

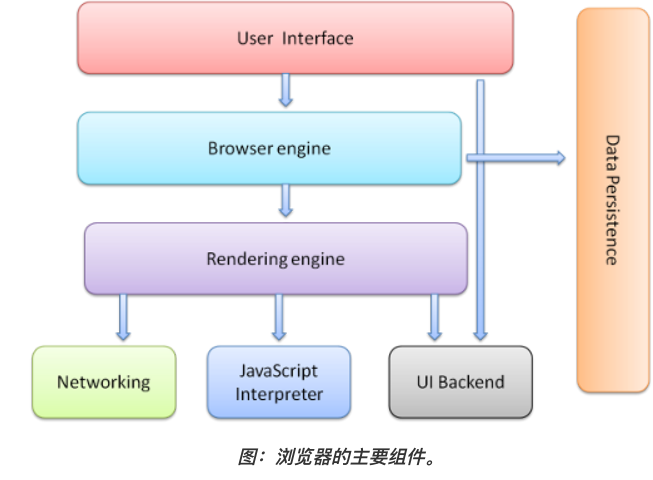
浏览器的主要组件
- 用户界面
- 浏览器引擎:再用户界面和呈现引擎之间传送指令
- 呈现/渲染引擎:负责显示请求的内容,如果内容是HTML就负责解析HTML和CSS,并将解析后的内容显示在屏幕上
- 网络
- 用户界面后端:用于绘制基本的窗口小部件,在底层使用操作系统的用户界面方法。
- JS解释器
- 数据存储:持久层,H5定义了网络数据库
呈现/渲染引擎
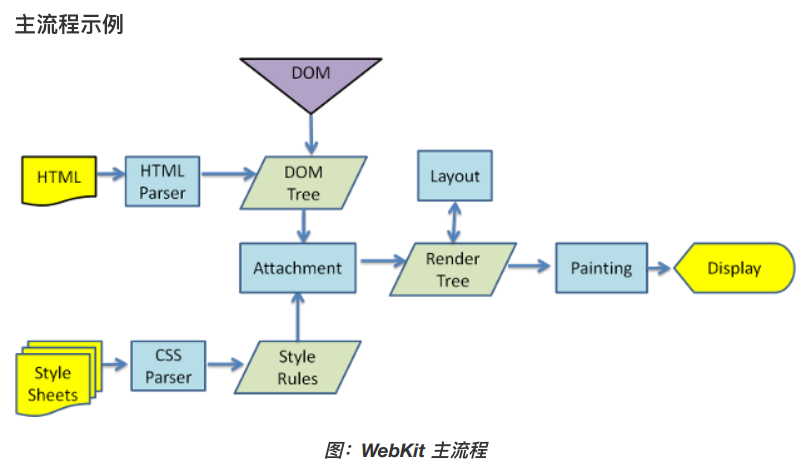
生成渲染树
主要功能就是现实使用CSS格式化的HTML内容和图片。渲染引擎接收通过HTTP协议传输的HTML和CSS文档,首先解析HTML文档,将个标记逐个转化成内容树上的DOM节点。同时也会解析外部CSS文件。HTML生成DOMtree,CSS生成CSSOMtree。 然后合并DOM,CSSOM生成渲染树。然后是layout布局阶段,为每个节点分配一个应该出现在屏幕上的确切坐标。 然后是paint绘制阶段,渲染引擎遍历渲染树,由用户后端界面将每个DOM绘制出来。 渲染的过程是异步的,一旦有数据进来,就会开始渲染以保证用户体验。
解析渲染树
HTML/CSS的解析过程包括词法分析和语法分析。词法分析将输入的文档划分成一个个标记,而语法分析则迭代地输入这些标记直到输入的标记可以匹配一个完整的语法。否则将引发错误。
翻译机器代码
解析的最后一步是将解析树翻译成机器代码,这一步由编译器执行
解析器类型
有自上而下解析器和自下而上解析器。自上而下解析器首先从高层规则开始解析,而自下而上解析器又称移位规约解析器,逐步匹配以满足语法规则。但是HTML无法通过常规的自上而下,自下而上解析器进行解析,因为HTML语法特别宽松,可以允许一些隐式的写法;浏览器对一些场景无效HTML用法采取包容态度;HTML可能被document.write更改
解析算法
标记化
是一个状态机。当接收第一个<时进入Tag Open表达打开状态,当接收到任意一个a-z字符进入Tag name标记名词状态,每新读入一个字母都会把这个字母添加到标记中。当遇到>时发送标记,然后进入数据状态。
在数据状态中,每读一个字母发送一次标记,和Tag name阶段不同。 从Data阶段读入一个<变又进入Tag Open状态,但是这时根据状态要期待下一个是\,进入Close tag open状态,然后发送一个end tag open。
进入Tag name标记名称状态。直到>被读入,发送tag name进入数据状态。
大部分时候是在数据状态,每接收一个字符发送一次tag
树构建
在创建解析器的同时,document对象被创建。随着标记化算法的进行,一个个标记被发送,树构建算法不断往document中添加子树。
此时可以将状态视为 插入模式
initial mode初始状态直到收到HTML标记,进入before html modebefore html mode此模式下创建HTMLHtmlElement元素,然后进入before head mode- 如果没有设置HEAD标记,会创建一个隐式的HEAD标记,然后创建HTMLHeadElement,进入
after head mode。如果有HEAD标记则中间会有一个in head mode in body mode接收BODY标记,正式处理htmlafter body->>after after body
再完成以上过程后开始解析处于 defer模式的JS脚本。然后文档将设置为完成,一个加载事件触发。
