

阿里巴巴的 JAVA 规范的日志规约中提到了:
4. 【强制】在日志输出时,字符串变量之间的拼接使用占位符的方式。
5. 【强制】对于trace/debug/info级别的日志输出,必须进行日志级别的开关判断。
要明白这2条规约的原理,首先要先知道在CPU中,方法是如何调用的。例如下面这段代码:
String name = "tom";
logger.debug("hello, {}", name);
String uppercaseName = name.toUpperCase();
当执行到第2行,需要去调用logger.debug()方法时,CPU 要先找到方法 logger.debug() 的地址,然后跳转到这个地址去执行代码,最后 CPU 执行完方法 logger.debug() 之后,要能够返回。首先找到调用方法的下一条语句的地址:也就是String uppercaseName = name.toUpperCase();的地址,再跳转到这个地址去执行。
那么CPU怎么知道执行完方法之后接着去执行哪个地址的代码呢?答案就是:调用栈。
例如,有三个方法 A、B、C,他们的调用关系是 A->B->C(A 调用 B,B 调用 C),在运行时,会构建出下面这样的调用栈。每个方法在调用栈里都有自己的独立空间,称为栈帧,每个栈帧里都有对应方法需要的参数和返回地址。当调用方法时,会创建新的栈帧,并压入调用栈;当方法返回时,对应的栈帧就会被自动弹出。
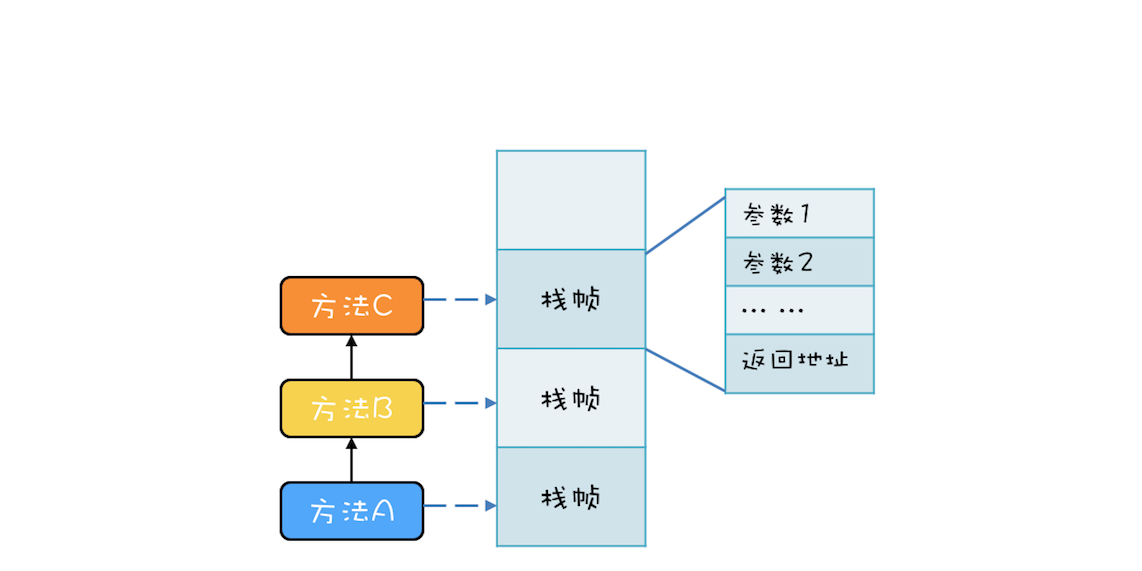
而且,还有很重要的一个原则:方法调用时,先计算参数,再将参数压栈,再执行方法体
再对比下面这个反例:
logger.debug("hello, " + name);
到此相信你就明白了,其实规约中的第4条和第5条是联系在一起的,即:
由于低级别的日志输出语句数量多,而且在大部分情况下生产环境的日志级别都比较高,一般都是 WARN 或者 ERROR 级别, 这些低级别的日志是不输出的。此时,如果代码中没有对日志级别进行判断且存在使用字符串拼接的现象,那么CPU会先进行字符串拼接操作(StringBuilder.append())计算出方法的参数,再将参数压栈,好不容易开始执行方法体了,发现在方法的第一行就因为日志级别不满足条件而直接被return了,接下来就得出栈,跳到原方法体的下一行语句继续执行,无谓的浪费了CPU的执行时间。