

数据分析基础
数组的概念
- 一维数组
- 二维数组
- 三维数组
数据处理的一般流程
数据收集-->数据预处理-->数据处理-->数据展示
-
数据收集的方法
- 网络爬虫
- 公开数据集
- 其他途径收集数据
-
数据预处理
- 归一化
- 二值化
- 维度变换
- 去重
- 无效数据过滤
-
数据处理方法
- 数据排序
- 数据查找
- 数据统计分析
-
数据展示的方法
- 列表
- 图表
- 动态交互图形
Numpy基础及基本应用
为什么用Numpy
- 高性能
- 开源
- 数组运算
- 读写迅速
安装Numpy
-
mac
pip3 install numpy
导入Numpy
import numpy as np
Numpy的基础类型-ndarray
-
创建一个ndarray数组
data = np.array([1,2,3,4,5])np.array()里直接填一个由数字组成的列表
-
创建一个二维ndarray数组
data = np.array([[1,2,3],[4,5,6]]) -
判断ndarray的维度
array_2=np.array([[1,2,3],[4,5,6]]) print(array_2.ndim) # 2 -
了解ndarray各维度的长度
python_list=[1,2,3,4,5] data=np.array(python_list) array_2=np.array([[1,2,3],[4,5,6]]) print(array_2.shape) # (2, 3) print(data.shape) # (5,) -
创建一个全部为0的数组
zero_array=np.zeros(9) print(zero_array) # [0. 0. 0. 0. 0. 0. 0. 0. 0.] -
创建一个全是1的二维数组
#两行5列 ones_array = np.ones((2,5)) print(ones_array)输出结果:
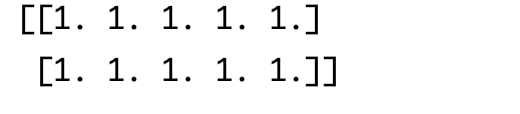
-
获取一维数组中某个元素
array_3=np.arange(10) print(array_3) # [0 1 2 3 4 5 6 7 8 9] print(array_3[5]) # 5 -
获取二维数组中的某个元素
array_4=np.array( [ [1,2,3,4], [5,6,7,8] ] ) # 获取第1行,第2列(索引从0开始) print(array_4[1,2]) #7 print(array_4[1][2]) # 第二种表示方式 -
获取数组中某几个数字(切片)
array_5=np.arange(10) print(array_5) # [0 1 2 3 4 5 6 7 8 9] array_6=array_5[2:5] print(array_6) # [2 3 4],切头不切尾 array_6[0]=100 print(array_5) # [ 0 1 100 3 4 5 6 7 8 9]- 切片得到的数据对应的还是原始数据,任何数据的修改都会反应在原始数据上
- 想要一份副本不影响原始数据
array_6=array_5[2:5].copy()
-
变换数据的维度
data=np.arange(10) print(data) print(data.reshape(2,5))- 变换数据的维度,必须是恰好能够变换,比如2行5列是10个,但是3行3列就会报错
输出结果:
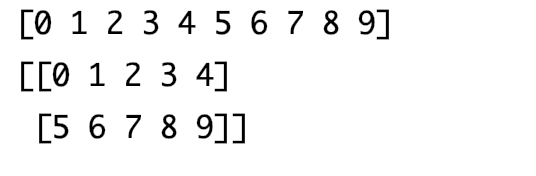
-
矩阵的转置
array=np.array([[1,2,3],[4,5,6]]) print(array) print(array.T)输出结果

-
对ndarray数组每个元素都求平方根
array=np.array([[1,2,3],[4,5,6]]) print(np.sqrt(array))输出结果

-
两个数组相加
data1=np.array([1,2,3,4]) data2=np.array([2,3,4,5]) print(data1+data2) # [3 5 7 9] print(np.add(data1,data2)) # 方式二
-
数学及统计方法:求和
data=np.arange(10) print(data.sum()) #45 print(np.sum(data)) -
数学及统计方法:求平均值
data=np.arange(10) print(data.mean()) #4.5 print(np.mean(data)) -
数学及统计方法:求标准差
data=np.arange(10) print(data.std()) #2.8722813232690143 print(np.std(data))
-
数组的排序
data=np.array([2,3,6,8,0,1]) data.sort() print(data) # [0 1 2 3 6 8] -
ndarray的存取
spider.txt内容如下:

data=np.genfromtxt('spider.txt',delimiter=',') print(data)
-
数组.astype(要转换成的数组类型)
data=np.genfromtxt('spider.txt',delimiter=',') print(data.astype(int))
作业
数据如下:
202001,1,4
202001,1,3
202001,1,5
202001,1,4
202002,2,5
202002,2,5
202002,2,4
202002,2,2
202003,3,3
202003,3,3
202003,3,4
202003,3,2
202004,4,5
202004,4,3
202004,4,4
202004,4,5

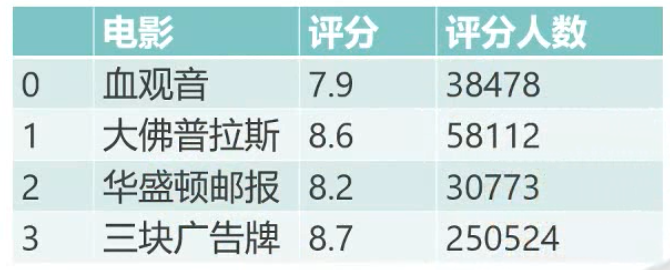
# 以上述4本书为例
# 1. 读取数据并转换为整数
data=np.genfromtxt('rating.txt',delimiter=',' )
data=data.astype(int)
# 2. 创建2个数组,分别存各个书籍的总得分和总评分人数
rating_sum=np.zeros(4)
rating_people_count=np.zeros(4)
# 3. 循环读取每行数据
for rating in data:
book_id=rating[1]-1
rating_sum[book_id]+=rating[2]
rating_people_count[book_id]+=1
# 4. 输出平均得分
print(rating_sum/rating_people_count)
Pandas基础及基本应用
为什么用Pandas
- 快速高效的数据结构
- 智能的数据处理功能
- 方便的文件存取功能
- 科研及商业应用广泛
Pandas数据结构
-
Series
单列
-
DataFrame
多列
安装Pandas
pip3 install pandas
导入Pandas
import pandas as pd
Pandas基础类型1 -- Series
-
创建一个Series类型的数据
data=pd.Series([1,2,3,4]) print(data)pd.Series()里直接填由数字组成的列表
输出结果:索引 值

-
获取Series数据的值和索引
data=pd.Series([1,2,3,4]) print(data.values) # [1 2 3 4] print(data.index) # RangeIndex(start=0, stop=4, step=1) -
创建特殊的索引值
data=pd.Series([1,2,3,4],index=['a','k','b','c']) print(data)
-
修改索引值名称
data=pd.Series([1,2,3,4],index=['a','k','b','c']) data.index=['A','B','C','D'] print(data)输出结果

-
获取Series的数据长度
print(len(data)) -
获取数组中的某个数据
data=pd.Series([1,2,3,4],index=['a','k','b','c']) print(data['a']) # 1 -
获取数组中的多个数据(用索引)
data=pd.Series([1,2,3,4],index=['a','k','b','c']) print(data[['a','c']])输出结果

-
获取数组中的多个数据(切片)
data=pd.Series([1,2,3,4],index=['a','k','b','c']) print(data[0:2]) -
计算重复元素出现的次数
data=pd.Series([1,2,2,2,3,4,4]) print(data.value_counts())输出结果

-
判断某个索引值是否存在
data=pd.Series([1,2,3,4],index=['a','k','b','c']) print('a' in data) # True -
从字典创建一个Series类型的数据
字典的key就是索引,字典的值就是索引对应的值
dict_data={ 'Beijing':800, 'Shanghai':2000, 'Guangzhou':1000 } data=pd.Series(dict_data) print(data)输出结果

-
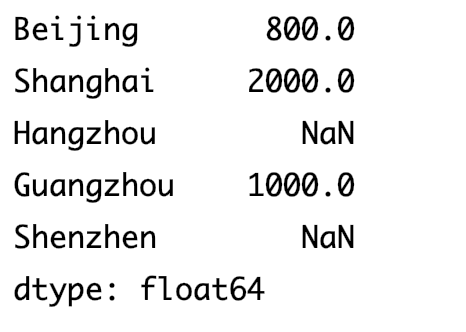
给数据传入索引值
dict_data={ 'Beijing':800, 'Shanghai':2000, 'Guangzhou':1000 } index_list=['Beijing','Shanghai','Hangzhou','Guangzhou','Shenzhen'] data=pd.Series(dict_data,index=index_list) print(data)输出结果
-
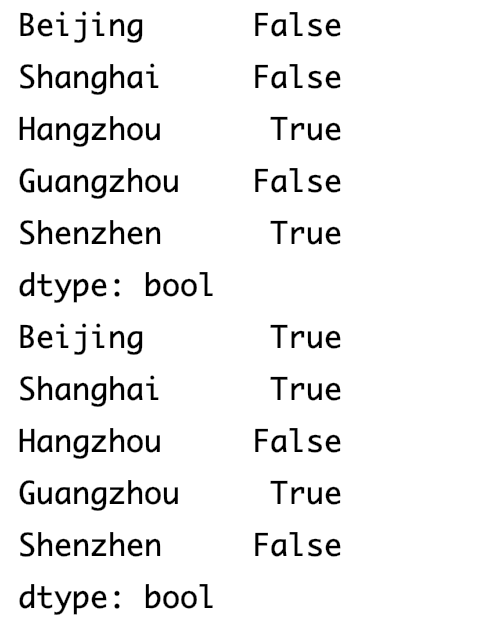
检测哪些数据是缺失的(空的)
print(data.isnull())检测非空用
notnull()dict_data={ 'Beijing':800, 'Shanghai':2000, 'Guangzhou':1000 } index_list=['Beijing','Shanghai','Hangzhou','Guangzhou','Shenzhen'] data=pd.Series(dict_data,index=index_list) print(data.isnull()) print(data.notnull())输出结果
-
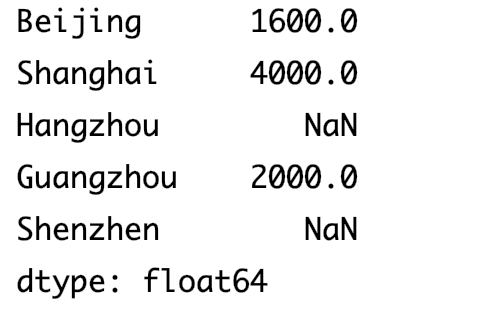
数组的运算
dict_data={ 'Beijing':800, 'Shanghai':2000, 'Guangzhou':1000 } index_list=['Beijing','Shanghai','Hangzhou','Guangzhou','Shenzhen'] data=pd.Series(dict_data,index=index_list) print(data*2)输出结果
-
数组运算支持numpy数组运算
dict_data={ 'Beijing':800, 'Shanghai':2000, 'Guangzhou':1000 } index_list=['Beijing','Shanghai','Hangzhou','Guangzhou','Shenzhen'] data=pd.Series(dict_data,index=index_list) # numpy数组运算 print(np.square(data))输出结果
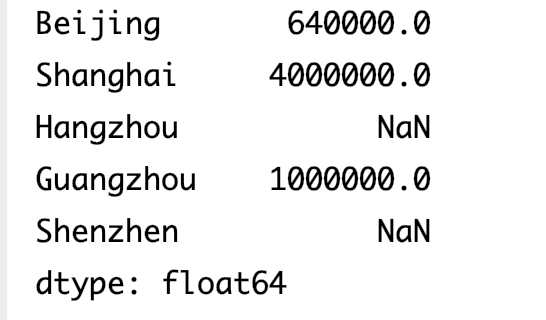
-
数组相加
dict_data={ 'Beijing':800, 'Shanghai':2000, 'Guangzhou':1000 } index_list=['Beijing','Shanghai','Hangzhou','Guangzhou','Shenzhen'] data=pd.Series(dict_data,index=index_list) dict_data_other={ 'Beijing':3000, 'Shanghai':1000, 'Guangzhou':2000 } data_2=pd.Series(dict_data,index=index_list) print(data+data_2)输出结果
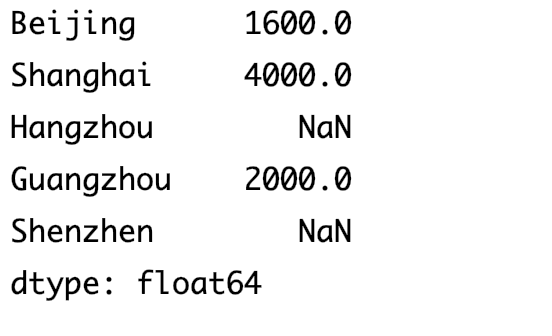
-
设定Series对象的name和索引名称
dict_data={ 'Beijing':800, 'Shanghai':2000, 'Guangzhou':1000 } data=pd.Series(dict_data) # Series对象的name data.name='City Data' # 索引的名称 data.index.name='city' print(data)输出结果

Pandas基础类型2 -- DataFrame
-
创建一个DataFrame类型的数据
dict_data={ 'student':['lilei','hanmeimei','madongmei'], 'score':[89,100,98], 'gender':['M','F','F'] } data=pd.DataFrame(dict_data) print(data)输出结果

-
指定DataFrame数据的列顺序
dict_data={ 'student':['lilei','hanmeimei','madongmei'], 'score':[89,100,98], 'gender':['M','F','F'] } data=pd.DataFrame(dict_data) data=pd.DataFrame(dict_data,columns=['gender','score','student']) print(data)输出结果

-
获取DataFrame数据的列名称
dict_data={ 'student':['lilei','hanmeimei','madongmei'], 'score':[89,100,98], 'gender':['M','F','F'] } data=pd.DataFrame(dict_data) print(data.columns)输出结果
Index(['student', 'score', 'gender'], dtype='object')
-
指定DataFrame数据的索引值
dict_data={ 'student':['lilei','hanmeimei','madongmei'], 'score':[89,100,98], 'gender':['M','F','F'] } data=pd.DataFrame(dict_data,index=['a','b','c']) print(data)输出结果
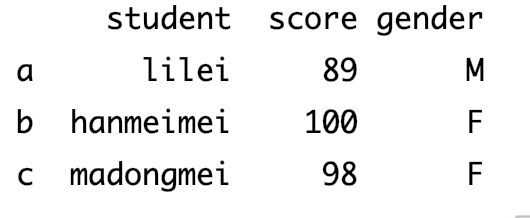
-
获取DataFrame某一列数据
dict_data={ 'student':['lilei','hanmeimei','madongmei'], 'score':[89,100,98], 'gender':['M','F','F'] } data=pd.DataFrame(dict_data,index=['a','b','c']) # 列的名称,获取这一列的数据 print(data['student']) # 第二种方式 print(data.student)输出结果

-
获取DataFrame某一行数据
dict_data={ 'student':['lilei','hanmeimei','madongmei'], 'score':[89,100,98], 'gender':['M','F','F'] } data=pd.DataFrame(dict_data,index=['a','b','c']) # 根据行编号 print(data.iloc[0]) # 根据行索引 print(data.loc['b'])输出结果

-
切片
dict_data={ 'student':['lilei','hanmeimei','madongmei'], 'score':[89,100,98], 'gender':['M','F','F'] } data=pd.DataFrame(dict_data) # 修改会反映到原始数据,修改行不修改原始数据 item=data['score'] item[0]=66 print(data)输出结果

想要一份副本不影响原始数据?
data['score'].copy() -
修改某一列的数据
dict_data={ 'student':['lilei','hanmeimei','madongmei'], 'score':[89,100,98], 'gender':['M','F','F'] } data=pd.DataFrame(dict_data) data['score']=666 print(data)输出结果

data['score']=range(95,98) print(data)输出结果

-
传入Series类型修改DataFrame数据中的某一列数据
dict_data={ 'student':['lilei','hanmeimei','madongmei'], 'score':[89,100,98], 'gender':['M','F','F'] } data=pd.DataFrame(dict_data) # 传入Series类型 score=pd.Series([100,90,80]) data['score']=score print(data) -
删除DataFrame数据中某一列
dict_data={ 'student':['lilei','hanmeimei','madongmei'], 'score':[89,100,98], 'gender':['M','F','F'] } data=pd.DataFrame(dict_data) # 删除分数列 del data['score'] print(data)输出结果

-
根据新的索引重新排列数据
dict_data={ 'student':['lilei','hanmeimei','madongmei'], 'score':[89,100,98], 'gender':['M','F','F'] } data=pd.DataFrame(dict_data,index=['A','B','C']) print(data) data=data.reindex(['A','C','B']) print(data)输出结果
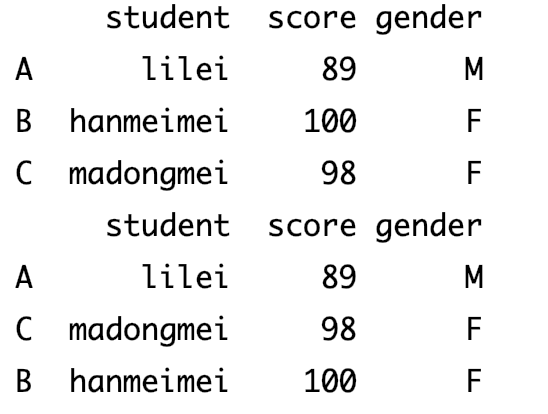
-
full_value
dict_data={ 'student':['lilei','hanmeimei','madongmei'], 'score':[89,100,98], 'gender':['M','F','F'] } data=pd.DataFrame(dict_data,index=['A','B','C']) # fill_value=9表示将多出的一行的空的值地方,填为9 data=data.reindex(['A','C','B','D'],fill_value=9) print(data)输出结果

-
将缺失位置通过插值法计算并补上内容
dict_data={ 'student':['lilei','hanmeimei','madongmei'], 'score':[89,100,98], 'gender':['M','F','F'] } data=pd.DataFrame(dict_data,index=['A','B','C']) # ffill 从前面数据计算插值,bfill 从后面数据计算插值 data=data.reindex(['A','C','B','D'],method='ffill') print(data)输出结果
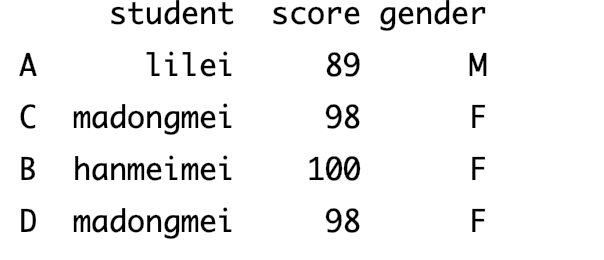
-
-
扔掉有缺失的数据的行
# 扔掉包含缺失的数据(NaN)的行,这一行有为NaN的数据 print(data.dropna()) # 扔掉全部都是缺失的数据(NaN)的行,这一行全是NaN的数据 print(data.dropna(how='all')) -
填充所有缺失的数据为一个值
print(data.fillna(0))-
按列填充缺失数据为不同的值
print(data.fillna({'gender':'M','student':'unkown','score':80}))
-
-
删掉某一行
data=data.drop('a') -
筛选数据
print(data[data['score']>=90]) -
从列表中筛选数据
