

给2019年度我最喜欢的RL工作写个pr文。
关于BAIR上周的blog介绍可以看:
https://bair.berkeley.edu/blog/2019/06/10/pearl/bair.berkeley.edupaper:
Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variablesarxiv.org已开源:
katerakelly/oystergithub.com
这是BAIR在ICML 2019上的工作,在meta-RL这个track上主要的contribution在于,提出了一种新的insight来解决元学习中任务的学习样本利用率不高的问题。
Learn to learn作为一种利用过去学习的任务经验来学习新的任务的机制,主要的瓶颈在于:
- 如何筛选用于meta-training的任务,从而给new task更多的有效参考
- 如何从过去学习的任务中针对新的任务获取有效的信息
- 如何对新任务的uncertainty作出更准确的判断
这篇工作,Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variables,主要用task encoding的方法来解决第二个和第三个问题。
这篇文章会从background讲起,加上一些我对paper model (idea)的理解,以及总结它的insight,希望能给大家更多启发。
1. Background
Background这部分我不会详细讲述。仅作为引入,有兴趣可以详细阅读源码。
POMDP
这篇工作的主要idea来源于POMDPs的学习过程。
目前POMDPs比较有影响力的求解方法,是通过不断地推断agent所处的状态实现的。简单来讲,在无法获知所有环境信息的MDP过程中,agent通过积累的observation经验,来进行state的预测,从而提出了一个belief state的概念。Belief state代表的是agent对现在所处状态的一个概率分布预测。
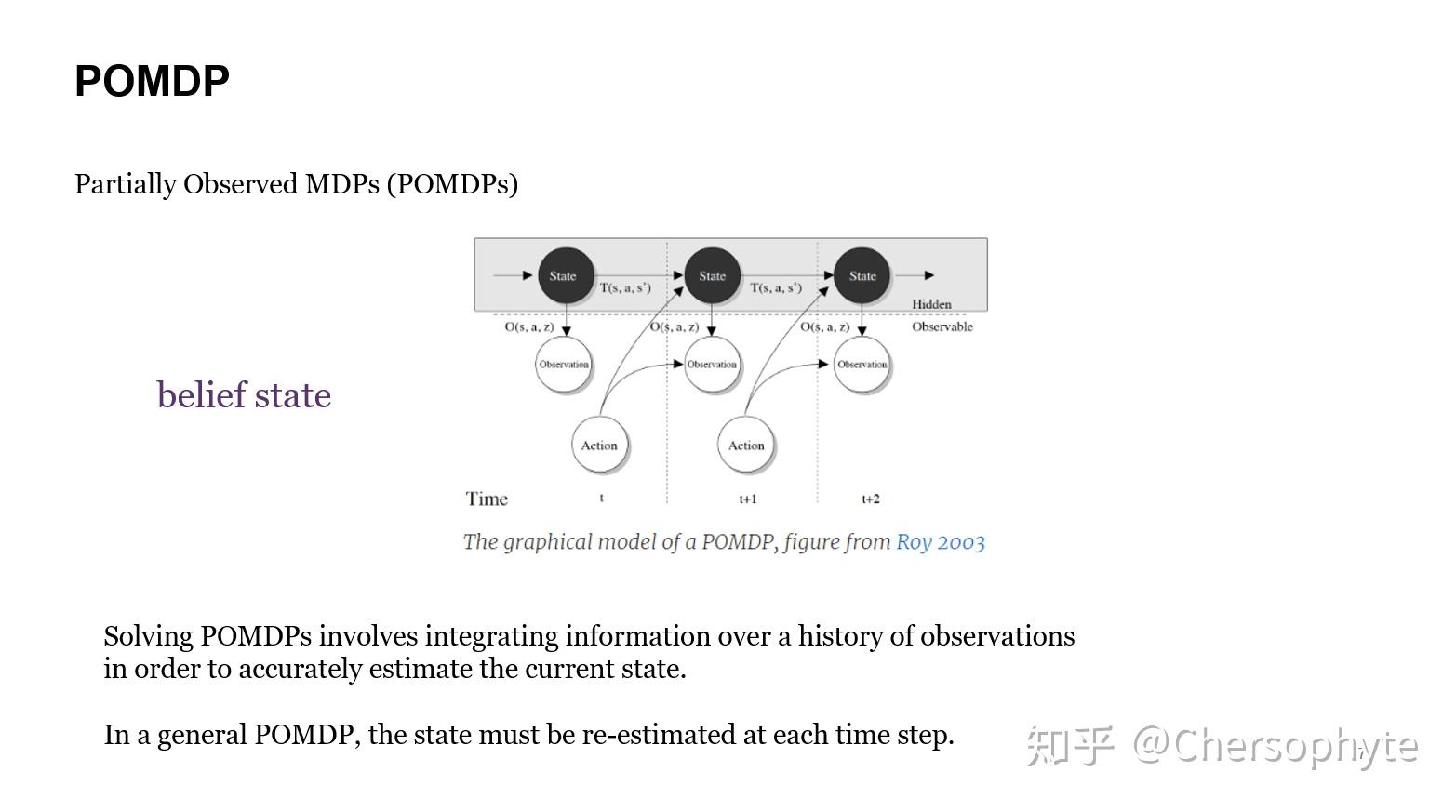
在POMDPs的学习过程中,agent在每个time step依靠积累的经验更新belief state。
对于详细的学习过程,这篇文章不再多说,因为这个工作主要只是使用了POMDP这种推理与学习两个过程分开进行的思想,将POMDP中的belief state替换成belief task。
Soft Actor Critic
SAC也同样是这个组的工作,作为一种off-policy的RL算法,跟state-of-the-art的On-policy Policy Gradient算法 (PPO)相比,极大地缩小了所需要的学习样本数量。
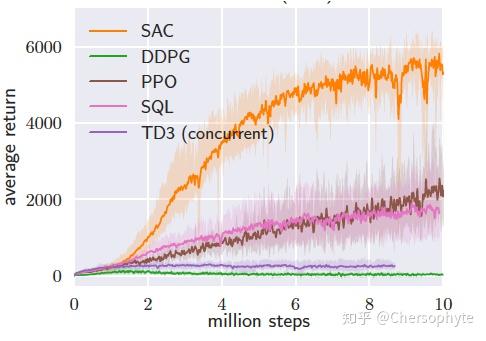
SAC的主要思想已经有很多文章来进行解读了,我这里只对最核心的idea稍作解释。便于理解这篇based on SAC的工作。
SAC中的soft,利用了最大熵 (maximum entropy) 的思想来实现。在优化agent的reward的同时,让agent的exploration策略带有一定的带宽,不会快速收敛到sub-optimal的解中。这样的思想也有利于更多optimal policy的探索。

2. Problem(Motivation)
这篇工作中的Meta-learning的流程为,通过Meta-training过程,对过去积累的tasks experience进行encoding,相当于train出一个task encoder。
随后,在Meta-testing的过程中,利用encoder来encoding新任务的关键信息,并在学习中不断地更新对新任务的判断,最后,使用encoder返回的信息进行新任务的learning过程。
BAIR的博客中有一段描述这个过程非常生动,我直接粘贴过来:
For example, if you discover a pitaya (dragon fruit) for the first time and want to eat it, you might follow your policy for eating mangoes and decide to slice the fruit with a knife. This is certainly a good exploration strategy that leads you to the delicious speckled flesh inside. Since the flesh looks and feels much more like a kiwi than a mango, you might then switch to your kiwi-eating policy and grab a spoon to dig out the treat.

在Model部分,我会分为两块详细解释PEARL的运行机制。
3. Model
Meta-training
在这一块,他们首先将一个task分割为三个部分,初始的state分布,state transition的分布以及奖励机制。
在学习其中一个任务的工程中,不断积累transition的history experience,这部分的积累,就是用来进行任务推理的context .
随后,利用Gaussian factor来对 进行encoding:
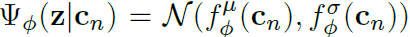
其中的function 为带参数
的nn。
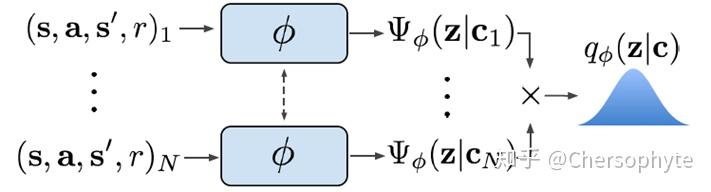
在积累到N个task之后,可以利用一个permutation-invariant function,来表示 与
的关系。即输入一个新的context集合,由样本1到N训练出来的encoder
,能生成encoding后的
。
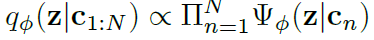
整个流程可以表示为:
而更新 的过程,使用了critic的the Bellman update:
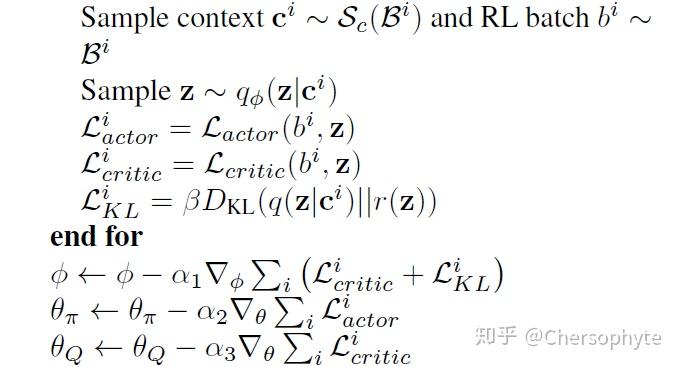
Meta-testing
完成encoder的training过后,面对一个新的任务,PEARL就可以非常自然的在学习中加入encoded过的信息,从而利用过去学习过的任务进行新任务的学习,即完成了Learn to learn。
整个过程可以梳理为:
- 探索新的任务,用探索的context,从encoder中获取belief task,即
- 利用belief task的值,即可以获取过去的经验,在经验的基础上学习
- 学习完了,这时候又积累了context,可以再次更新belief task(即后验分布)
- 循环2-3
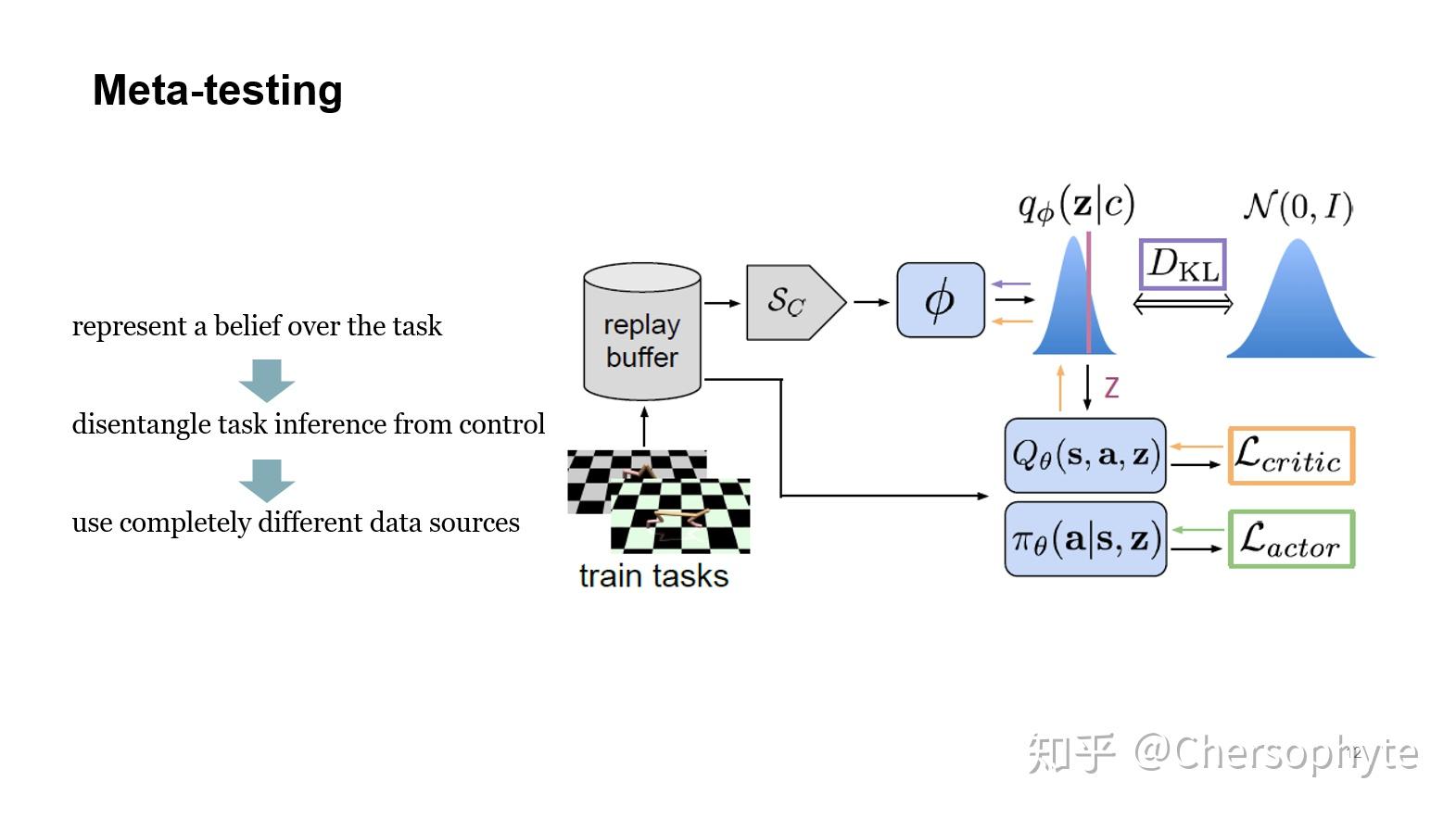
这个工作的亮点在于,分离了task inference与agent learning的过程,与POMDP中state inference和MDP learning相似,所以可以说,是Meta-Learning as POMDP.
实现的细节部分可以仔细看一下他们公开的源码。
4. Results
最后,在Experiments中,尤其是对于奖励稀疏的RL学习任务,PEARL表现出了相比以往的Meta-RL算法更好的结果。
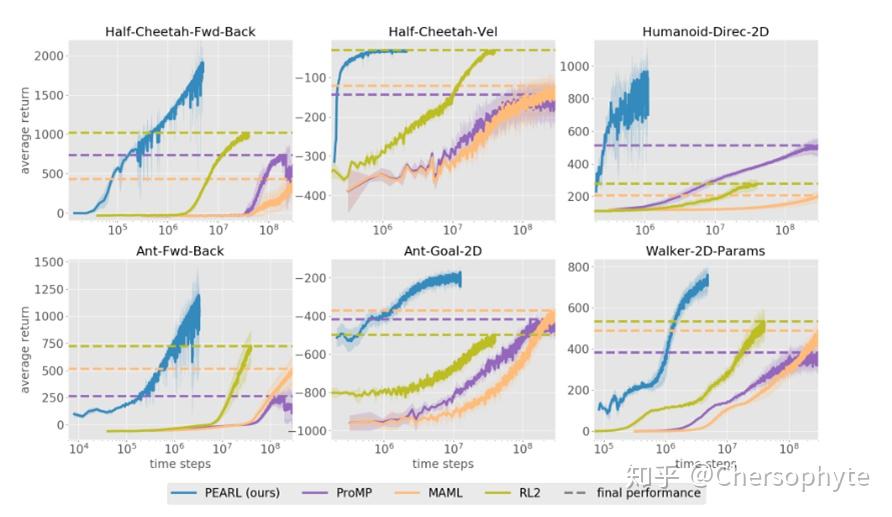
实验中还比较了meta-testing过程中adaptation在不同游戏中的差距。
5. Summary
总结来说,这篇工作将task inference与learning过程分离的idea来自于POMDPs的探索过程,通过这样的分离,使得meta-RL中对样本的利用率提高了。但是元学习无法回避的对样本的依赖仍然没有解决,如何对learn to learn中的training sample进行选择,可能仍然是需要更多探索的问题。
