

最近有幸在项目上接触到了深度学习中的目标检测领域,通过数周来的实践和相关知识的查阅,现在也算是在能在目标检测入门处徘徊了。这篇文章会在三大目标检测经典算法原理上加上自己的理解,希望大家看了此文能不再一脸懵逼地出去。
目标检测
什么是目标检测
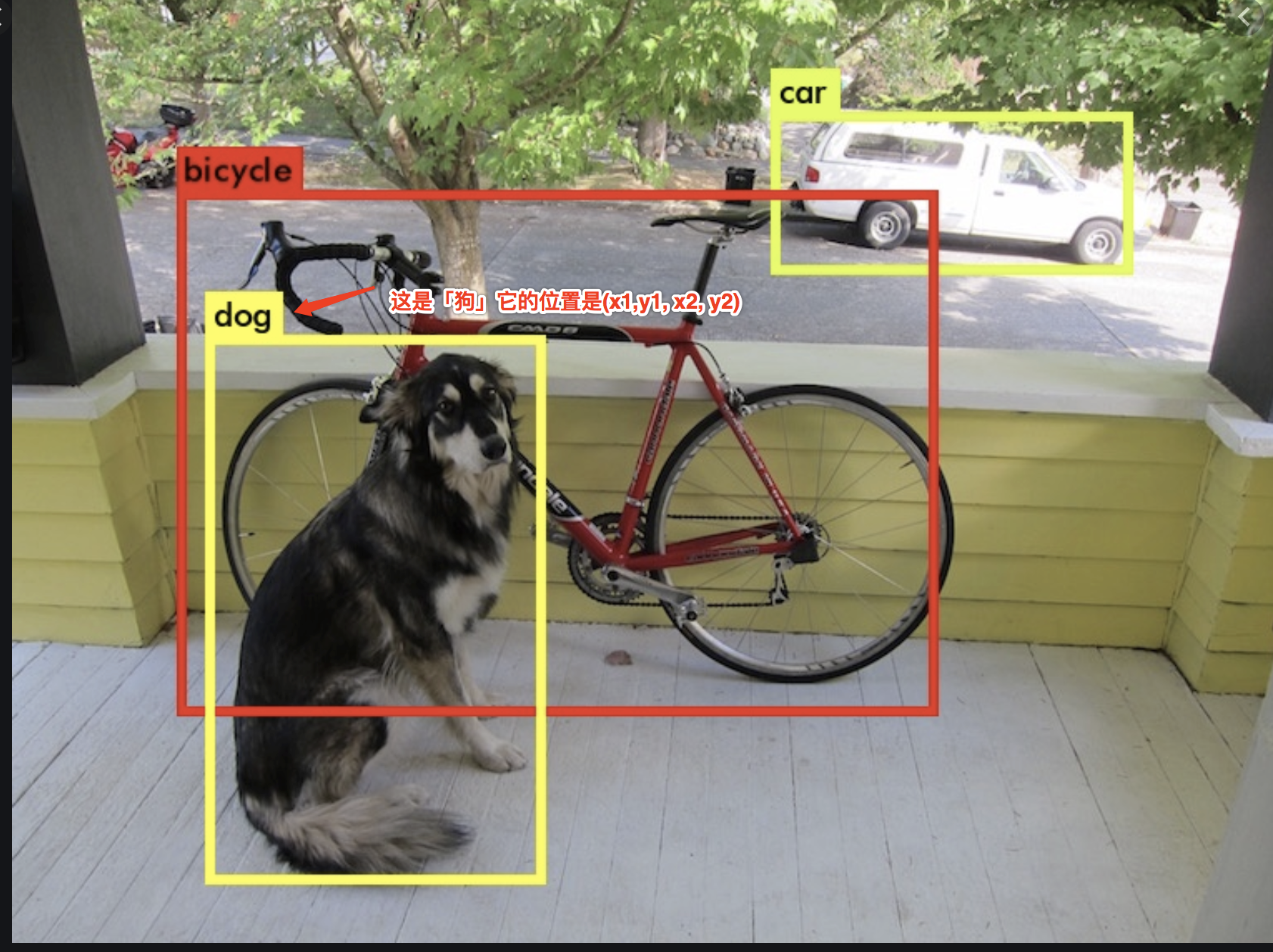
一句话概括即:在视图中检测出物体的【类别】和【位置】。
目标检测的三大算法
上面我们已经说了,目标检测就是分类和定位(回归,注:回归即得到确定值)的问题。分类问题我们可以输入图片至分类器处理,而定位问题需要将物体框选出来,那么怎么确定选框呢?这里我们可能需要一堆的「侯选框」。
看到这里我们大概确定了目标检测问题需要两步走:
- 侯选框选取;
- 将侯选框中的物体分类;(后面需要剔除得分低的框)
这样就得到了【两步走(Two-Stage)】的算法原型,代表是【RCNN】,之后的【Fast-RCNN】、【Faster-RCNN】都是基于它迭代的。
那能不能在侯选框选取的同时预测分类呢?也是可以的,这样就有了【SSD】和【YOLO】(One-Stage)。
下面我们来「稍微」详细地说一下每个算法具体的检测步骤。(非科班同学,有错误还望指正~)
RCNN及其迭代物(2-stage)
1、主要思想
所谓RCNN就是【Region】+【CNN】。完美地对应到了上述说的选框+分类。
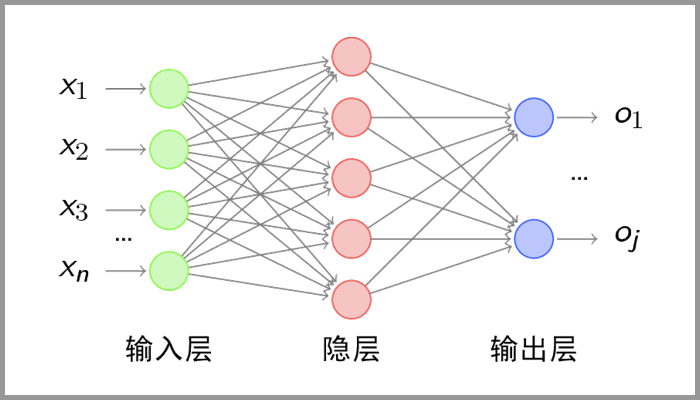
关于CNN是什么,如果想要深入的话大家可以看看这篇文章:一文看懂卷积神经网络。这里也简要概括下,CNN即对输入图片通过【降维】(卷积、激活、池化)等操作得到【图片的特征向量】作为【全连接层(就是多个神经网络层合并起来)】的输入,最后输出结果。
可以看下图,[x1, x2...xn]就可以看作是降维后的特征向量,然后通过神经网络处理得到输出的结果。
Region就是我们上面提到的侯选框,RCNN对于候选区域的确定是通过窗口扫描的方式。玩个经典游戏,在鸟中找到乌。我们可能会用眼睛逐行逐字扫描,这里我们可以将每个字看成一个格子,然后判断格子里面的字是不是乌。这个过程其实就是对RCNN的粗糙理解了。前期的选区选择主要采用的是【滑动窗口】技术,就是在视图起始点中确定一个选框,然后每次将选框移动特定的距离,再对窗口中的物体进行检测。

2、RCNN
看到上面,相信大家已经觉察到滑动窗口技术一个明显的弊端,我们不好确定初始窗口是否恰好能包裹到需要检测的物体,这就需要对初始窗口尺寸做非常多次的尝试,如果待检测物体数量较多,待检测窗口的个数更是成倍的增加,而且每次尝试都包含一次完整的CNN运算过程,这显然是非常耗时的。
所以RCNN在侯选框的选择上由滑动窗口技术改成了SS(selective search选择性搜索)技术。意思是通过纹理、颜色将视图划分开,再从中确定大约2000个区域作为候选区域,然后对其进行分类处理。
3、Fast-RCNN
Fast-RCNN的改进点在于:
- 首先将图片输入到CNN得到特征图
- 划分出特征图中的SS区域(这个在原图中得到)得到特征框,在ROI池化层中将每个特征框池化到统一大小
- 最后将特征框输入全连接层进行分类和回归
ROI池化层是将不同尺寸的特征框转化层相同尺寸的特征向量,以便进行后续的分类和输出回归框操作。它可以加速处理速度。
4、Faster-RCNN
Faster—RCNN步骤与Fast-RCNN类似。比较大的突破是:将侯选框提取技术由SS改为RPN。 RPN的简要原理是:
- 为输入特征图的每个像素点生成9个侯选框,如下图红框处;
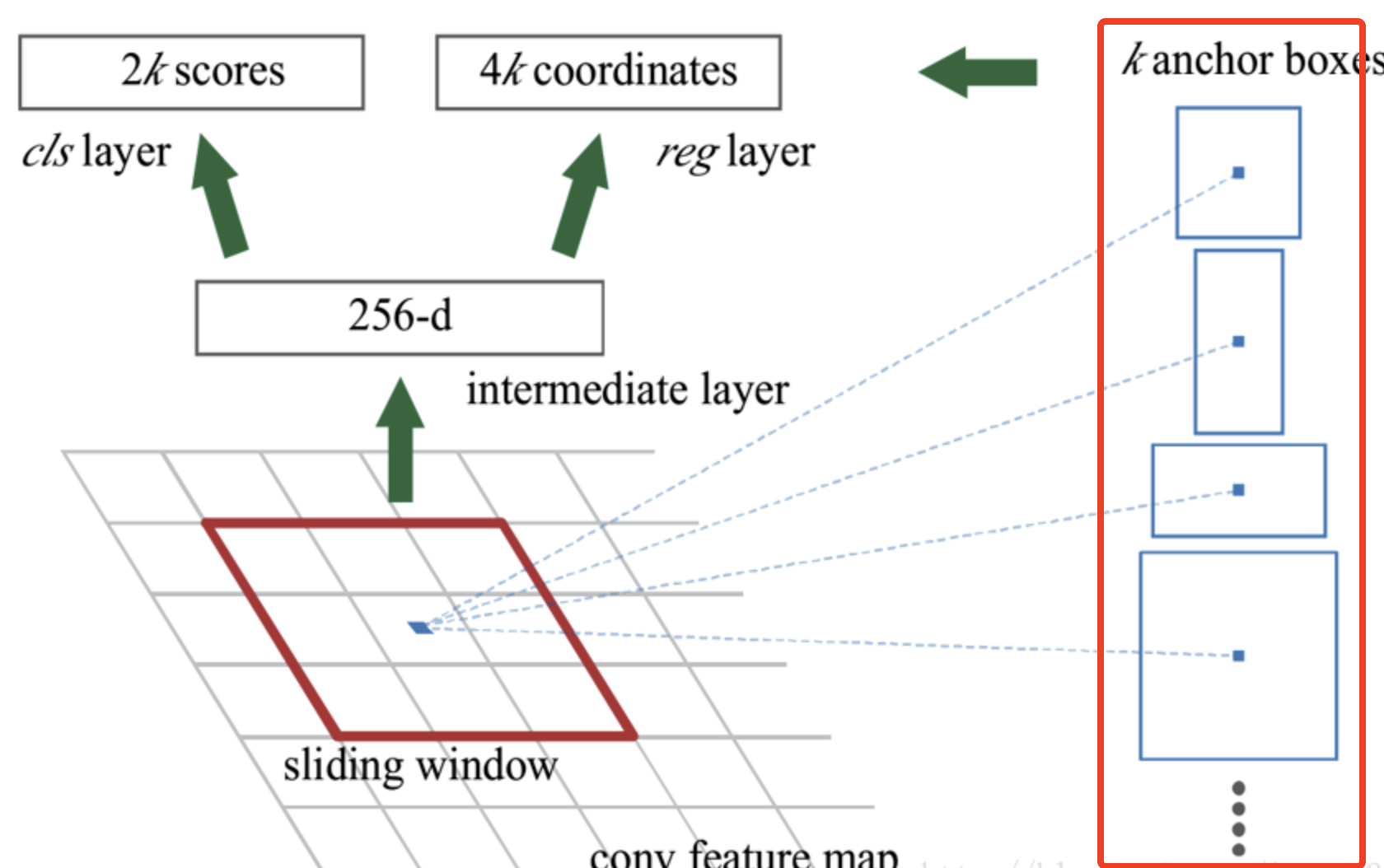
- 对生成的基础侯选框做修正处理,就是删除不包含目标的候选框;
- 对超出图像边界的侯选框做裁剪处理
- 忽略掉长或者宽太小的侯选框
- 对当前所有候选框做得分高低排序,选取前12000个侯选框
- 排除掉重叠的侯选框
- 选取前2000个做二次修正
SSD(1-stage)
对比与RCNN,SSD省去了候选区域的选择,而是将图片的feature maps分成n*n(下图n最大为38)个块,在每个块的中心点预设4~6个默认候选区域。
如下图,SSD首先是将图片进行特征提取,然后再加入多个辅助卷积层,设定各层的默认候选区域。设置多个卷积层的原因是为了更好地识别不同尺寸的目标。
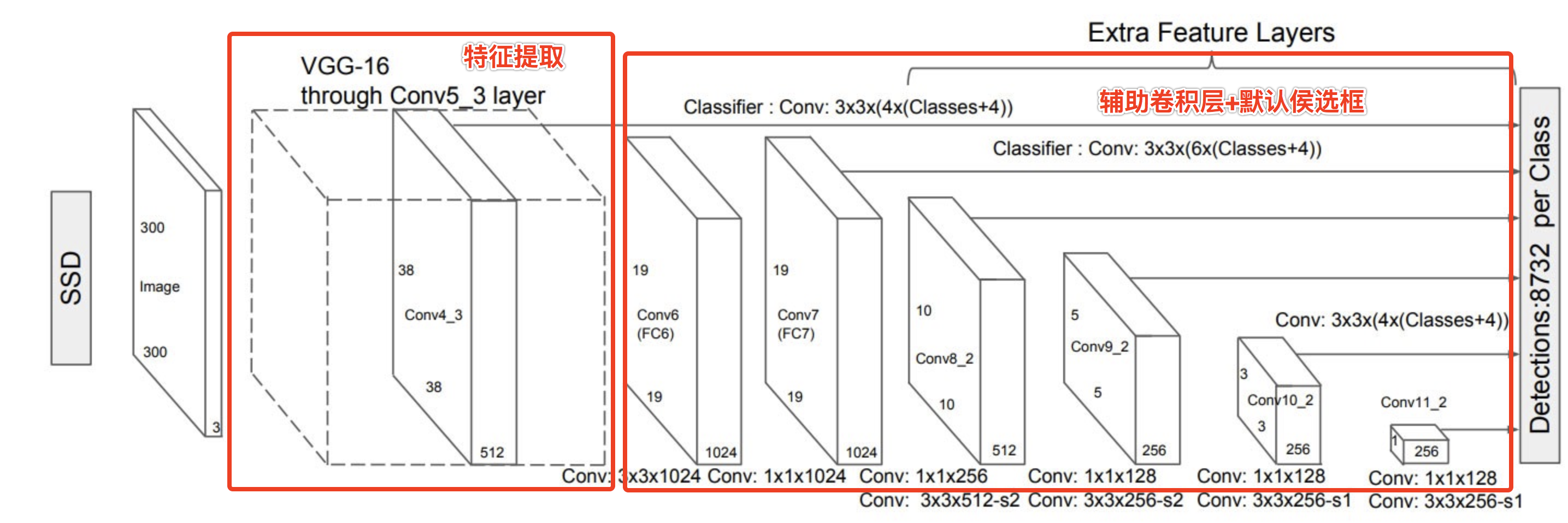
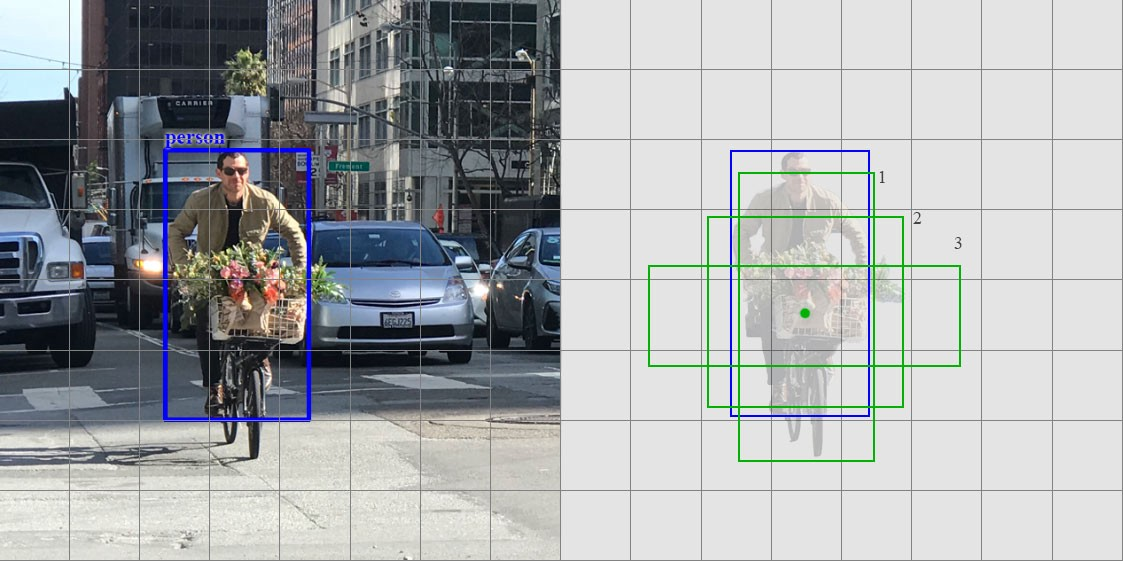
训练时,将生成的默认候选区域与实际标注区域做交并集合处理,具体计算为:IoU =(候选 ∩ 实际)/(候选 ∪ 实际),若IoU值大于0.5,即其与实际区域正匹配,这样我们就能得到目标的大致形状。下图为8*8的图片,在检测人时,SSD在单元格(4,5)的中心点(绿色点)处设置了3个默认侯选框(绿框),与真实框(蓝框)对比,可以发现1、2的相似度比较高。
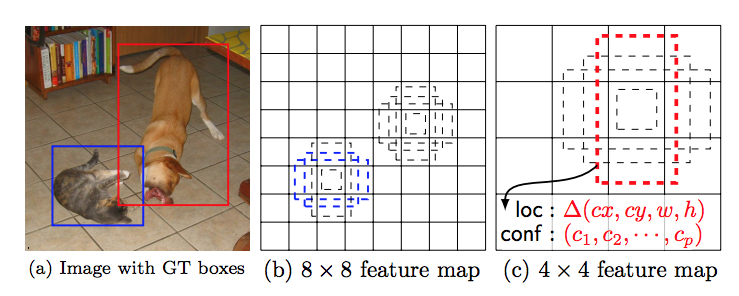
这里简单说明下多卷积层的用途。下图中,b为8 * 8特征图,c为4 * 4特征图。对于猫的检测,图b可以较好地确定选择区域。而对于狗的检测,图b的候选区域(右侧)显然没很好地将目标包裹,而c特征图则比较好地处理了对狗的检测。
因此,高分辨率特征图有利于检测小尺寸物体,低分辨率特征图有利于检测大尺寸物体
YOLO(1-stage)
YOLO大致的原理与SSD相似。但YOLO在检测时只利用了最高层的feature maps,而不同于SSD使用了多个辅助卷积层生层多个尺寸的feature maps(金字塔结构)。这里就不再赘述了。
