

[toc]
模型融合和树模型 小笔记
组合策略
voting
voting策略是投票思想。
1.一人一票,票多者得
2.加权投票,一人可能有多张票
3.直接选其中最牛逼那个人
average
就是平均取值
模型融合种类
先明确一下,模型融合是将多个弱模型融合成一个强模型(往往需要meta模型弱才好)
Boostrap
有放回的均匀抽样(可以用来给不同的弱模型以不同之数据)
Bagging
bagging需要基分类器方差尽可能大。
bagging == boostrap aggregation,
每次boostrap得到的训练集给每个弱模型训练,然后融合结果(这里的基学习器权重是各自的,并行学习)
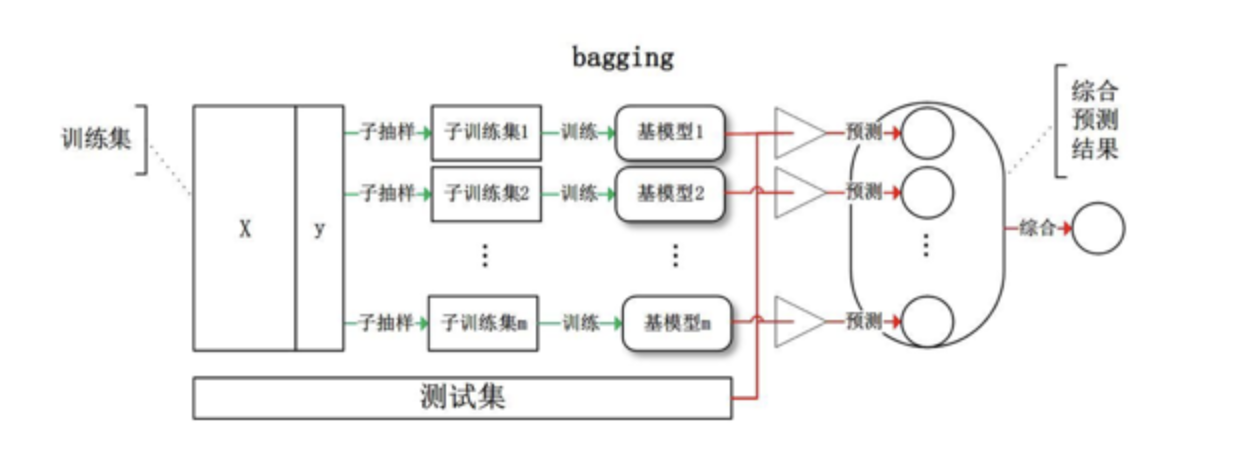
bagging一般使用强学习器,主要关注降低方差
Boosting
与bagging相比,boosting在于放大错误,比如说,在这一次基学习器分类错误,那么就把这个对应的权重放大,然后再替换掉下一次基学习器的权重。也就是说boosting是前一个基学习器进行分类,然后把权重转移给下一个基学习器,如此类推。。。。。最后将所有的结果进行汇总。
boosting一般使用弱学习器,主要关注降低偏差
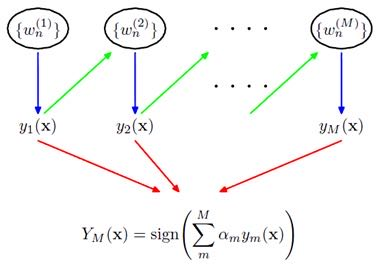
boosting的两个权重
- 第一个为弱分类器之间传递的权重,即参数权重
(我发现分为两种,一种是直接改变分错的权重,一种是把前N-1个模型都分错的数据添加到新的训练集里面再用来训练第N个模型)
(改变权重相当于变相采样,改变了样本的分布) - 第二个权重就是弱分类器自身的权重,就是弱分类器之间谁说的话更有用(根据分类错误率来)
adaboost
是一个加法模型+前向分布算法+指数损失函数
是boosting中的代表,第一个具有适应性的算法,适应弱学习器各自的训练误差率。
- 一般来说adaboost的弱学习器为一层的决策树
- 自适应的参数权重改变(选用指数损失函数),这里用林轩田老师的图(也可以根据分错的数据来进行数据的再采样)

- 弱分类器的投票机制变为加权的
Gradient boosting
adaboost采用的是指数损失函数,对异常点非常敏感,也就导致了在有噪音的情况下,影响比较大。于是就有了GB。GB不在乎用什么损失函数,它是将负梯度作为目标,通过不断拟合前一个模型损失函数的负梯度(也叫伪残差)而不断改进。
blog.csdn.net/zpalyq110/a…
stacking
stacking是一种分层模型集成框架,以两层为例子。
数据组成: train + test + valid
使用5-fold交叉验证
-
level 0 用train训练第一个模型,然后预测test和valid,这样重复5次后,会得到5倍的valid pred以及5倍的test pred,然后将valid pred排好作为新的训练集。test pred 用加权平均(其他方法也行)把数目控制到和原有的test数目一致,然后作为新的test(这只是一个模型,其他模型还要重复上述动作),这仅仅是一列特征
-
level 1 将每个模型得到的valid pred 和 test valid分别凭借起来作为level 1 模型的训练集和测试集。这里level 1模型中训练集的label Y是真实数据(train+valid)的label Y,测试集同理。
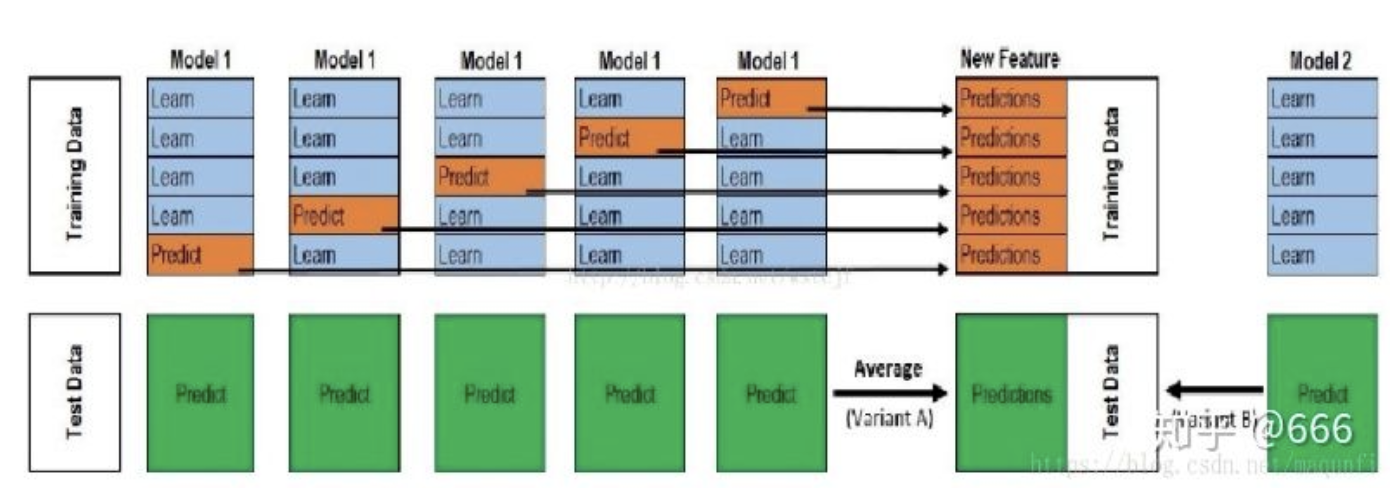
相比于blending,stacking两层都使用了所有的训练数据。
不同于boosting和bagging,stacking中基学习器一般允许不同的模型,如LR,SVM,LR等等, 属于对基学习器的非线性融合
blending
和stacking类似,不过没用k-fold,是直接划分部分数据作为验证集
CART
classification and regression tree
- CART分类树 采用gini指数作为划分标准,gini表示不稳定性,选取gini最小的特征
- CART回归树 根据数据计算每个切分点的平均误差,选取最小的作为最优切分点进行切分。具体看 zhuanlan.zhihu.com/p/36108972
random forest
rf = bagging + CART 是一个加法模型
bagging的基学习器要求强学习器并且方差要大,而DT恰好强而且方差大。bagging的随机性能够有效降低DT不同划分条件带来的方差问题。所以,先bagging随机取样
boosting tree
boosting tree(提升树) == adaboost + CART
- 分类提升树
用gini
这里有个想法,对于分类提升树,是不是可以通过将分类错误数据放到训练集里然后给下一个CART分类树用(这样就不用计较它的weight变化) - 回归提升树(好像也叫残差树):
损失函数为平方函数,加法模型,要设置损失函数的阈值
树的划分可以参考上面CART的网址,接下来残差的计算也差不多,详细可看下面网址
www.jianshu.com/p/7902b2eb5…
blog.csdn.net/zpalyq110/a…
Gradient Boosting Decisioin Tree
GBDT = gradient boosting + CART 梯度提升树
与boosting tree类似,不过不是用残差作为新的数据集,而是用损失函数的负梯度值作为新的训练数据的y值。(对于回归问题来说,负梯度就是残差)
其要求高偏差低方差的弱分类器
blog.csdn.net/zpalyq110/a…
最后有实例
xgboost
本质上是GBDT,但把速度和效率发挥到极致
可以用线性分类器作为基学习器
GBDT是机器学习算法,XGBoost是该算法的工程实现。
xgboost使用二阶导数分离了损失函数的选择和参数调优

stats.stackexchange.com/questions/2…
此处应有笔记连接。。。。
lightGBM
- Histogram算法:直方图算法。
- GOSS算法:基于梯度的单边采样算法。
- EFB算法:互斥特征捆绑算法。
LightGBM = XGBoost + Histogram + GOSS + EFB
zhuanlan.zhihu.com/p/91167170
此处也应有笔记连接
参考资料
blog.csdn.net/wangqi880/a…
www.jianshu.com/p/a5b28cdfd… boosting, boostrap, bagging
blog.csdn.net/FrankieHell…
blog.csdn.net/u010412858/…
zhuanlan.zhihu.com/p/91836593 stacking和blending
zhuanlan.zhihu.com/p/42229791 stacking和blending
zhuanlan.zhihu.com/p/91659366 stacking和blending
zhuanlan.zhihu.com/p/57689719 bagging的局限与boosting的弥补
zhuanlan.zhihu.com/p/37358517 adaboost和gradient boost
www.uml.org.cn/sjjmwj/2019… adaboost
www.zhihu.com/question/37… boost and adaboost
zhuanlan.zhihu.com/p/36108972 CART
zhuanlan.zhihu.com/p/59751960 一文弄懂boost,提升树,残差书,GBDT
blog.csdn.net/ccblogger/a… 提升树和梯度提升树
www.cnblogs.com/mantch/p/11… xgboost
blog.csdn.net/v_JULY_v/ar… xgboost
zhuanlan.zhihu.com/p/91167170 lightGBM
stats.stackexchange.com/questions/2…
