

核心
- HDFS分布式文件系统:存储是大数据技术的基础
- MapReduce编程模型:分布式计算是大数据应用的解决方案
1. HDFS
概念:
- 数据块: 抽象块而非整个文件作为存储单元;一般设置为64BM,备份X3
- NameNode: 管理文件系统的命名空间,文件元数据;维护着文件系统的所有文件和目录,文件与数块的映射;记录每个文件中各个块所在数据节点的信息
- DataNode: 存储并检索数据块;向NameNode更新所存储块的列表
特点
- 普通的成百上千的机器
- 按TB甚至Pb为单位的大量的数据
- 简单编辑的文件获取
优点
- 适合大文件存储,支持TB、PB级别的数存储,并有副本策略
- 可以构建在廉价的机器上,并有一定的容错和恢复机制
- 支持流式数据访问,一次写入,多次读取最高效
缺点
- 不合适小量小文件存储
- 不适合并发写入,不支持文件随机修改
- 不支持随机读低延时的访问方式
写流程
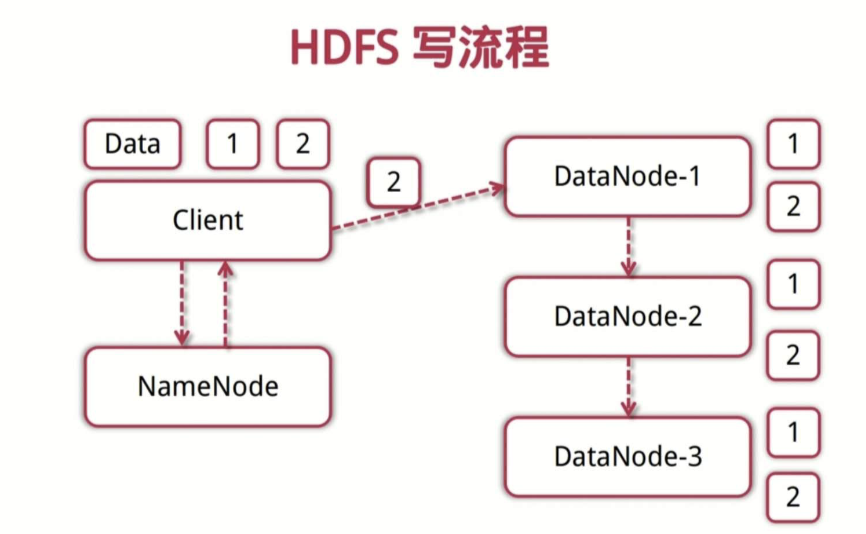
- 客户端向NameNode发起写请求
- 分块写入DataNode节点,DataNode自动完成副本备份
- DataNode向NameNode汇报存储完成,NameNode通知客户端
读流程
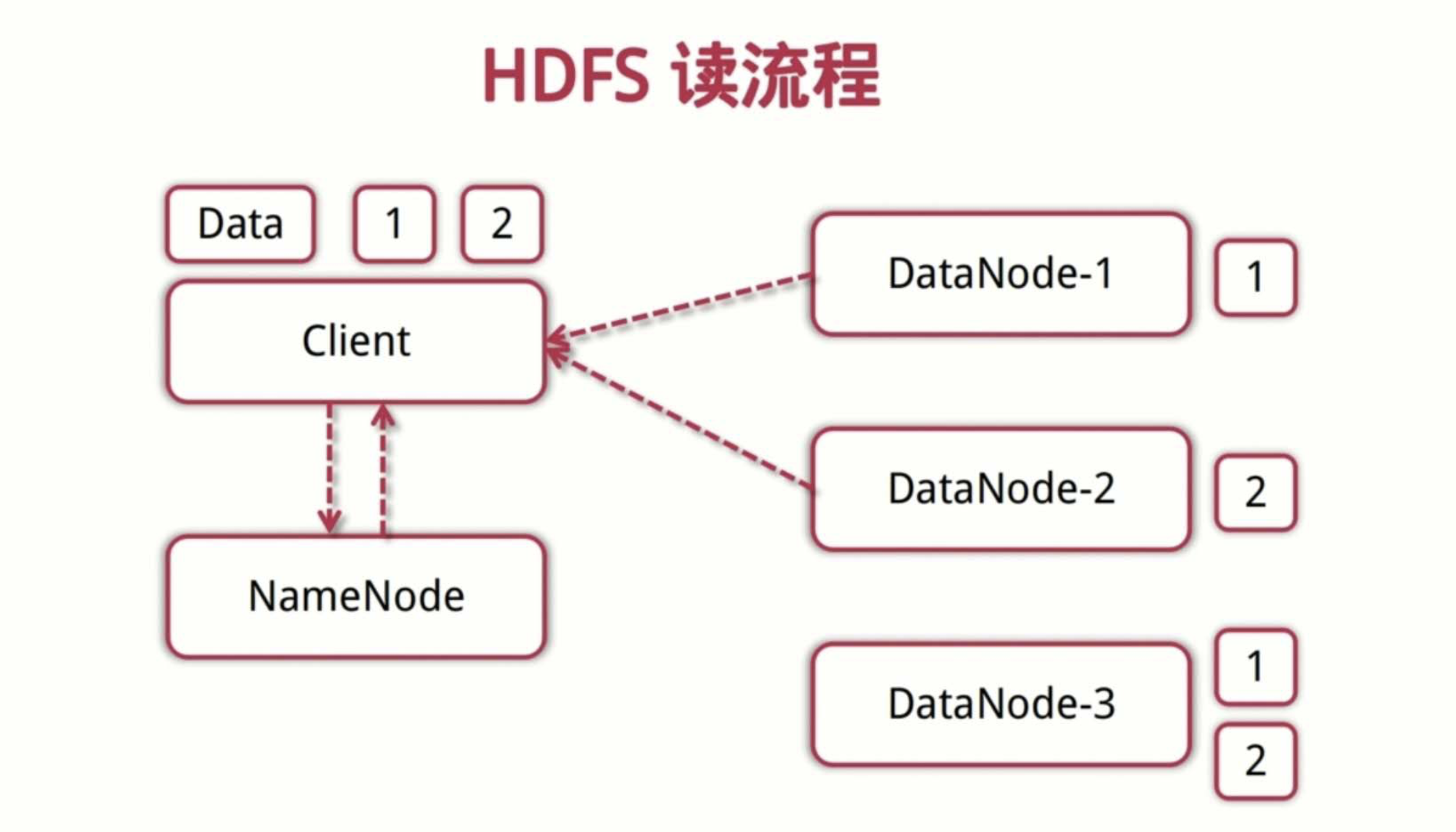
- 客户端向NameNode发起读数据请求
- NameNode找出距离最近的DataNode节点信息
- 客户端从DataNode分块下载文件
简单使用
- shell脚本
常见HDFS Shell命令
- 类linux命令:ls、cat、mkdir、rm、chmod、chown等
- HDFS文件交互:copyFromLocal、copyToLocal、get、put等
帮助命令:./hdfs dfs -help
2. MapReduce
MapReduce是-种编程模型,是-种编程方法,是抽象的理论
1. YARN
Hadoop2.0后,资源管理器,所有的mapReduce程序都需要通过yarn来调度,下面理解下其概念
- ResourceManager: 分配和调度资源;启动并监控ApplicationMaster;监控NodeManager
- ApplicationMaster:为MR类型的程序申请资源,并分配给内部任务;负责数据的切分;监控任务的执行及容错;
- NodeManager: 管理单个节点的资源;处理来着ResourceManager的命令;处理来自ApplicationMaster的命令
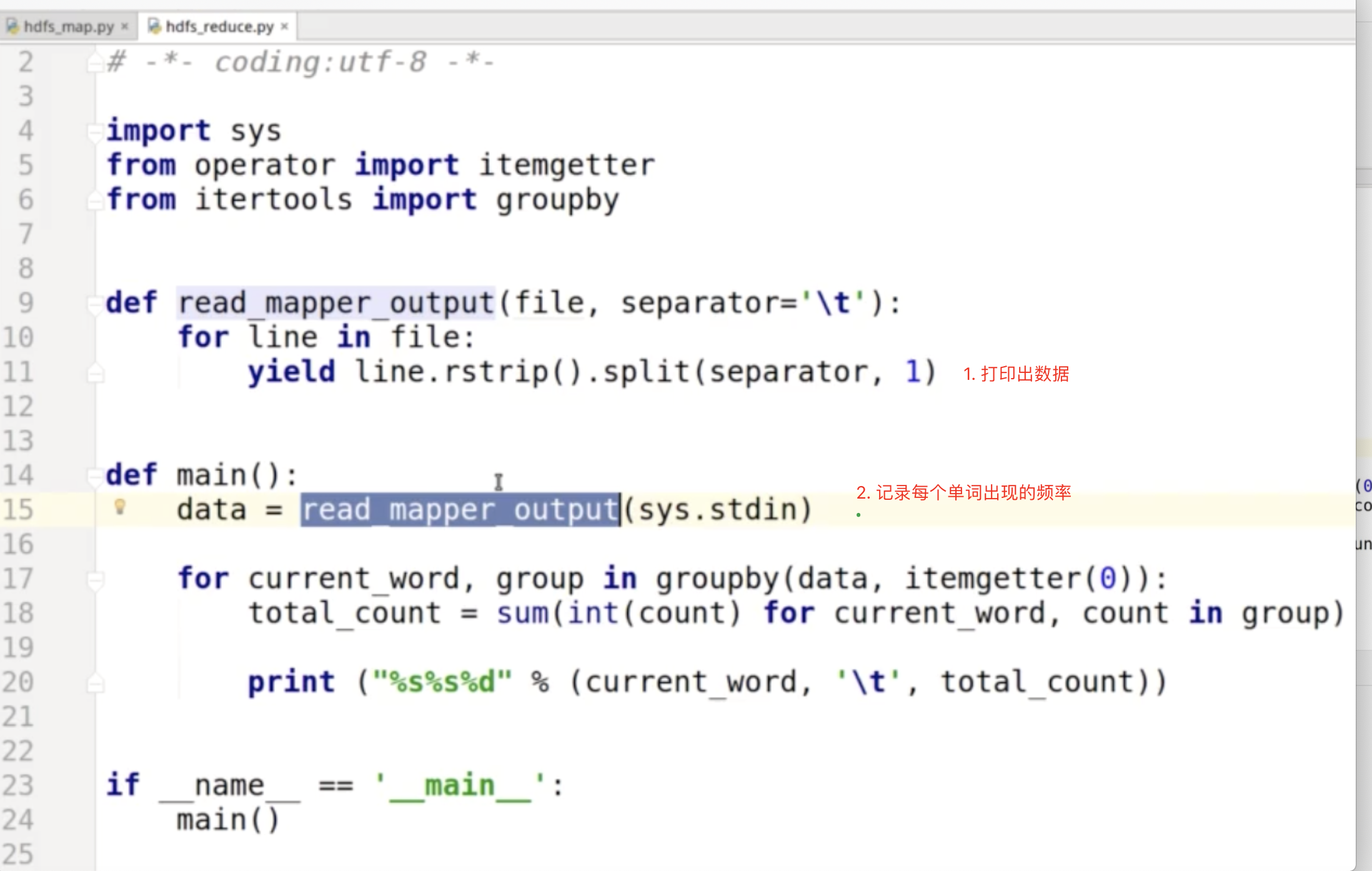
MapReduce编程模型
场景:输入一个大文件,通过Split之后,将其分为多个分片;每个文件分片由单独的机器去处理,这就是Map方法;将各个机器计算的结果进行汇总并得到最终的结果,这就是Reduce方法 简单示例:
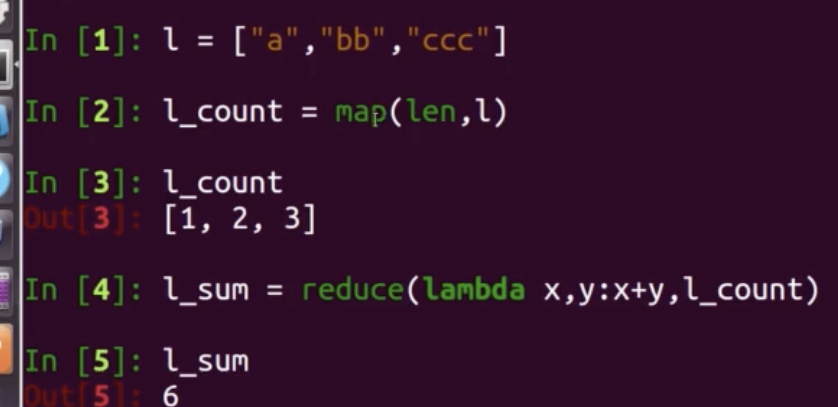
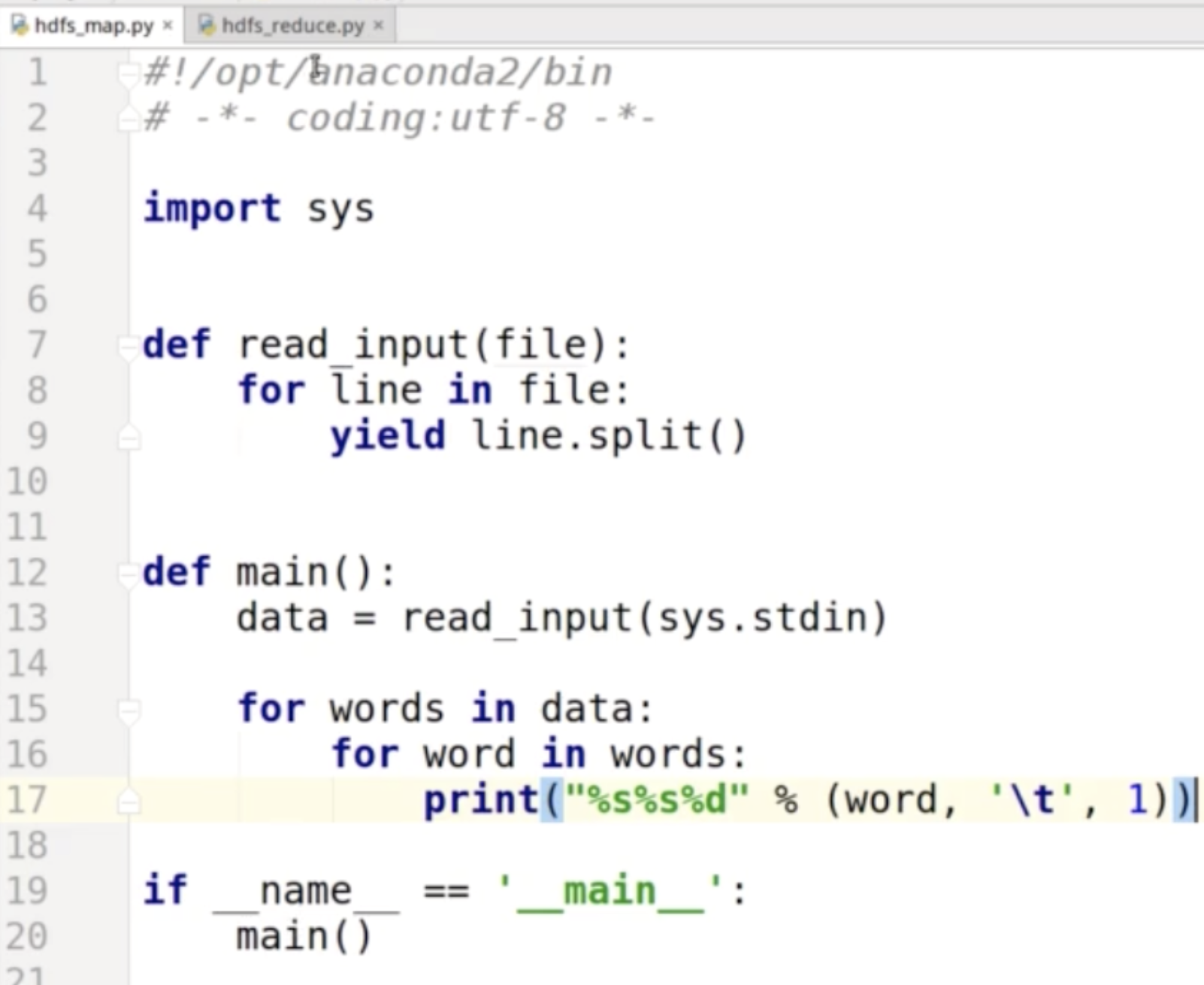
Hadoop生态
- HIve: 数据仓库,提供大量结构化数据 与 检索功能
- HBase:列式数据库
- Spark:基于内存分布式计算框架
- Sqoop: 传统数据库和Hadoop 之间导入导出的工具
- Ambari:Hadoop集群管理部署框架
Hbase
高可靠,高性能,面向列,可伸缩,实时读写的”分布式数据库“
利用HDFS作为其文件存储系统,支持MR程序读取数据
存储非结构化和半结构化数据

- RowKey:数据唯一标识,按字典排序
- Column Family: 列族,多个列的集合,最多不要超过3个
- TimeStamp时间戳:支持多版本数据同时存在
Spark
基于内存计算的分布式计算框架
抽象出分布式内存存储数据结构 弹性分布式数据集RDD
基于时间驱动,通过线程池提高性能
