

图像成像原理
- CPU:对象的创建与销毁,对象属性的调整、布局计算、文本的计算与排版,图片的格式转换和解码、图像的绘制
- GPU:纹理的渲染
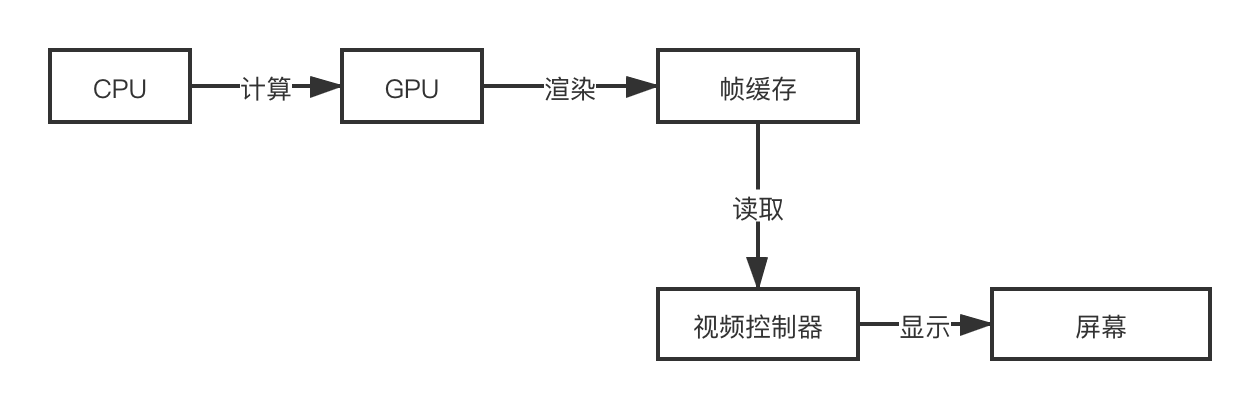
iOS采用了双缓存页交换技术 + 垂直同步技术
-
垂直同步:防止造成画面撕裂、跳帧的现象(就是这次还没有渲染完就显示到屏幕上了)。也就是当一次VSync信号(按照60FPS来算,就是16ms有一次VSync信号)来的时候,从屏幕缓冲区还读不到,那么这一帧就会等到下一次VSync信号来的时候再显示,也就是掉帧。
-
双缓存页交换技术
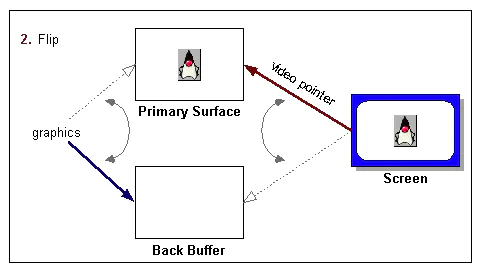
iOS的双缓存编码(CGBitmapContextCreate)
- 所谓“屏幕双缓冲”是指在内存中建立一个“图形设备上下文的缓存”,所有的绘图操作都在这个“图形上下文缓存”上进行,在需要显示这个“图形上下文”的时候,再次把它更新到屏幕设备上。
卡顿的解决思路
- 尽可能减少CPU、GPU资源消耗
- 尽量使用轻量级的对象,比如不需要事件处理的地方,可以用CALayer代替UIView
- 不要频繁的调整UIView的相关属性,如frame、bounds、transform等属性
- 提前计算好布局,在有需要时一次性调整对应的属性
- Autolayout会比直接消息frame消耗更多的资源
- 图片的size最好和UIImageView的size一样
- 控制一下线程的最大并发数量
- 将耗时操作放到子线程
- 文本处理(尺寸计算、绘制)
- 图片处理(解码、绘制)
- 尽量避免短时间内大量图片的显示,尽可能将多张图片合成一张进行展示
- GPU能处理的最大纹理是4096*4096,如果超过这个尺寸,就会占用CPU去处理
- 尽量减少视图的数量和层次
- 减少透明的视图,不透明就设置opaque = YES就可以了
离屏渲染
在OpenGL中,GPU有2种渲染方式 在屏渲染:在当前用于显示的屏幕缓冲区进行渲染操作 离屏渲染:在当前屏幕缓存区外新开辟一个缓冲区进行渲染操作
- 为什么消耗性能?
- 需要创建新的缓冲区
- 多次切换上下文环境,在屏缓冲区切换到离屏缓冲区,离屏渲染结束以后,将离屏缓冲区的渲染结果显示到屏幕上,又切换回在屏缓冲区。
- 哪些操作会触发?
- layer.shouldRasterize = true
- layer.mask
- layer.masksToBounds = true && layer.cornerRadius > 0(可以通过CG自己绘制裁剪圆角,或者叫美工提供圆角图片)
- layer.shadowXXX(但是如果设置了layer.shadowPath就不会产生离屏渲染了)
卡顿检测
- 利用Observer到主线程中的RunLoop中,通过监听RunLoop状态切换的耗时,以达到监测的目的
耗电的主要来源
- CPU
- 网络
- 定位
- 图像
耗电优化
-
少用定时器
-
优化I/O操作
- 尽量不要频繁写入小数据,最好指量一次性写入
- 读取大量重要数据时,考虑用dispatch_io,提供了基于GCD的异步操作文件I/O的API。系统会优化磁盘的访问
- 数据量比较大时,建议使用数据库
-
网络优化
- 减少、压缩网络数据
- 如果多次请求的结果是相同的,尽量使用缓存
- 使用断点续传,否则网络不稳定时可能多次传输相同的内容
- 批量传输
-
定位优化
- 如果只是需要快速确定用户位置,最好用CLLocationManager的requestLocation方法。定位完成后,会自动让定位硬件断电
- 不需要实时更新位置,定位完毕就关掉定位服务
- 尽量降低定位的精度
- 需要后台定位时,尽量设置pausesLocationUpdatesAutomatically为yes,如果用户不太可能移动的时候,系统就会自动暂停位置更新
APP的启动
- www.cocoachina.com/articles/24…
- 冷启动:从0启动
- 热启动:app已经在内存中,在后台存活着,启动
- 通过添加环境变量可以打印出App的启动时间分析
DYLD_PRINT_STATISTICS设置为1
或者更加详细的
DYLD_PRINT_STATISTICS_DETAILS设置为1(一般在400ms以内就是不错的了)
-
冷启动分为2大阶段
- pre-main:App开始启动到系统调用main函数的这一段时间
- main:main函数到主UI框架的viewDidAppear函数调用的这一段时间
-
app启动具体流程
- ①解析 info.plist
- 加载相关信息,例如闪屏
- 沙箱建立、权限检查
- ②Mach-O加载
- 如果是胖二进制文件,寻找合适当前CPU架构的部分
- 加载所有依赖的Mach-O文件(递归调用Mach-O加载的方法)
- 定位内部、外部指针引用
- 执行声明__attribute__((constructor))的C函数
- 加载类扩展(Category)中的方法
- C++静态对象加载,调用Objc的+load函数
- ③程序执行
- 调用main()
- 调用UIApplicationMain()
- 调用applicationWillFinishLaunching
dyld(苹果的动态链接器)
系统先读取App的可执行文件,从里面获得dyld的路径,然后加载dyld,dyld去初始化运行环境,开启缓存策略,加载程序相关依赖库,并对这些库进行链接,最后调用每个依赖库的初始化方法,在这一步,runtime被初始化。
当所有依赖库的初始化后,轮一最后一位进行初始化,在这时runtime会对项目中所有类进行类结构初始化,然后调用所有的load方法。最后dyld返回main函数地址,main函数被调用。
当加载一个Mach-O文件时,动态链接器首先会检查共享缓存看看是否存在其中,如果存在,那么就直接从共享缓存中拿出来使用。每一进程都把这个共享缓存映射到了自己的地址空间中。这个方法大大优化了iOS上程序的启动时间。
Executable(程序的可执行文件,Mach-O其中的一种格式)
- Mach-O被划分成一些segement,大小为页的整数。arm64下一面是16KB,其余为4KB。
- 几乎都包含__TEXT,__DATA和__LINKEDIT三个segment
- __Text包含Mach header,被执行的代码和只读常量。只读可执行
- __DATA包含全局变量,静态变量。可读写
- __LINKEDIT包含了加载程序的元数据。比如函数的名称和地址。只读
ASLR:地址空间布局随机化,镜像会在随机的地址上加载
代码签名:为了在运行时验证Mach-O文件的签名,并不是每次重复读入整个文件,而是把每页内容都生成一个单独的加密散列值,并存储在__LINKEDIT中。这使得文件每页的内容都能及时被校验确保不被纂改。
加载 Dylib
从主执行文件的 header 获取到需要加载的所依赖动态库列表,而 header 早就被内核映射过。然后它需要找到每个 dylib,然后打开文件读取文件起始位置,确保它是 Mach-O 文件。接着会找到代码签名并将其注册到内核。然后在 dylib 文件的每个 segment 上调用 mmap()。应用所依赖的 dylib 文件可能会再依赖其他 dylib,所以 dyld 所需要加载的是动态库列表一个递归依赖的集合。一般应用会加载 100 到 400 个 dylib 文件,但大部分都是系统 dylib,它们会被预先计算和缓存起来,加载速度很快。
加载系统的 dylib 很快,因为有优化(因为操作系统自己要用部分framework所以在操作系统开机后就已经缓存了?)。但加载内嵌(embedded)的 dylib 文件很占时间,所以尽可能把多个内嵌 dylib 合并成一个来加载,或者使用 static archive。使用 dlopen() 来在运行时懒加载是不建议的,这么做可能会带来一些问题,并且总的开销更大。
在每个动态库的加载过程中, dyld需要:
- 分析所依赖的动态库
- 找到动态库的mach-o文件
- 打开文件
- 验证文件
- 验证文件
- 在系统核心注册文件签名
- 对动态库的每一个segment调用mmap()
针对这一步骤的优化有:
- 减少非系统库的依赖;
- 使用静态库而不是动态库;
- 合并非系统动态库为一个动态库;
Rebase && Binding
- rebase: 在镜像内部调整指针的指向。
Slide = actual_address - preferred_address
然后就是重复不断地对 __DATA 段中需要 rebase 的指针加上这个偏移量。这就又涉及到 page fault 和 COW。这可能会产生 I/O 瓶颈,但因为 rebase 的顺序是按地址排列的,所以从内核的角度来看这是个有次序的任务,它会预先读入数据,减少 I/O 消耗。
- binding:将指针指向镜像外部的内容,binding就是将这个二进制调用的外部符号进行绑定的过程。
lazyBinding就是在加载动态库的时候不会立即binding, 当时当第一次调用这个方法的时候再实施binding。 做到的方法也很简单: 通过dyld_stub_binder这个符号来做。lazyBinding的方法第一次会调用到dyld_stub_binder, 然后dyld_stub_binder负责找到真实的方法,并且将地址bind到桩上,下一次就不用再bind了。
针对这一步骤的优化有:
-
减少Objc类数量, 减少selector数量,把未使用的类和函数都可以删掉
-
减少C++虚函数数量
-
转而使用swift stuct
ObjC SetUp
主要做以下几件事来完成Objc Setup:
- 读取二进制文件的 DATA 段内容,找到与 objc 相关的信息
- 注册 Objc 类,ObjC Runtime 需要维护一张映射类名与类的全局表。当加载一个 dylib 时,其定义的所有的类都需要被注册到这个全局表中;
- 读取 protocol 以及 category 的信息,把category的定义插入方法列表 (category registration),
- 确保 selector 的唯一性
ObjC 是个动态语言,可以用类的名字来实例化一个类的对象。这意味着 ObjC Runtime 需要维护一张映射类名与类的全局表。当加载一个 dylib 时,其定义的所有的类都需要被注册到这个全局表中。
Objc的load函数和C++的静态构造函数采用由底向上的方式执行,来保证每个执行的方法,都可以找到所依赖的动态库
-
dyld开始将程序二进制文件初始化
-
交由ImageLoader读取image,其中包含了我们的类、方法等各种符号
-
由于runtime向dyld绑定了回调,当image加载到内存后,dyld会通知runtime进行处理
-
runtime接手后调用mapimages做解析和处理,接下来loadimages中调用 callloadmethods方法,遍历所有加载进来的Class,按继承层级依次调用Class的+load方法和其 Category的+load方法
-
调用C++静态初始化器和__attribute__((constructor))修饰的函数
到此为止,可执行文件和动态库中所有的符号(Class,Protocol,Selector,IM,...)都已经按照一定的格式被装载进内存,被runtime管理
整个事件由dyld主导,完成运行环境的初始化后,配合ImageLoader 将二进制文件按格式加载到内存,动态链接依赖库,并由runtime负责加载成objc 定义的结构,所有初始化工作结束后,dyld调用真正的main函数
这一步可以做的优化有:
-
使用 +initialize 来替代 +load
-
不要使用 attribute((constructor)) 将方法显式标记为初始化器,而是让初始化方法调用时才执行。比如使用 dispatch_once(),pthread_once() 或 std::once()。也就是在第一次使用时才初始化,推迟了一部分工作耗时。也尽量不要用到C++的静态对象。
main阶段
总体原则无非就是减少启动的时候的步骤,以及每一步骤的时间消耗。
main阶段的优化大致有如下几个点:
-
减少启动初始化的流程,能懒加载的就懒加载,能放后台初始化的就放后台,能够延时初始化的就延时,不要卡主线程的启动时间,已经下线的业务直接删掉;
-
优化代码逻辑,去除一些非必要的逻辑和代码,减少每个流程所消耗的时间;
-
启动阶段使用多线程来进行初始化,把CPU的性能尽量发挥出来;
-
使用纯代码而不是xib或者storyboard来进行UI框架的搭建,尤其是主UI框架比如TabBarController这种,尽量避免使用xib和storyboard,因为xib和storyboard也还是要解析成代码来渲染页面,多了一些步骤;
