

CVPR Workshop 2019
Tiantong Guo, Xuelu Li, Venkateswararao Cherukuri, Vishal Monga
章理登 2020-03-23
简介
该文章是NTIRE 2019去雾竞赛中的冠军,其核心之处在于给出了两个新网络At-DH和AtJ-DH并且在 NTIRE2019和NTIRE2018的数据集中得到了较好的指标。该文章是实验性质的论文,没有太多的理论和观点的分析,只以高指标为目标。
Motivation
近些年的使用深度学习方法去雾的文章中的很大部分使用了大气散射模型来去雾
即估计和
,结合有雾图
,得到去雾结果
。
由于很难获得真实成对的有雾图和无雾图
,在训练中经常使用合成数据集。而在真实场景中,雾的浓度可能要比大多数合成的有雾图像中的雾浓度要浓。因此认为NTIRE2019提供的数据集代表了真实场景的去雾。
Model
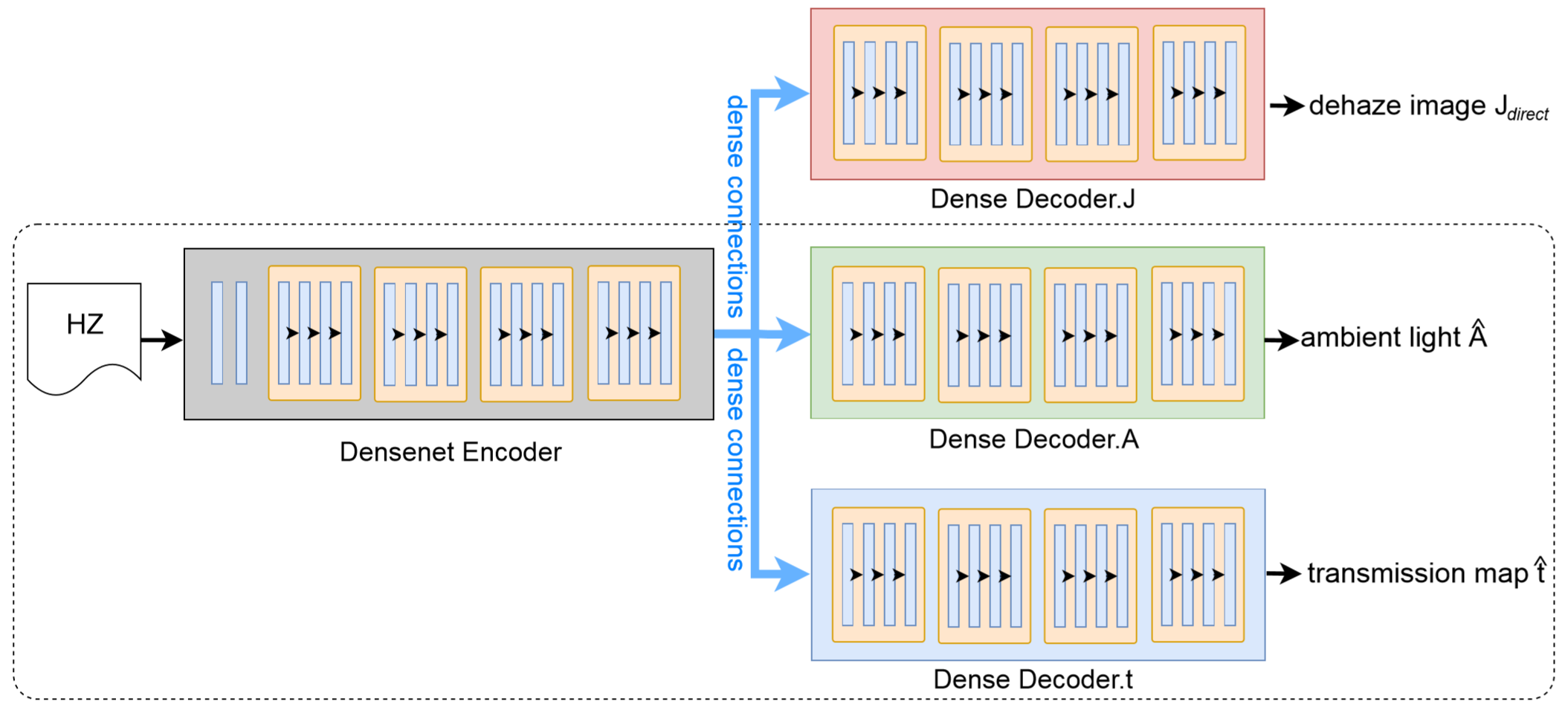
下图中虚线框内的即为At-DH,整体为AtJ-DH。可以看出,AtJ-DH比At-DH多了一条J解码器的分支。

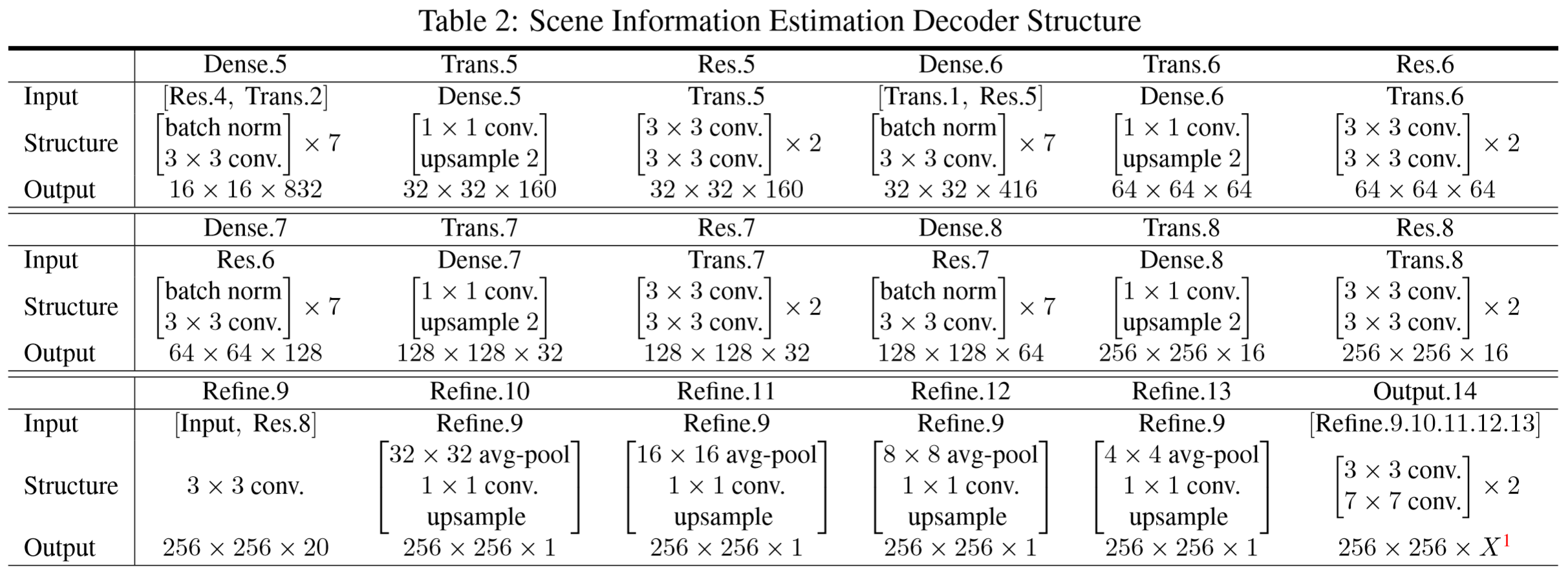
可以看到Table2的最后一行,表示Refine模块。Refine模块是对Refine.9层的结果进行了不同大小的池化(32×32,16×16,8×8,4×4),在上采样到相同尺寸后再进行了卷积。文章表示这个操作将图像信息以不同比例进行合并并且能够消除去雾中的光晕和伪影。
At-DH
At-DH由一个共享权重的编码器和两个解码器组成,它们都是基于DenseNet的。

其中和
表示Decoder.A和Decoder.t的输出结果。
At-DH的损失函数如下:
其中为平衡系数;
表示为:
其中由公式(2)计算得到,而
由以下公式计算获得:
其中为Gth无雾图。
另外
可以表达为:
其中表示
中的ReLU1_1,ReLU2_2,ReLU3_3层的输出结果。
loss解读:一个已知的有成对的有雾图-无雾图的数据集是有两个确定的图像,一个是有雾图,另一个是无雾图
。在At-DH网络估计了
和
的情况下,使用
,
,
可以计算
,使用
,
,
可以计算
。得到的
、
可以和
、
计算
和
损失。
AtJ-DH
为了克服在浓雾中估计A和t的困难,在At-DH的基础上开发了AtJ-DH。J这个分支是用于协助估计A和t的,其并不作为最后的预测结果。其中Decoder.J结构和Decoder.A的一致。

把Decoder.A、Decoder.t和Decoder.J的输出分别表示为:
其中和
是不同的,
是由Decoder.J直接得到的,而
是由
和
计算得到的。
在训练的过程中,AtJ-DH通过三种不同的损失函数组合在不同的阶段来训练网络。
- 第一步,通过最小化以下损失函数训练Decoder.J:
第一项为普通的损失,第二项为类似于公式(6)的VGG损失。
- 第二步,通过最小化以下损失函数训练Decoder.A和Decoder.t:
即和At-DH的损失函数一样。
- 第三步,通过最小化以下损失函数联合训练Decoder.A、Decoder.t和Decoder.J:
通过结合Decoder.J,Decoder.A和Decoder.t可以学习基于训练Decoder.J引入的Gth信息的指导,以重构模糊图像。 无论是At-DH网络还是AtJ-DH网络,结果均使用公式(2)得到去雾结果。
数据和训练
数据集
- 训练集1:NTIRE2019
- 训练集2:NTIRE2018
均由造雾机生成雾气,然后由相机拍摄。它们均有室内外图像。其中NTIRE2019有非常浓的雾,而NTIRE2018有常见浓度的雾气。
由于文章参加了NTIRE2019的竞赛,而NTIRE2019有非常浓的雾,NTIRE2018只有一般浓度的雾气,所以文章对NTIRE2018进行了加雾处理。
加雾公式:
表示加雾后的图像;
表示NTIRE2018的有雾图像;
对于室内图像,
,对于室外图像,
(偏蓝);
均匀的分布在
之间,但文章并未说明具体是如何分布的。
在训练中,将数据集切为512*512大小的块。
并添加了以下两种数据增强的策略:
-
水平翻转,旋转90度、180度、270度
-
缩放到原始图像的70%、80%、90%;
-
测试集和训练集同分布
训练设置
文章在这个部分重点介绍了训练过程:
-
Stage 1-编码器的预训练:先将编码器和单个解码器组合来进行训练,解码器的输出是无雾图
。损失函数为公式(10)。在这个阶段,使用NTIRE2019和加雾后的NTIRE2018训练80个epoch。
-
Stage 2-At/AtJ-DH训练:对于At-DH,使用公式(3)/(11)作为损失函数,并拿Stage 1中训练好的编码器和两个新解码器合并为At-DH网络;AtJ-DH训练也同理,损失函数如公式(12)。在这个阶段,使用NTIRE2019和加雾后的NTIRE2018训练50个epoch后,再使用NTIRE2019训练70个epoch。
其他训练参数:
- 优化器:Adam;
- 初始学习率:
;
- 每35轮学习率衰减到原来的70%,并再Stage 2中重置;
在训练输出的结果上,应用了的IRCNN去噪器来提高表现。在测试阶段,At/AtJ-DH+表示在At/AtJ-DH的基础上添加了IRCNN去噪器。
对比和测试
测试指标
- PSNR
- SSIM
指标对比
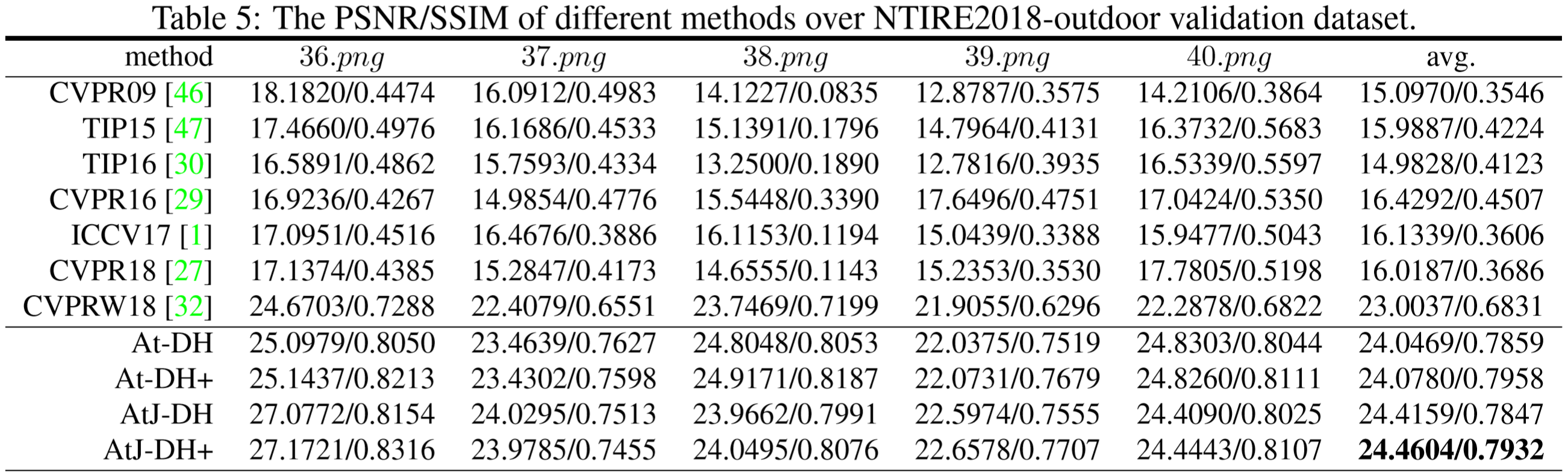
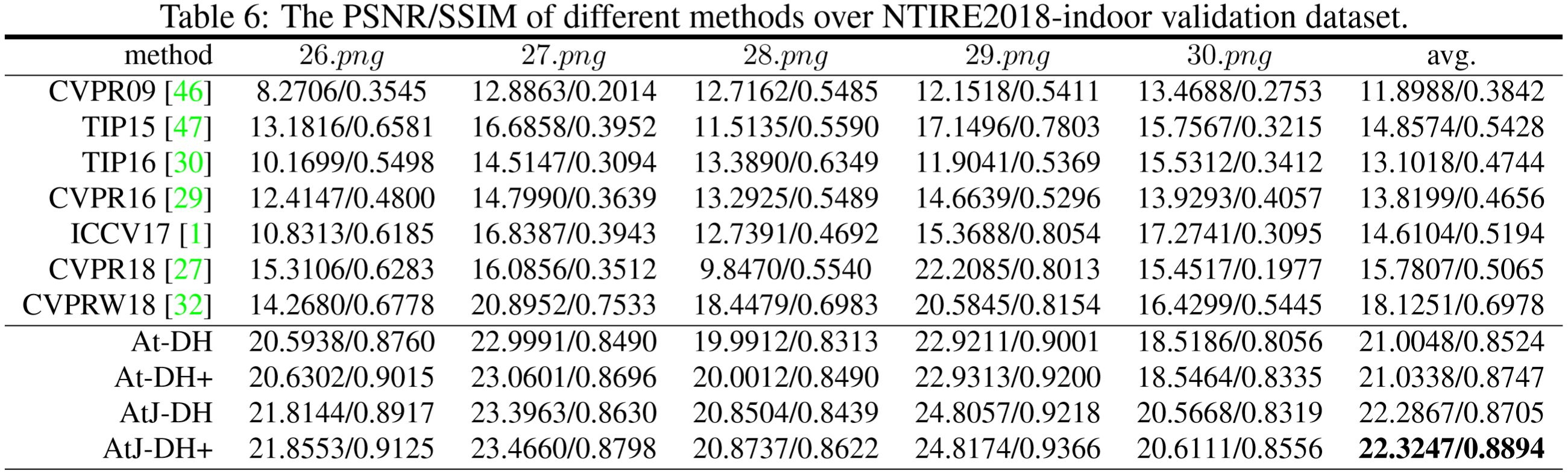
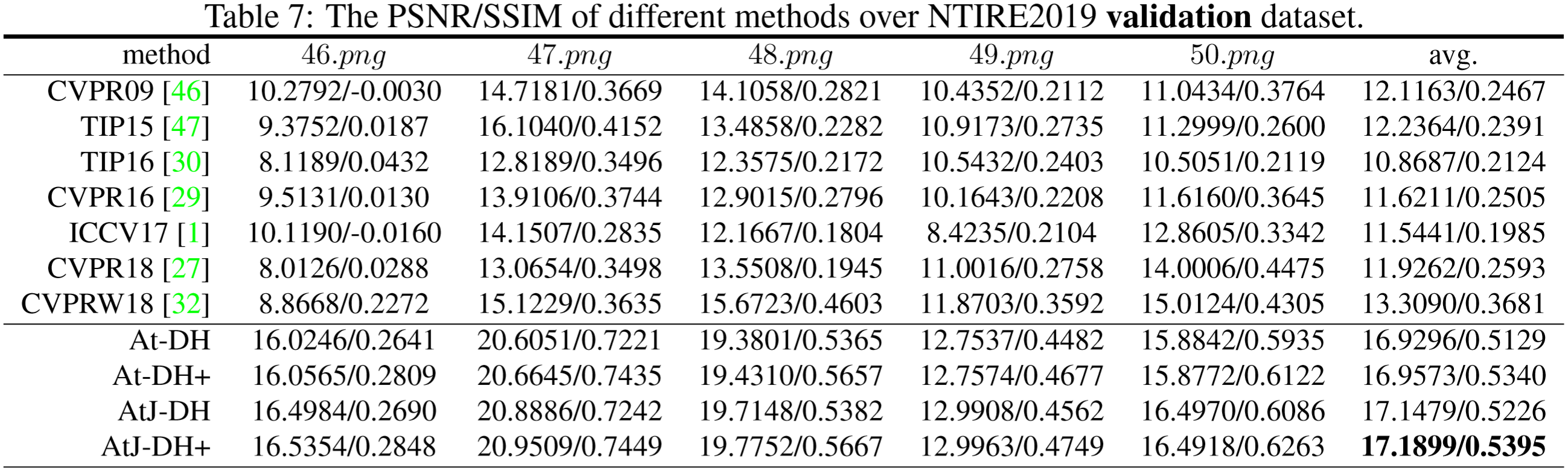
这里的指标均为验证集指标,由于NTIRE2018和NTIRE2019均为竞赛数据集,测试集的Gth未放出,故无法对量化评估测试集。
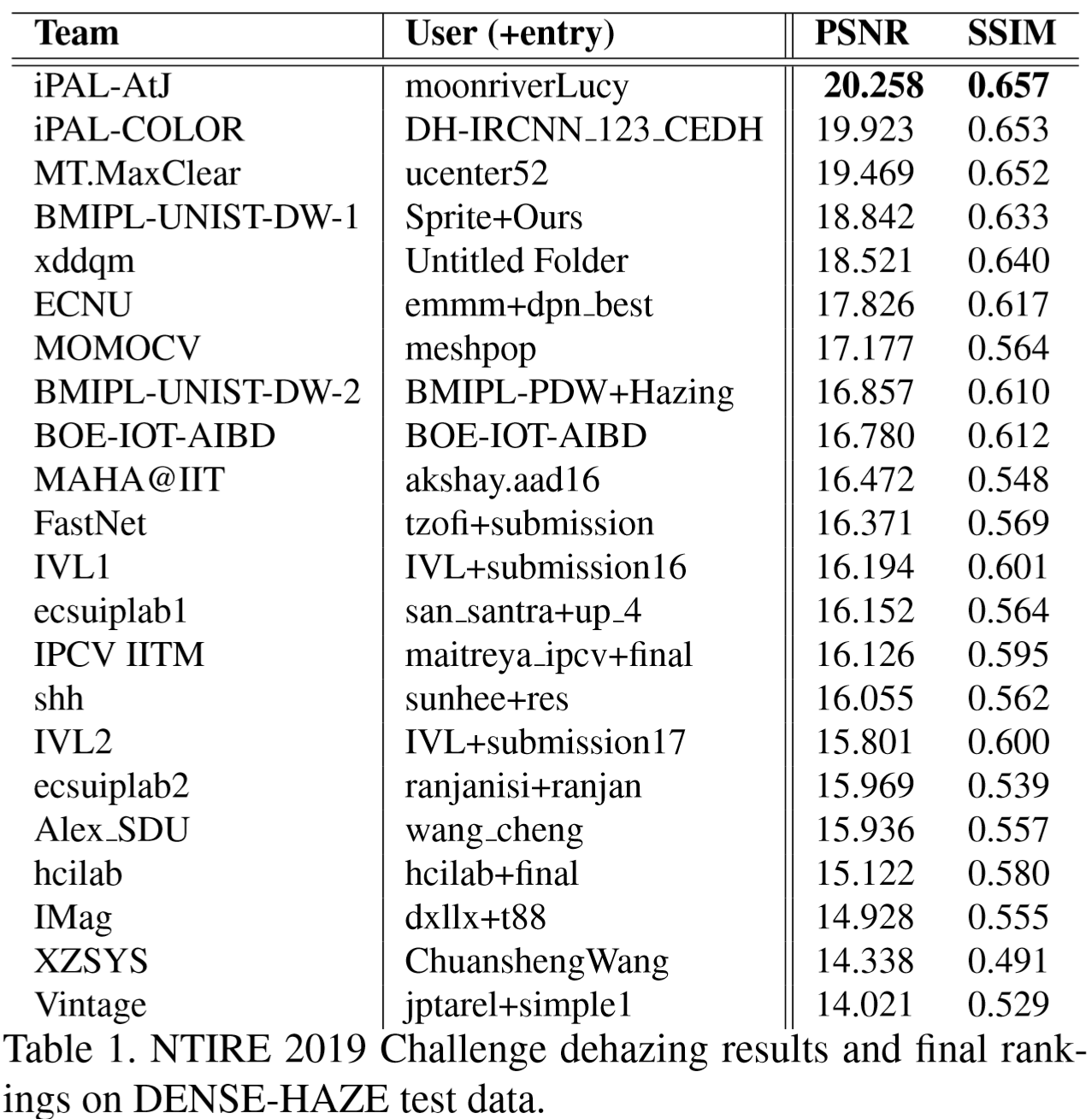
结果展示




