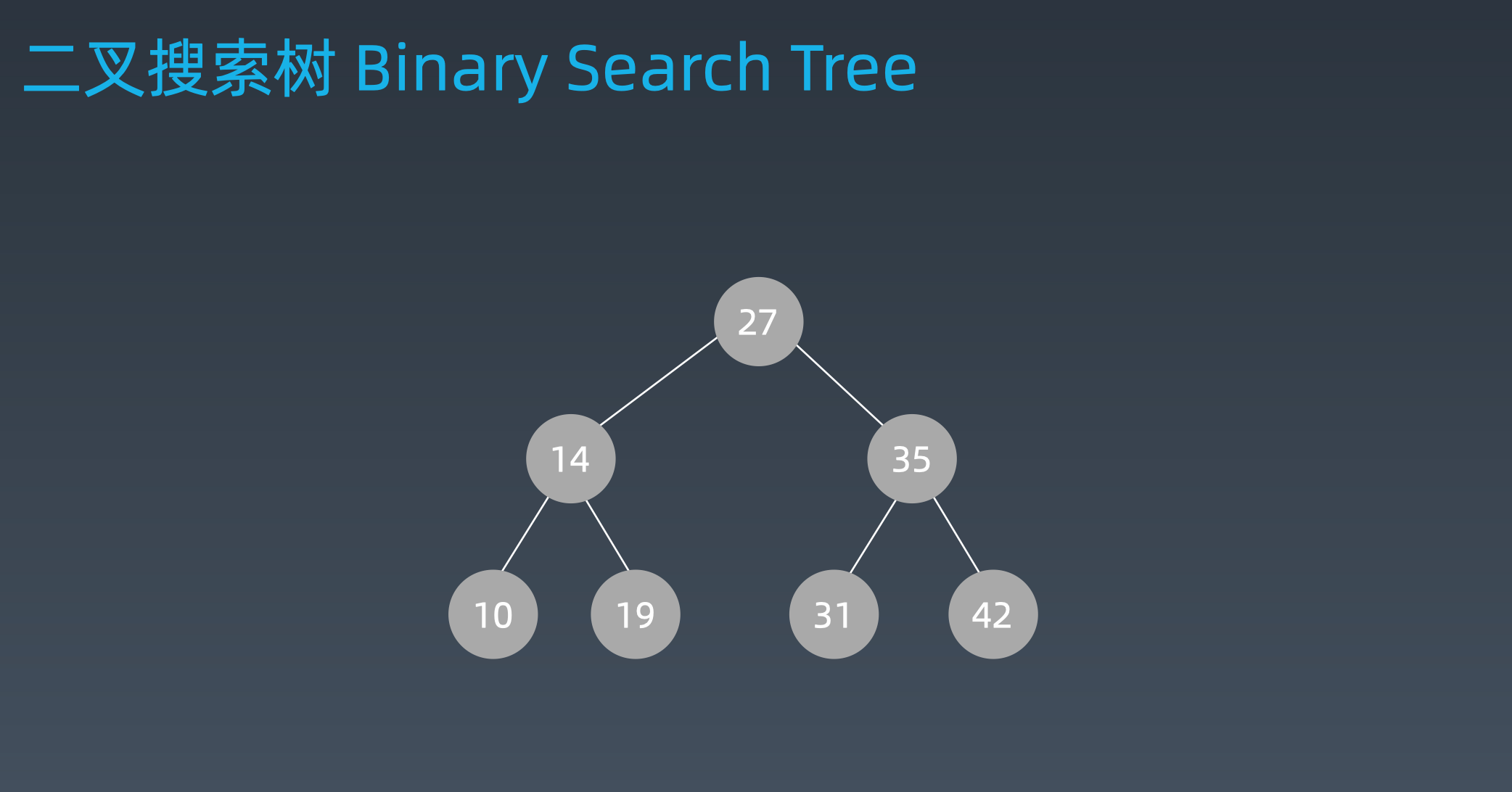
根据这些性质,二叉搜索树最大的特点就是其中序遍历是升序的,另外二叉搜索树插入、删除、访问、搜索时间复杂度都是O(logn)。
图
图是由定点和边构成的二维数据结构,用来表示元素之间的关系。从定义的角度来说,树其实是特殊化的图(无向无环),而链表又是特殊化的树(只有单边子树)。图的遍历方法有广度优先搜索(Breadth First, BFS Search)和深度优先搜索(Depth First Search, DFS)。
堆
堆是一个顶点元素总是小于其子节点元素的数据结构,所以堆的堆顶元素总是元素列表中最大值或最小值。
二叉堆
二叉堆(英语:binary heap)是一种特殊的堆,二叉堆是完全二叉树或者是近似完全二叉树。二叉堆满足堆特性:父节点的键值总是保持固定的序关系于任何一个子节点的键值,且每个节点的左子树和右子树都是一个二叉堆。因为这些性质,二叉堆的插入、删除、搜索、访问任意元素的操作时间复杂度都是O(logn),访问最大或最小元素的时间复杂度为O(1)。
递归
递归,讲起来很简单,先递进再回归。

我认为递归是计算机计算效率远超人类的三大原因之一(判断、循环和递归)。因为相比计算机,世世代代人类的老祖先们却只能顺序迭代,所以这就导致了递归是非常反人类天性的,这也是大部分人觉得递归难的根本原因。
递归模板
这里给出递归的Python代码模板,其他语言类似。
def recursion(level, param1, param2...):
# 1.terminator
if level > MAX_LEVEL:
process_result
return
# 2.process
process(level, data...)
# 3.drill down
recursion(level+1, p1, p2...)
# 4.restore the current level's states if needed
递归的要点
- 不要一层一层人肉递归,因为人肉递归会很耗脑力,让你非常累(反直觉,但没有办法)
- 找到最近重复子问题,或者将一个大问题拆成可重复的子问题
- 数学归纳法思维
分治
分治的思想就是把大问题分成小问题,解决小问题,再把小问题的解答合并得到大问题的解答
所以分治的代码模板就是在递归的基础上增加了split the problem和merge subproblems
def divide_conquer(problem, param1, param2, ...):
# recursion terminator
if problem is None:
print_result
return
# prepare data
data = prepare_data(problem)
subproblems = split_problem(problem, data)
# conquer subproblems
subresult1 = self.divide_conquer(subproblems[0], p1, ...)
subresult2 = self.divide_conquer(subproblems[1], p1, ...)
subresult3 = self.divide_conquer(subproblems[2], p1, ...)
…
# process and generate the final result
result = process_result(subresult1, subresult2, subresult3, …)
# revert the current level states
回溯
回溯的思想就是在递归解决问题的过程中,遇到不满足条件的情况,返回上一层重新选择路径解决。
回溯的代码模板是在递归的基础上,加入了对选择列表的循环,最重要的是restore current states,这一步也是回溯的精髓所在。
result = []
def backtrack(路径, 选择列表):
if 满足结束条件:
result.add(路径)
return
for 选择 in 选择列表:
# 做选择
路径.add(选择)
(将该选择从选择列表移除)
backtrack(路径, 选择列表)
# 撤销选择,restore current states
路径.remove(选择)
(将该选择重新添加到选择列表)
