

Flink简介
Apache Flink是一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态计算。 可部署在各种集群环境,对各种大小的数据规模进行快速计算。
- 处理流程
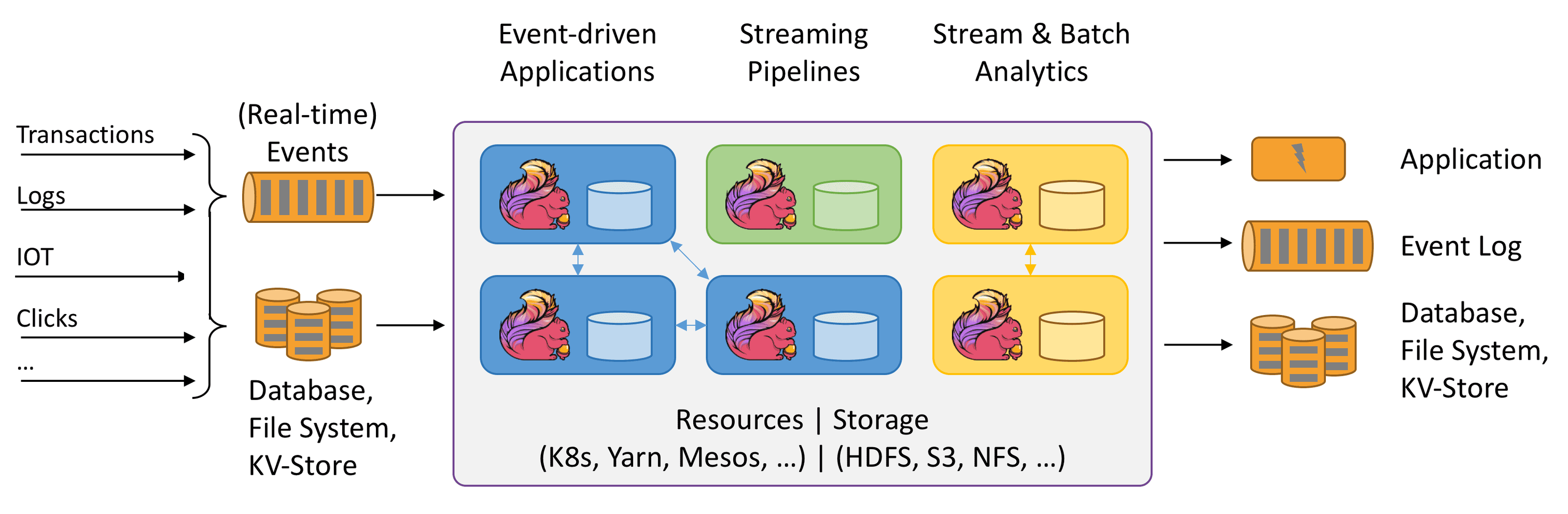
- 核心组件:
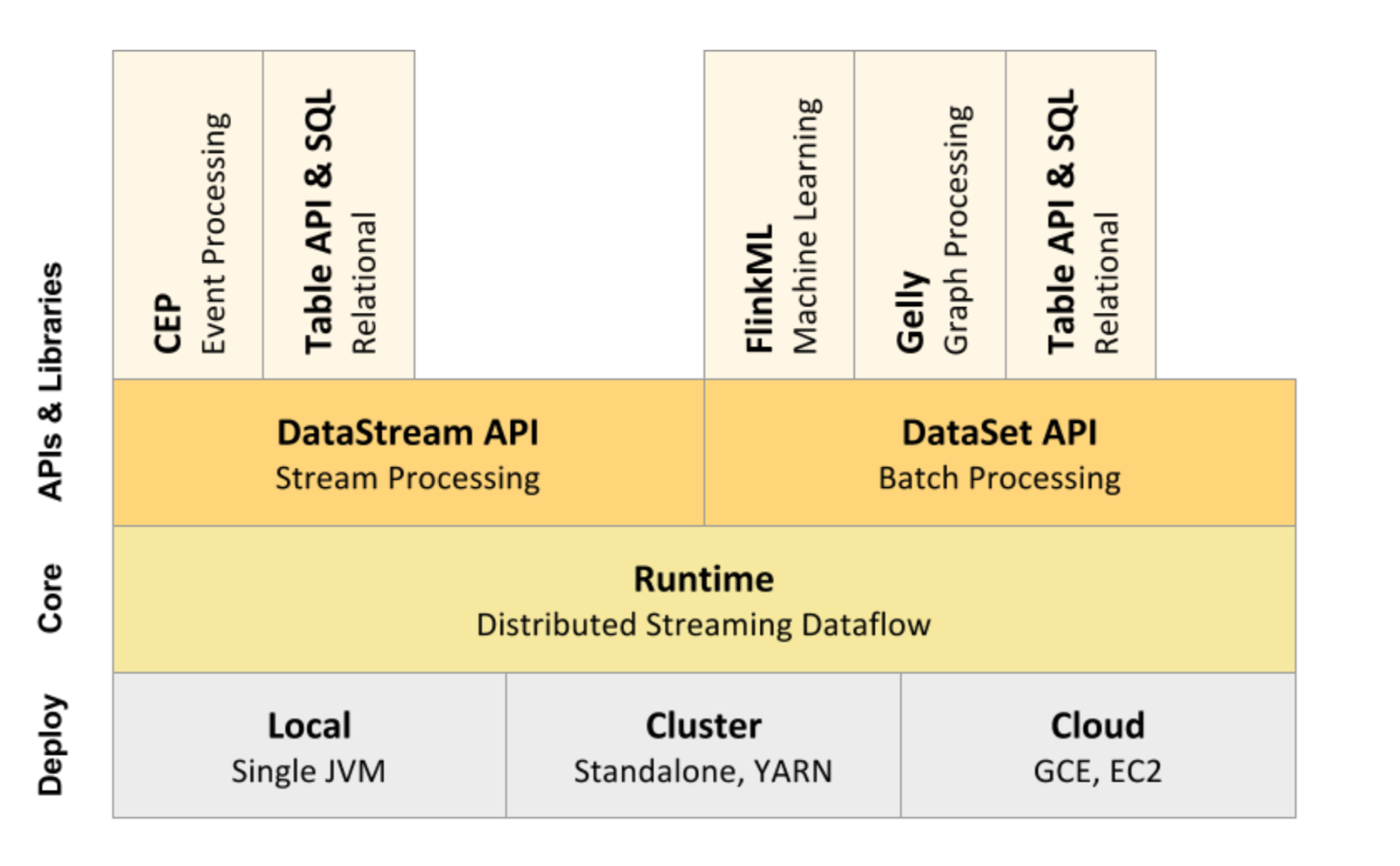
Flink特性
- 支持批处理和数据流程序处理
- 同时支持高吞吐量和低延迟
- 不同的时间语义(时间时间、摄取时间、处理时间)下支持灵活的窗口(时间、滑动、翻滚、会话、自定义触发器)
- 仅处理一次的容错担保
- 自动反压机制
- 支持CEP,如:反欺诈、风控规则引擎
- 与MapReduce/Storm接口兼容,允许重用其代码
- 集成YARN、HDFS、HBase和其他 Hadoop生态的组件
Flink与其他框架对比
| Record ACK | Micro-batching | Transactional updates | Distributed snapshots | |
|---|---|---|---|---|
| 典型代表 | Apache Storm | Storm Trident ,Spark Streaming | Google Cloud Dataflow | Apache Flink |
| 语义保证 | At least once | Exactly once | Exactly once | Exactly once |
| 延迟 | 低 | 高 | 较低(事物延迟) | 低 |
| 吞吐 | 低 | 高 | 较高(取决于事物存储吞吐) | 高 |
| 计算模型 | 流 | 微批 | 流 | 流 |
| 容错开销 | 高 | 低 | 较低(取决于事物存储吞吐) | 低 |
| 流量控制 | 较差 | 较差 | 好 | 好 |
| 业务灵活性(业务和容错分离) | 部分 | 紧耦合 | 分离 | 分离 |
部署方式
- Standalone
- Flink 运行在由一个 master 节点、一个或多个 worker 节点组成的集群上。
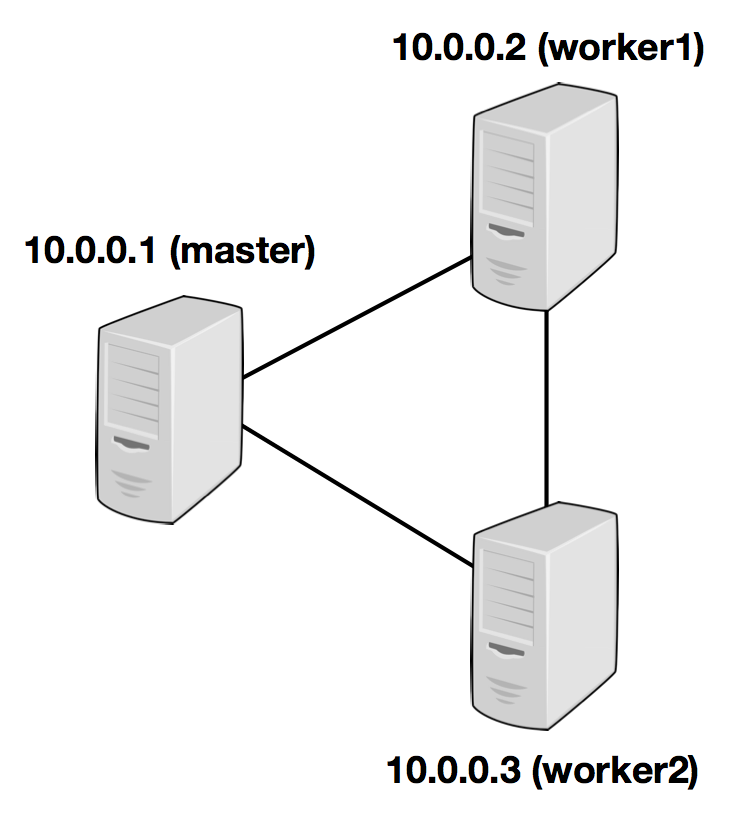
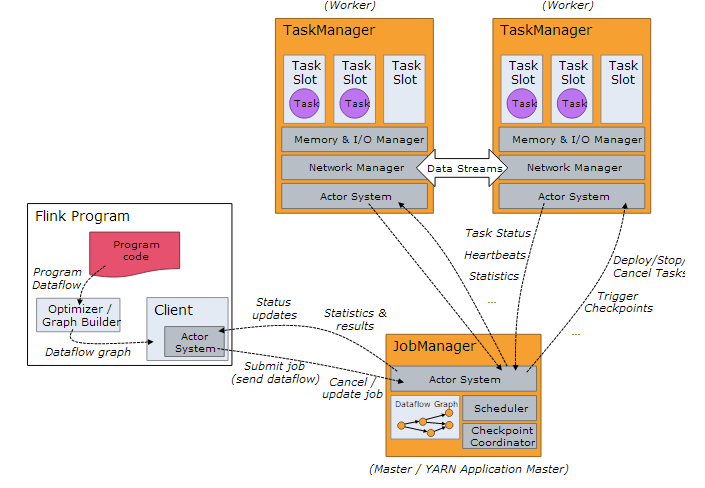
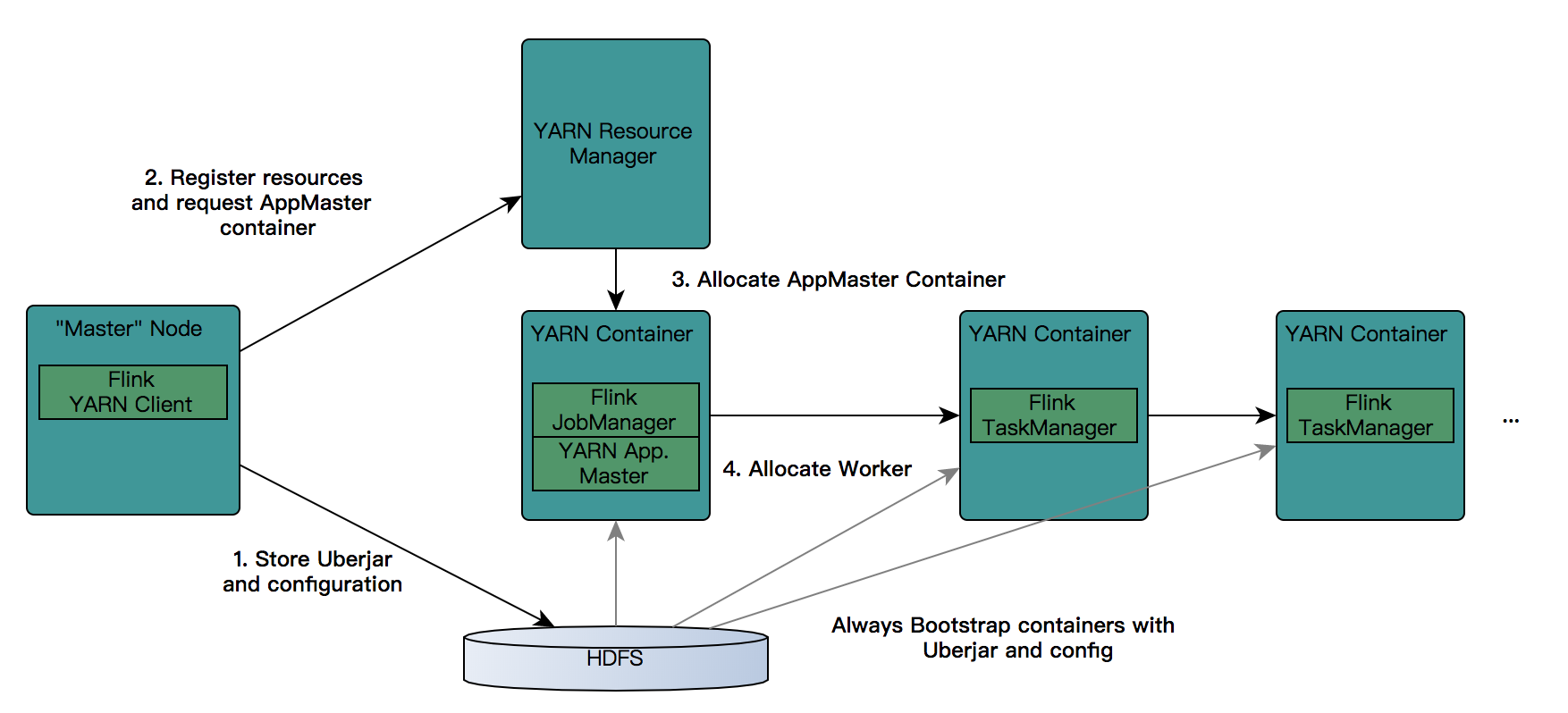
- Flink on YARN
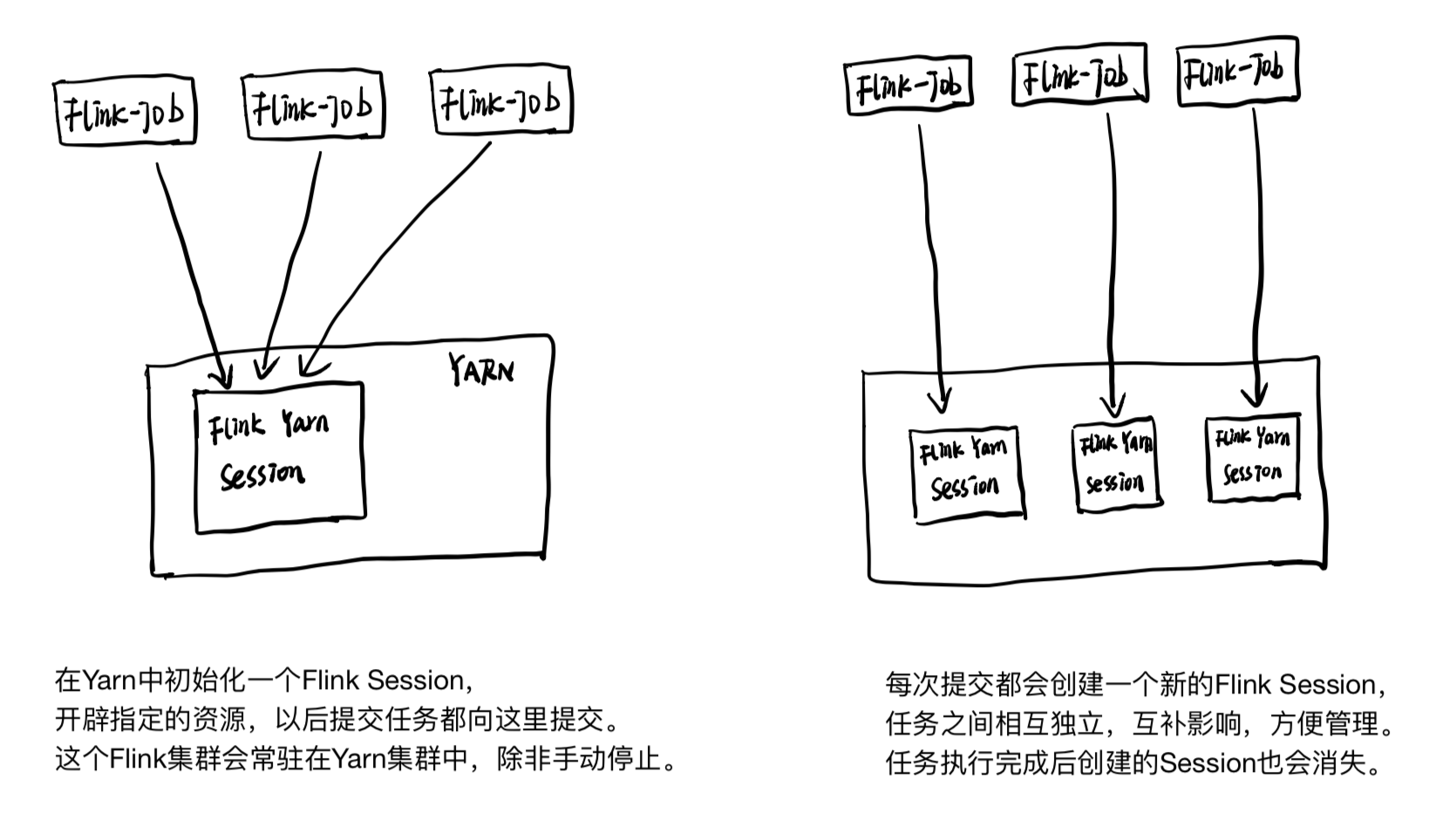
- 分离模式 (A long-running Flink cluster on YARN)
- 需要在Yarn中需要常驻进程,在启动时已经确定好了所分配的资源大小启动后会在Yarn中常驻一个Application,此Application为Flink的JobManager在Yarn中的常驻进程。
- JobManager可做容错处理,如果JobManager挂掉,那么Yarn会自动重启一个JobManager,不影响任务的提交。
- 不同Job会受到资源大小的影响,因为资源的分配是在启动时给定的,如果某个任务将给定资源占满,那么其他的任务需要等候资源释放后才能执行。
- 客户端模式 (A single Flink job on YARN)
- Flink只是作为一个客户端,不需要常驻Yarn进程。
- JobManager跟随Job的提交才启动。
- 每个Job资源隔离,不同的Job之间资源是独立的,Job的资源分配只受到Yarn资源策略的影响。
容错处理
-
Checkpoint -- Checkpoint使Fink的状态具有非常好的容错性,通过Checkpoint,Flink可以对作业的状态和计算位置进行恢复,因此Flink作业具备高容错执行语意。 -- 所谓Checkpoint,就是在某一时刻,将所有task的状态做一个快照(snapshot),然后存储到State Backend。 -- 轻量级容错机制 -- 通过Checkpoint来保证Exactly-once语义 -- 内部失败自动恢复,无需人工干预
-
Savepoint
- Savepoints是存储在外部文件系统的的自完备的checkpoints,可以用来停止-恢复或升级Flink程序。其使用Flink的checkpoint机制创建流作业的全量(非增量)状态快照,并且将checkpoint数据和元数据写出到外部文件系统。而且不会过期,不会被覆盖,除非手动删除。
- 流处理过程中的状态历史版本
- 具有可以replay的功能
- 外部恢复(应用重启和升级)
- 两种触发方式
- Cancel with Savepoint
- 手动主动触发
-
State Backend
- Checkpoint功能启用后,每次checkpoint时,状态都被持久化,从而避免数据丢失或用于一致性恢复。内部状态如何展示,基于Checkpoint的持久化状态如何存储,在哪里存储,取决于选择的状态后端。
- Flink开箱即用的集成了以下state backend系统:
- MemoryStateBackend(默认) : 将数据保存为Java Heap中的对象,基于HeapKeyedStateBackend,可能会造成OOM。
- FsStateBackend : 将数据保存到文件系统,如HDFS、Local File,基于HeapKeyedStateBackend,可能会造成OOM。
- RocksDBStateBackend : 使用RocksDB保存状态,RocksDB克服了HeapKeyedStateBackend受内存限制的缺点,同时又能够持久化到远端文件系统中,它会在本地文件系统中维护状态,KeyedStateBackend等会直接写入本地Rocksdb中,同时配置一个远端的FileSystem(如:HDFS),在做Checkpoint的时候,会把本地的数据直接复制到FileSystem中。fail over的时候从FileSystem中恢复到本地。
