

这一篇文章我们将了解机器学习的一大类问题,即生成模式。 对于人工智能基础理论比较熟悉的同学都知道机器学习模型分为判别式和生成式模型两个范式。 判别式模型典型的如各种分类器, 所做的事情是一个函数映射,从一个输入信息上得到0,1 这样的分类结果。而生成式模式的本质是得到一个概率分布函数,通过抽样可以得到新的没有见过的完整数据,比如你给模型学习一堆人脸, 它不仅可以判断是不是人脸,还可以输出一张它没见过的人脸。
当下技术的主流, 是判别式的模型,因为它们简单直接,学习效率高,可以直接给人们提供比如人脸识别,疾病检测这样的实用功能。 然而生成模型却代表了AI的未来 ,因为它真正考验模型对世界的“理解”, 所谓真正的理解就是你能自己造出来, 能够生成一张脸的模型,显然比能够判别一张照片是否是人脸的模型更懂人脸。
而生成模型非常实际的意义,是它可以帮助我们把积累的海量无标注数据利用起来,也就是我们通常说的无监督预训练。因为在生成类任务里,神经网络无需提供标注数据,而是可以使用大量未标注的数据,比如行车记录仪记下的视频,你只需要把视频切割成无数帧,每一次根据过去的历史预测下一帧就可以预训练网络,为后续任务提供基础。 这种预测性的学习, 被Yan Lecun 称为自监督学习, 被认为是利用真实世界的海量数据,自主学习知识的最有前景框架。
而一类最典型的生成问题,是刚刚提到的视频或场景预测, 也就是模型看着一连串发生的场景,预测下一刻会发生什么,或者根据在同一场景下的不同角度画面, 预测一些未知角度的画面。要知道这体现了大脑最重要的工作原理, 预测编码原理, 我们自己时刻不停的预测未来会发生什么, 是我们智慧的本本源。 同时, 它也是具备高难度的任务, 当你转过一个角度看物体, 它会变成什么样, 这体现了你对空间远近,透视, 物体的连续和分割,都要有较好的理解。 也就是说, 当你学会了预测, 就掌握了真实世界的规则。
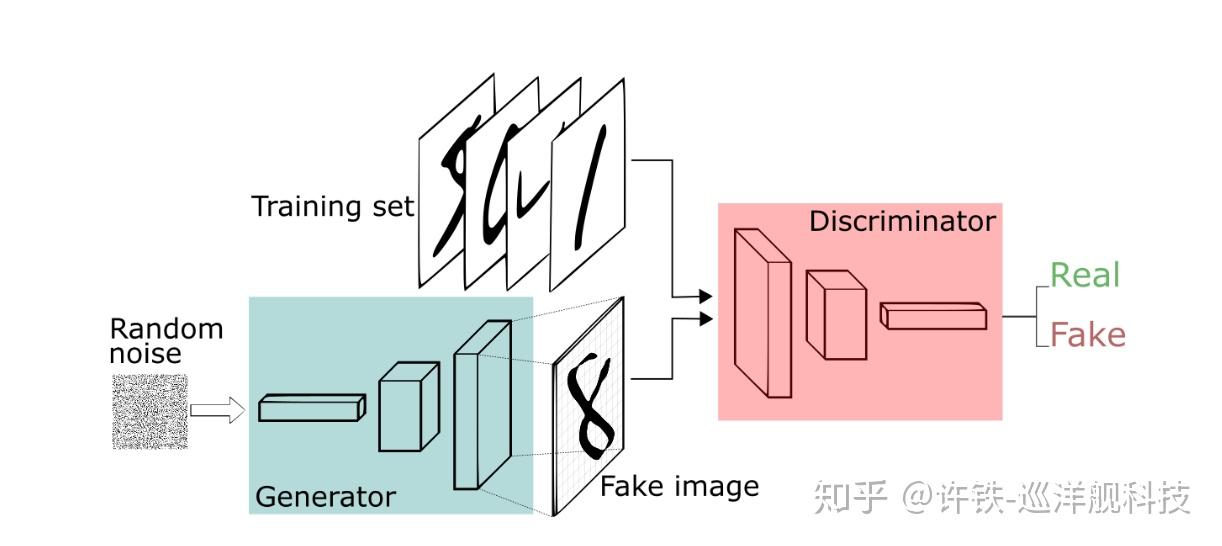
生成式模型最经典的工作莫过于自编码器如著名的变分自编码器VAE,以及这几年十分火爆的GAN, 对抗生成网络。然而其想象力却远不止此, 以下, 我就介绍一篇Science 论文,来说明一个这类任务的鲜活实例。
Neural scene representation and renderingscience.sciencemag.org场景的表征和预测是生物职能的一个关键所在,而这类AI模型的训练需要海量标注数据, 一个解决方法是使用大量直接从传感器产生的无标注数据, 通过不停预测不同视角会观测到的图像, 来学习场景的表征, 并且生成未看见的角度的画面。 这个GQN(Generative Query Network)网络能够有效的在无标注数据里学习人类知识, 因此在通向机器自主学习和理解的角度上迈进了一步。
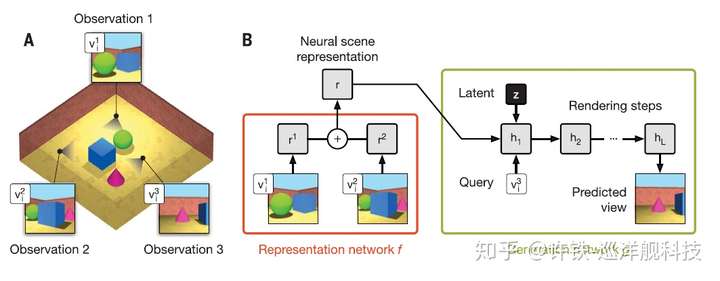
整个任务如上图所示, 你在一个包含简单几何体的屋子里观测不同角度的画面, 然后试图预测那些未见过的角度(如同婴儿的探索)。
这个模型分成前后两个主要部分,前一部分生成场景的表示, 这部分接收从不同角度收集的图像数据, 把它们叠加在一起生成一个场景的表示r ,后一部分利用这个表示r生成预测的图景
, 这部分的工作机理类似于我们熟悉的自注意力模型(self attention)。如果你要预测某个角度的观测结果, 你就把这个角度作为一个问题 (query)输入给网络, 这部分会在对整个场景的表示 r上得到与之最相关的那部分信息, 最终通过一个LSTM网络进行若干步迭代(h1, h2, h3...hn)生成最后的图像。模型中z这个隐变量主要是控制生成图像包含的可变性(方差)。
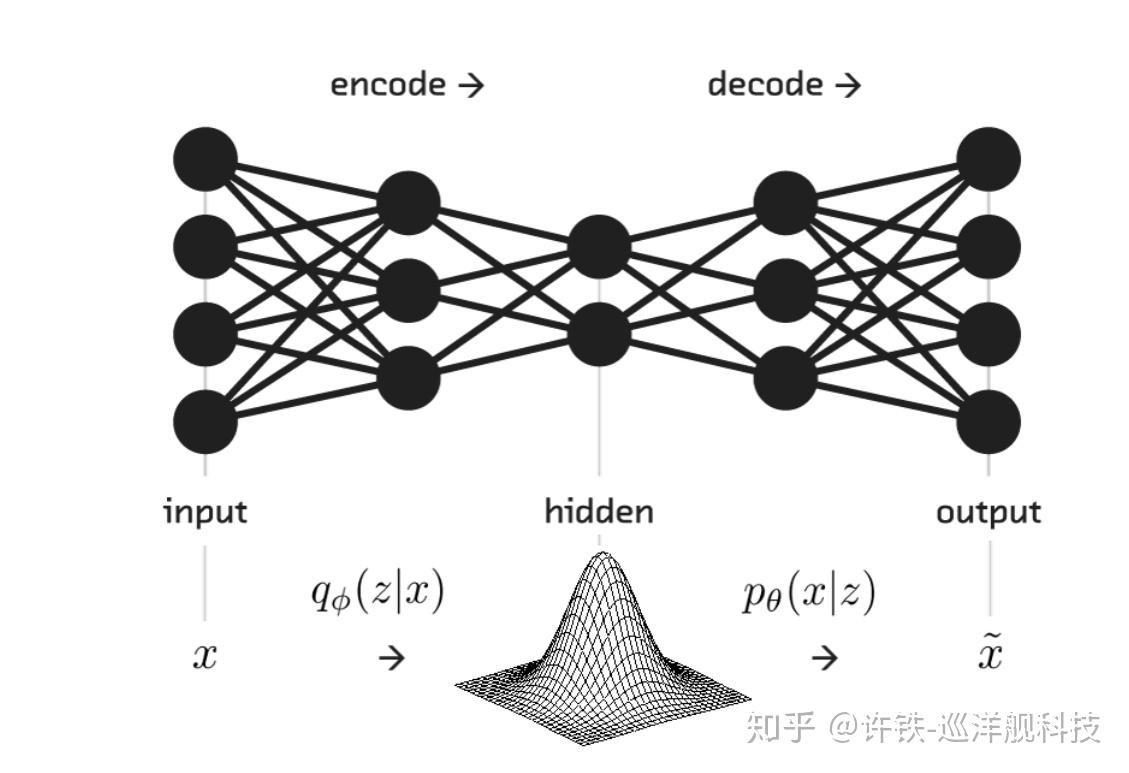
如果熟悉变分自编码器VAE的同学可以立即把上述框架与之对比,你会发现两者有着很多相通之处, 首先表征提取编码的网络对应VAE前面的编码器部分,都是用到某种前馈网络结构(此处是CNN), 然后生成网络则对应了解码器部分。 那么GQN相比VAE的关键提升在什么地方呢? 首先是它的编码器并不是一蹴而就, 而是把不同角度的表示 叠加在一起生成最终的表示,也就是说把在同一场景下不同角度的场景采样加和在一起,这一点保证编码器得到的表示具有场景的全部信息。 而更加重要的是, GQN的生成网络采用了这种类似自注意力的机制使得结果的提取更加精准。并且通过LSTM的迭代生成最后的结果,这意味着生成器具有更大的“想象空间”。 因为LSTM可以把世界有关的知识(先验)比如各种和颜色, 形状有关的统机规律包含在它的权重(RNN的动力学)里, 在迭代的步骤里, 相当于生成器进行了思考,得到最后的结果。
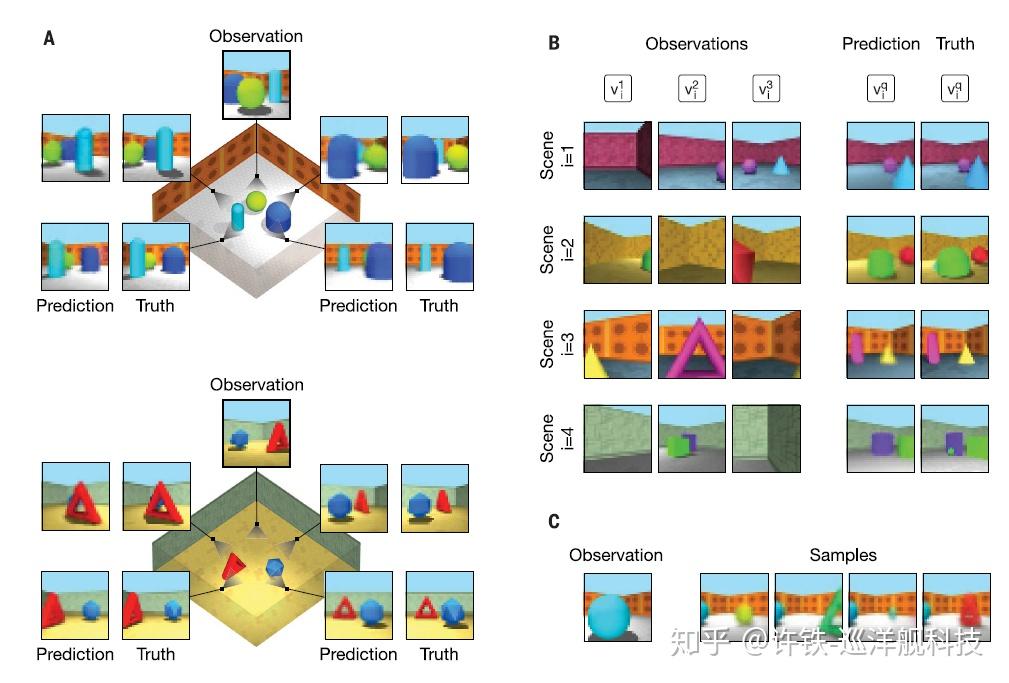
我们可以看下这个GQN的预测效果, 可以看到GQN生成的场景几乎和真实一样,无论你如何转动角度它都知道同一场景下该如何变化。 显然它掌握了在一个3D场景下, 不同的视角变换在真实世界里的对应关系, 而这正是真实世界的几何和物理知识本身,也就是说,这些知识已经进入到了神经网络的权重里。
为了进一步验证这一点,我们可以分析神经网络的表示。 通过TSNE的分析,我们可以看到GQN对不同场景的聚类效果远好于VAE, 也就是说GQN学到了不同场景的本质, 而不是在一个平均化的模板上对每个特定场景修修补补(VAE无法分出不同场景)。
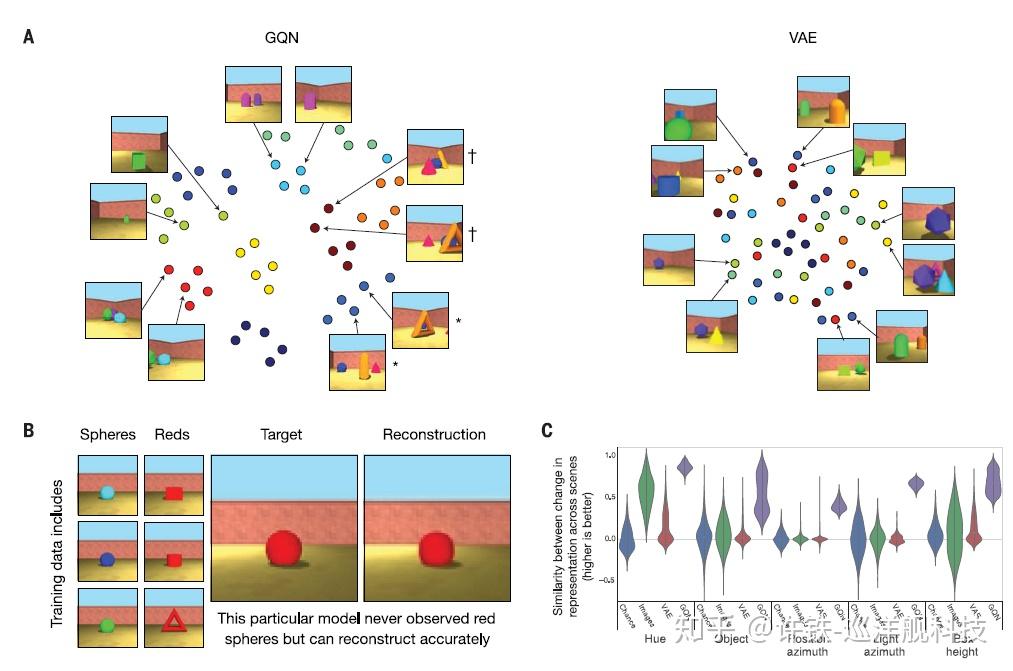
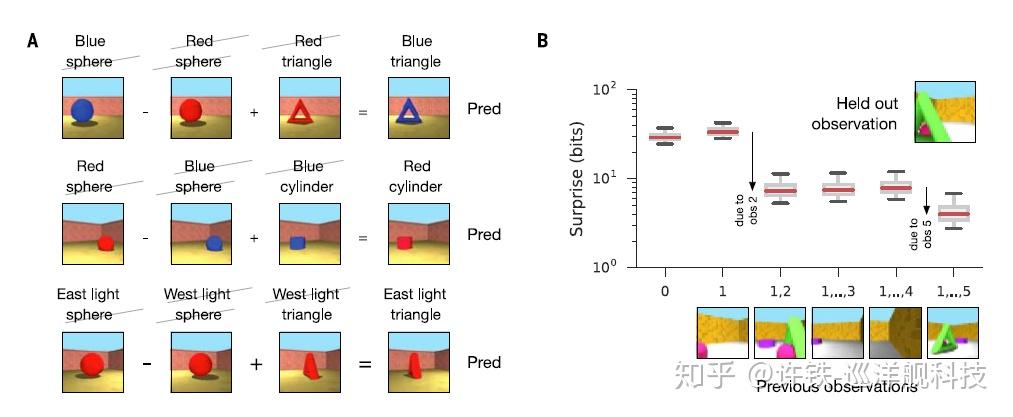
更加有趣的是, GQN生成的表示几乎可以对场景的不同元素做“代数运算”。 我们把不同画面对应的表示提取出来, 然后对它们做代数运算, 然后用生成器得到此时代数运算后的表示对应的图像。 比如红色的球减去蓝色的球, 加上红色三角 = 蓝色的三角。 红色的球减去蓝色的球加上蓝色的方块 = 红色的方块。 上述结果完全符合直觉,这说明GQN生成的对场景的表示是因子化的(factorized), 不同的因子间处于解耦的状态(disentangled), 这对于掌握一个场景的构成方式(composition)和提高模型的可解释性(explainable)具有重要的意义。
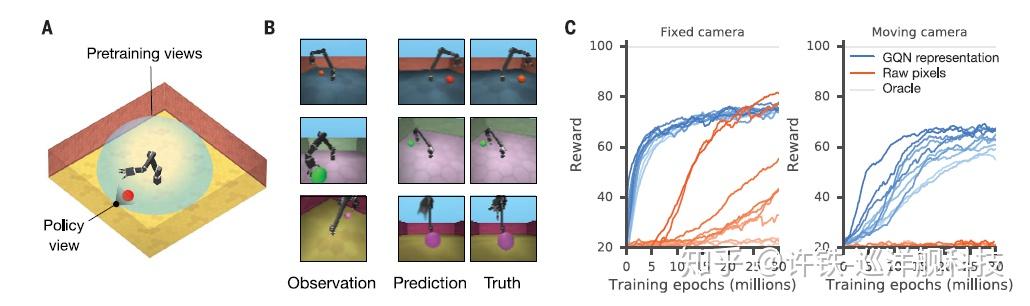
那么学习到的表示除了预测生成未见过的图像,还有什么应用吗? 在文章开头讲过,这些学到的表示正是后续任务,尤其是强化学习任务的基础! 因为通过这种无监督学习,神经网络已经掌握了这个世界的几何,物理知识,因此在做相关任务时候更加得心应手,如在刚刚的场景预训练过的GQN紧接着进行深度强化学习控制一个机器手, 我们会发现经过预训练的网络(下面右图蓝线)比起没有经过的好了一大块。 这说明因为预训练,我们获得了关键性的先验知识!(Inductive bias) 。你还记得Yan Lecun的蛋糕的比喻吗? 强化学习是蛋糕上的樱桃,监督学习是蛋糕的奶花, 而无监督学习是蛋糕的真正实体! 那么这三部分显然不是孤立的, 生成式的预测任务, 使得蛋糕的实体被开发出来, 从而摘到樱桃不再困难!
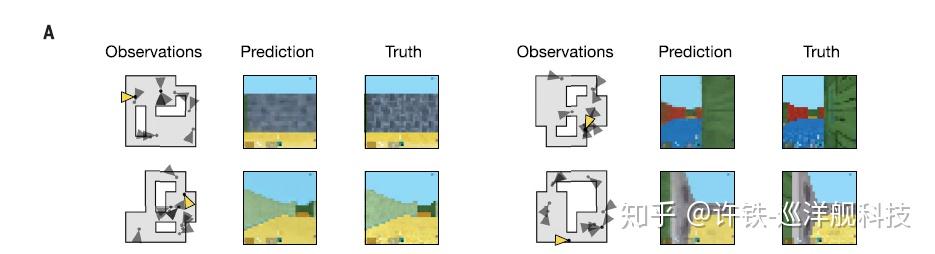
上述的模型也可以被用到导航相关的任务,比如经典的走迷宫任务,这一类任务代表着典型的非完全马尔可夫决策框架下,也就是每次我们只观察到地图的一个侧面,而我们需要把不同的侧面拼合到一起才能形成对整个空间的理解,从而预测几步之后可能出现的画面。 不难看出这与不同角度的场景预测任务的相通之处。
其它有趣的预测生成模型:
VAE-GAN: VAE和GAN是经典生成模式的两大家族, 应该说两者在使用上各有千秋, 自编码器VAE善于寻找不同数据背后其支配性的隐变量, 可解释性好, 但是生成效果往往比较模糊。而GAN反过来, 比较黑箱难以解释, 但是生成效果好 。 VAE-GAN试图把两大家的优势结合在一起,先构建一个VAE, 再把VAE生成的图象进入一个GAN的结构里, 与真实图象比对,用一个判别式分辨真伪。
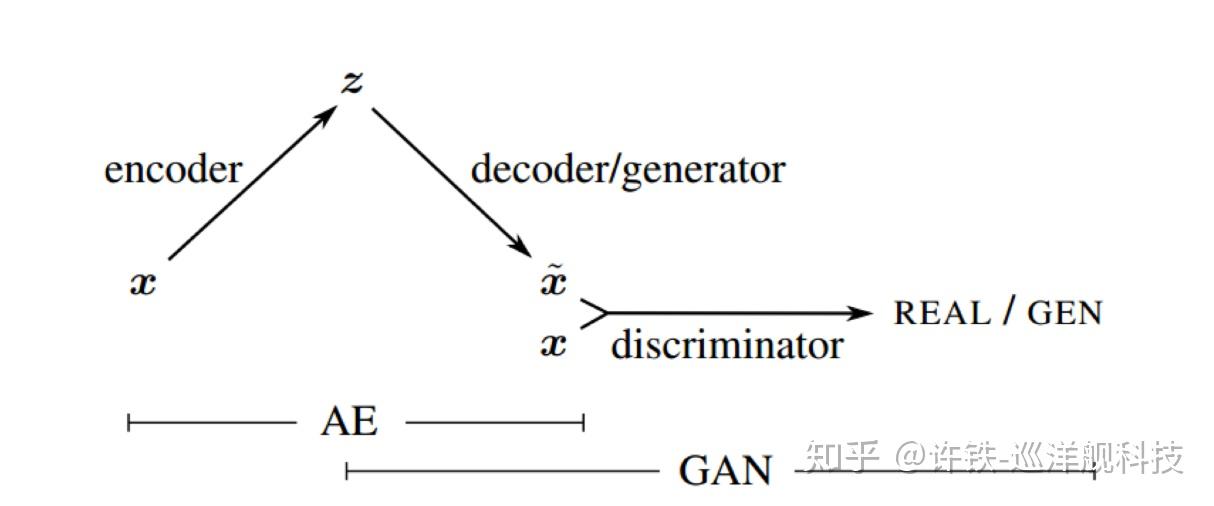
VAE-GAN的核心主要体现在其loss function里,同时包含了VAE和GAN的loss。
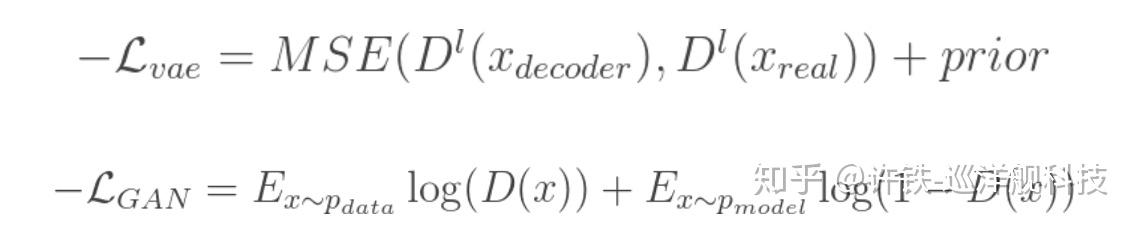
最后的效果如下:

更多内容参加博客What The Heck Are VAE-GANs?
https://towardsdatascience.com/@chinokenochkan?source=post_page-----17b86023588a----------------------towardsdatascience.comCortical Modular Networks :既然预测编码是大脑神经计算的首要原理, 那么我们显然可以模拟大脑的类似结构来构建一个网络, 一篇来自NIPS19的神文 Visual Sequence Learning in Hierarchical Prediction Networks and Primate Visual Cortex 就提出了一个相应的结构。 这个网络采用类似LSTM和CNN结合的堆栈结构层级化的处理信息最终进行视频的预测, 这是对视皮层结构的直接模拟
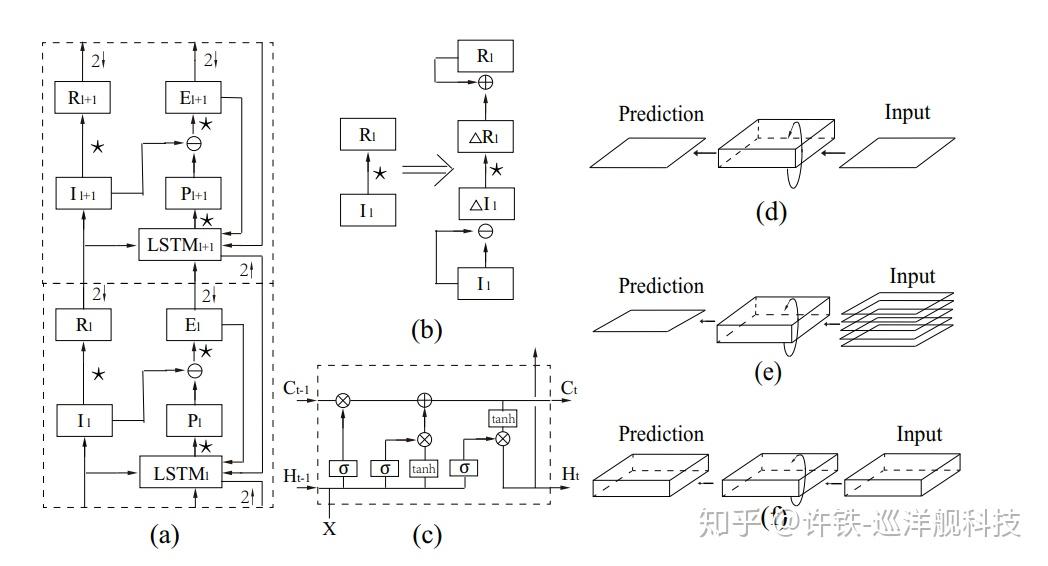
这个看似复杂的模型其实有一个非常基本的假设, 那就是每一层的输出都在尽可能的预测上一层的输入,大脑每一个模块无论抽象层次高低都执行预测编码(背后的计算原理相似)。 既然是预测, 就一定要包含对过去的记忆, 因此就包含了一个LSTM网络模拟这种记忆, 同时,既然是一个层级化的网络, 我们要对信息进行一级级的抽象,这个工作是由CNN完成的, 因此每个层次就都包含了CNN对特征进行处理和LSTM对信息进行记忆。 每一层接受上一层的输入同时也将自己的输出和预测误差回传给上一层,使得学习变得更加可行。
最终这个模型可以实现State of the art的视频预测性能。 这个模型内部生成的表示可以直接和视皮层的神经活动进行对比, 呈现出有趣的相似性。
生成式模型和预测试编码结合的AI前景是无限的, 因为它可以源源不断的利用日常生活的海量数据, 真正实现自主式的学习。 对于AI真正掌握数据冰山背后真实物理世界的规律,意义巨大。 这样得到的预训练模型,可能掌握对后续AI任务关键的先验知识,从而成为构建更强大AI的基础。 也希望更多的同学可以关注到这一领域。
最后分享一个铁哥3月30号的 live 讲座 ICLR论文看脑科学如何助力人工智能:
ICLR论文看脑科学如何助力人工智能www.zhihu.com
从中你可以了解如何用强化学习构建一个适应各种不同环境任务的导航系统,制造一个“聪明”的人工小鼠。
